
Table of Contents
YouTube Video Recommendation Systems
In this tutorial, you will learn about YouTube video recommendation systems.

YouTube is the world’s largest platform to create, consume, and share video content. Their recommendations (Figure 1) help billions of users discover personalized content from an ever-growing corpus of videos. According to Cristos Goodrow (VP of Engineering at YouTube), recommendations drive a significant amount of the overall viewership on YouTube, even more than channel subscriptions or searches.

So, how do their recommendations actually work? In this lesson, we will answer this question by explaining the machine learning behind YouTube video recommendations.
This lesson is the 2nd in a 3-part series on Deep Dive into Popular Recommendation Engines 102:
- Amazon Product Recommendation Systems
- YouTube Video Recommendation Systems (this tutorial)
- Spotify Music Recommendation Systems
To learn how YouTube recommender systems work, just keep reading.
YouTube Video Recommendation Systems
We will start with a system overview of the YouTube recommendation algorithm and then dive into individual components later.
Overview
The YouTube recommendation algorithm is extremely challenging because of three main reasons:
- Scale: The platform serves billions of users with billions of videos. Highly specialized distributed learning algorithms and efficient serving mechanisms are required to process and serve such massive information in the user base and video corpus.
- Freshness: Videos are uploaded every second on the YouTube platform, and user behavior can also change frequently. Hence, the recommendation algorithm should be responsive enough to provide new updates based on the latest videos and user actions. The algorithm should also maintain a balance between new content and well-established videos.
- Noise: The metadata associated with the content doesn’t have a well-defined ontology. Further, the user satisfaction signals are implicit most of the time (e.g., watch time), which can also be affected due to external factors. For example, during a cricket season (external factor), users might feel more engaged with match-related videos.
To address all these challenges, YouTube employs a two-stage deep learning-based recommendation strategy that trains large-scale models (with approximately one billion parameters) on hundreds of billions of examples. The overall system (Figure 2) consists of two neural networks for candidate generation and ranking.

The candidate generation network aims to filter out a few thousand video candidates from the vast corpus based on user watch history and context. These candidates are generally relevant to the user with high precision. This network uses coarse features like IDs of video watches, demographics, and search query tokens to generate relevant candidates.
On the other hand, the ranking network distinguishes between candidates and assigns them a rank according to their relevance to the user with a high recall. This model uses a rich set of features to assign the relevance score between a candidate video and the user.
We will now describe candidate generation and ranking in further detail.
Candidate Generation Network
Given a user  and context
and context  , the candidate generation network solves a multi-classification problem where the prediction problem accurately classifies a video watch
, the candidate generation network solves a multi-classification problem where the prediction problem accurately classifies a video watch  (at time
(at time  ) from millions of videos in corpus
) from millions of videos in corpus  . In other words,
. In other words,
 = \displaystyle\frac{\exp({v_i \cdot u})}{\sum_{j \in V} \exp({v_j \cdot u})},")
where  is a high-dimensional embedding representing user history and context.
is a high-dimensional embedding representing user history and context.  represents the embedding of video
represents the embedding of video  . The candidate generation network aims to learn the dense user embeddings
. The candidate generation network aims to learn the dense user embeddings  as a function of user history and context so that it helps discriminate videos via a softmax classifier. Note that the video embeddings are pre-learned in a fixed vocabulary via continuous bag-of-words language models.
as a function of user history and context so that it helps discriminate videos via a softmax classifier. Note that the video embeddings are pre-learned in a fixed vocabulary via continuous bag-of-words language models.
Architecture and Feature Representation
As shown in Figure 3, the candidate generation network comprises several features (e.g., user watch history, search query, demographics, user gender, example age, etc.). All these features are concatenated and fed to a feed-forward network comprising fully connected layers and ReLU activation.
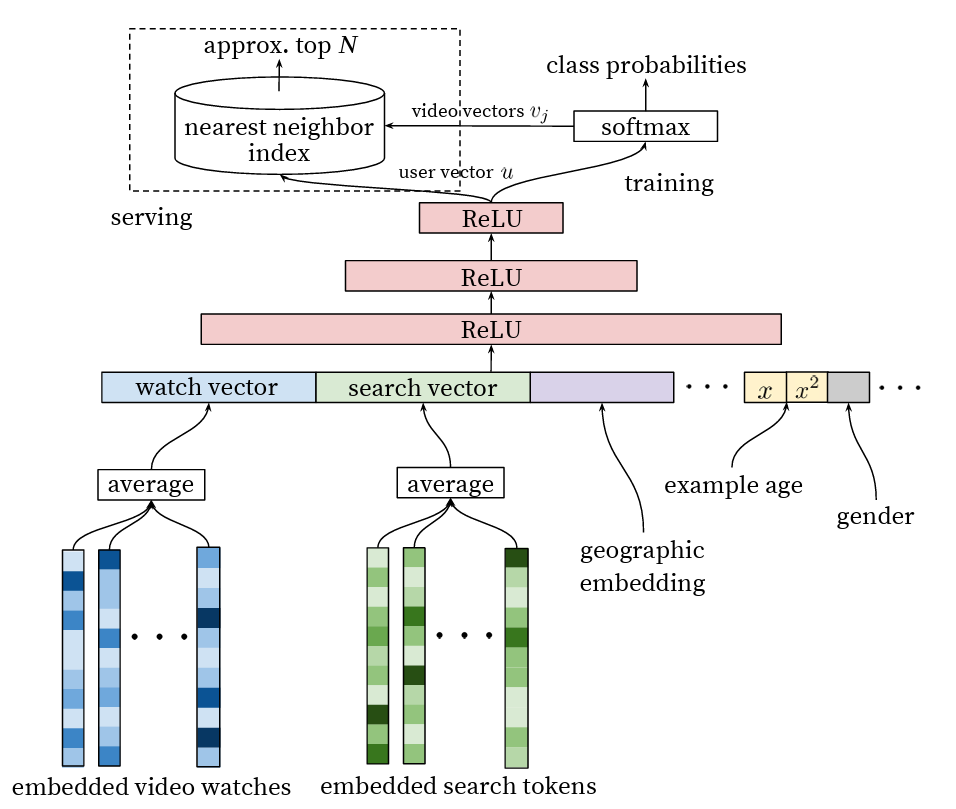
The user watch history is represented as a variable-length sequence of sparse video IDs (watched by the user recently) mapped to their dense embeddings . These dense embeddings (of videos watched by the user) are then averaged to represent the user watch vector fed into a feed-forward network. Note that the video embeddings are learned jointly with other model parameters.
Like the user watch vector, the search query is also tokenized into unigrams and bigrams, and each token is mapped to its respective token embedding. The embeddings of all tokens are then averaged to obtain a user search vector.
The user’s geographic location and device ID are embedded and concatenated to represent demographics. Further, the binary and continuous features (e.g., user gender, logged-in state, and age) are fed directly after being normalized to ![[0, 1]](https://b2633864.assetcdn.net/2633864/wp-content/latex/264/264884439b70ab09a86bc848421c6de6-ffffff-000000-0.png?size=30x18&lossy=2&strip=1&webp=1 "[0, 1]") .
.
The distribution of video popularity is highly non-stationary (i.e., it lasts for a few days, slows down, and then converges). Still, the above candidate recommendation network will only recommend based on the average watch likelihood of a video (but not its popularity). To address this, a unique “Example Age” feature is also given as input during training.
“Example Age” represents the age of the training example used. During inference, it is set to zero or negative to ensure that the model predictions don’t get biased toward the past, and it assigns more likelihood to a new video. Figure 4 shows that adding “Example Age” as a feature increases the probability of a recently uploaded video (as opposed to a baseline model) and is close to its empirical value.

Training
To train the network, YouTube leverages implicit feedback signals where a user completing a video is considered a positive example. This is because explicit feedback signals like thumbs up and down in-product surveys are quite rare.
Further, training examples are generated from all YouTube watches (even those embedded on other sites) rather than watches from the recommendations. This ensures that feedback signals contain information about users discovering videos through means other than recommendations. This way, the recommender would not be biased toward exploitation.
Now, given a watch history of a user  and corresponding search history
and corresponding search history  , there are two ways of training the candidate generation network:
, there are two ways of training the candidate generation network:
- Predicting Held-Out Watch (Figure 5): In this setting, you predict a randomly held-out look, e.g.,
 given past and future search queries
given past and future search queries  and watch history
and watch history  as inputs to network. However, this leaks future information and ignores asymmetric consumption patterns (e.g., you will likely watch episode 2 of the series only after episode 1 but not vice versa).
as inputs to network. However, this leaks future information and ignores asymmetric consumption patterns (e.g., you will likely watch episode 2 of the series only after episode 1 but not vice versa).
 given past and future search queries
given past and future search queries  and watch history
and watch history  as inputs to network. However, this leaks future information and ignores asymmetric consumption patterns (e.g., you will likely watch episode 2 of the series only after episode 1 but not vice versa).
as inputs to network. However, this leaks future information and ignores asymmetric consumption patterns (e.g., you will likely watch episode 2 of the series only after episode 1 but not vice versa). 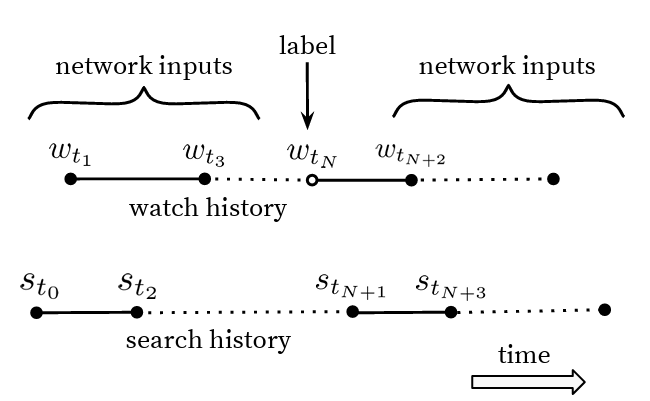
- Predicting Future Watch (Figure 6): This setting involves predicting future watches given past search queries and watch history. Since the YouTube recommendation problem is posed as predicting the next watched video, this setting is more appropriate for training neural networks.

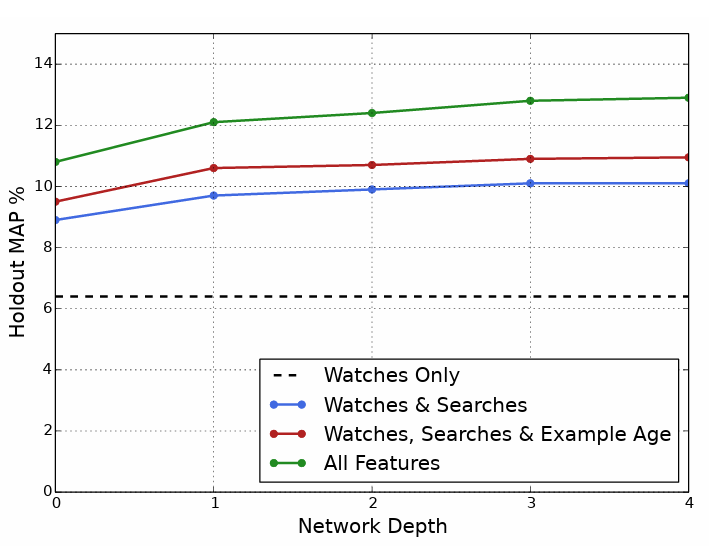
Figure 7 shows the performance of the candidate generation network when different sets of features are given input to the network and network depth is varied. The performance is measured via holdout mean average precision (MAP), which measures how accurately the models predict held-out watches. The network achieves the best performance using all features (watch history, search history, example age, demographics). Further, the performance improves monotonically with an increase in the network depth.
Ranking Network
The goal of the ranking network is to take the video candidates from the candidate generation network and rank them in decreasing order of their relevance to the user. A user might watch a particular video with a high probability, but because the thumbnail image is not appealing, the user never clicks it.
Hence, the ranking network takes in many more features describing the video (e.g., video thumbnail, video content, etc.) and the user’s relationship to the video to assign a relevance score. The network uses both categorical and continuous features. Categorial features can be binary (e.g., whether the user is logged in?) or have millions of values (e.g., the user’s last search query).
Feature Selection
Continuous features describe a user’s past interaction with similar videos. For example, while scoring a video uploaded by channel X, it is important to consider how many videos a user has watched from channel X? Or when was the last time the user watched a similar video.
Other continuous features include signals from the candidate generation network. For example, what score was assigned by the candidate generation network? Or which sources are nominating the video candidate?
Further, features describing the frequency of past video impressions are also critical so that successive requests return different recommendations. If a user recently recommended a video but did not watch it, the model should reduce its relevance score.
Architecture
Figure 8 describes the overall architecture of the ranking network.
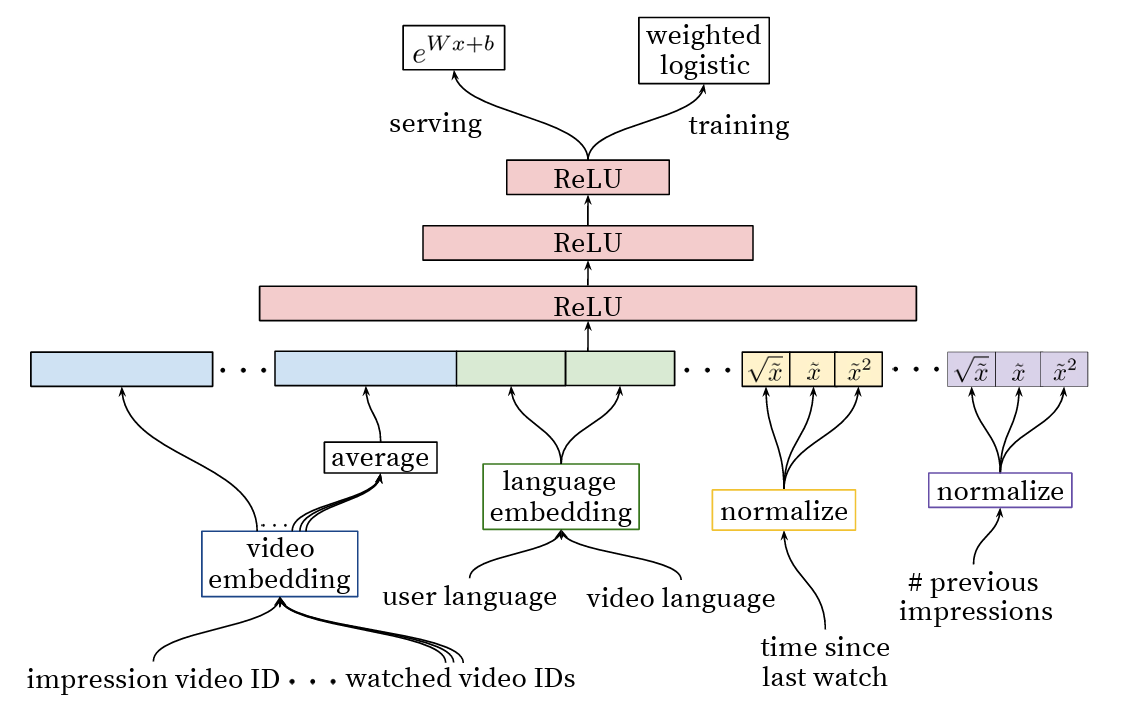
Like the candidate generation network, the video IDs are mapped to their respective fixed-sized embeddings, which are learned along with the network parameters. The network takes the embedding of candidate videos, the average embedding of watched videos, and user and video language embeddings as inputs.
For continuous features like “time since last watch” and “# previous impressions,” we first normalize the values such that the feature is equally distributed in the range ") . In Figure 9,
. In Figure 9,  represents the normalized feature. We also provide powers of normalized features such as
represents the normalized feature. We also provide powers of normalized features such as  ,
,  as inputs to give the network more expressive power by allowing it to form super- and sub-linear functions of the feature easily.
as inputs to give the network more expressive power by allowing it to form super- and sub-linear functions of the feature easily.
The networks take all these features (in reality, more than we described) and pass them through a fully connected network to predict the expected watch time via weighted logistic regression. In weighted logistic regression, the positive (clicked) impressions are weighted by the observed watch time on the video. Negative (unclicked) impressions all receive unit weight.
Toward Multi-Task Ranking System
Multi-Task Learning
In the approach described above, the main objective of the ranking system was to improve the likelihood of a video being watched or clicked. However, in reality, the task of recommending videos is multi-objective. For example, we may want to recommend videos that users rate highly and share with their friends in addition to watching.
Further, the system often has implicit bias where the user might have clicked or watched a video simply because it was ranked high and not because the user liked it. This will further get amplified via feedback loops as such videos will be considered positive examples while updating the network.
Objectives can be categorized into two categories:
- Engagement level objectives include clicks, watches, intensity of watch, etc.
- Satisfaction objectives include liking a video, leaving a rating, sharing, etc.
Multi-Gate Mixture of Experts
To model these multiple objectives, YouTube leverages a Multi-Gate Mixture of Experts (MMoE) to learn parameters to share across potentially conflicting objectives. The mixture of experts is a popular machine-learning technique that uses multiple expert networks.
It modularizes the input layer into several experts, each focusing on different input aspects. This improves the representation of learning. Then, by utilizing multiple gating networks, each objective can choose experts to share or not share with others.
YouTube models engagement level objectives via two types of tasks:
- binary classification task for predicting the user click probability
- regression task to predict time spent on a video
Similarly, satisfaction level objectives can be modeled via binary classification tasks (e.g., predicting user likes and shares) and regression tasks (predicting ratings).
As shown in Figure 9, for each video candidate and query (can be a video or search query), the model takes their embeddings as inputs along with user and context features. Then, scores from these multiple objective tasks (engagement and satisfaction) are obtained using MMoE. These scores are then combined into a single score using weighted multiplication (weights are manually tuned to achieve the best performance) during serving.

MMoE is a soft parameter-sharing model structure with expert networks shared across all tasks but gating networks trained for each task. As shown in Figure 10, multiple experts are added on top of a shared bottom layer. This way, MoE can learn modularized information from the input. The implementation of expert networks is similar to multi-layer perceptrons with ReLU activations.
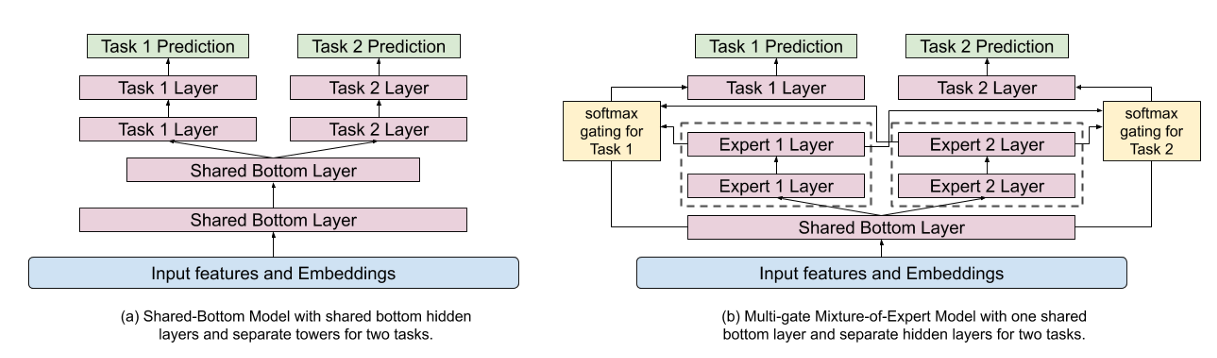
Given a task  , the prediction
, the prediction  of the MMoE (with
of the MMoE (with  expert networks) is given as follows:
expert networks) is given as follows:
 = \sum_{i=1}^m g^k_i(x) \cdot f_i(x)")
),")
where ") is the
is the  th expert network,
th expert network,  \in \Re^m") is the gating network for task , and
is the gating network for task , and ") is the final prediction layer for task .
is the final prediction layer for task .
The gating networks are simple linear transformations of the input with the softmax layer
 = \text{softmax}(W^k \cdot x),")
where  are the parameters of the gating network.
are the parameters of the gating network.
Table 1 reports the improvement in engagement and satisfaction level metrics when the number of experts in MMoE architecture varies.

Learning Selection Bias
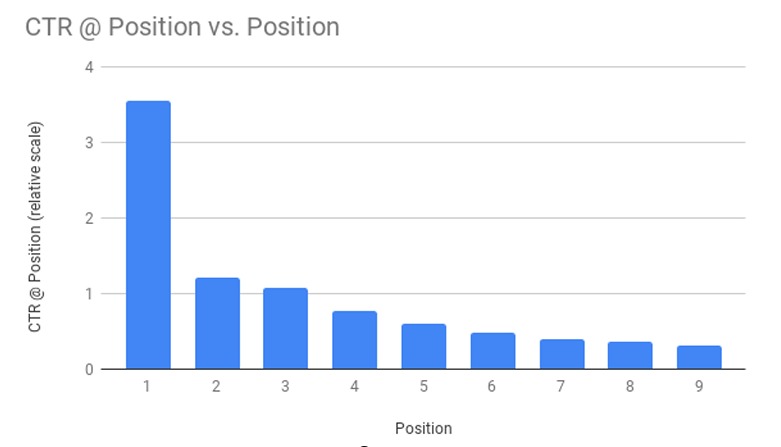
In case you have not noticed, Figure 9 shows another component called a “shallow tower.” The role of this shallow tower is to mitigate positional bias in the ranked items. In a ranking system, it is common for the users to click the videos that are on the top, even if they are irrelevant to the user and the given context (search query or video being watched currently). This is referred to as position bias.
Figure 11 illustrates the distribution of CTR (click-through rate) for positions 1 to 9. The CTR represents the probability of an item being clicked by the user (i.e., an engagement level metric). As can be seen, the CTR is significantly higher for top positions because of position bias.
To remove this position bias, YouTube factorizes the model prediction into two components: the user utility component from the main ranking network (that uses MMoE) and the position bias components. This is illustrated in Figure 12.

More specifically, a shallow tower or network is trained with features contributing to position bias to output a position bias logit. This position bias logit is then added with the logit from the main ranking network. During training, the positions of all candidate videos are used with a 10% feature drop to prevent the model from over-relying on the position bias of the video.
This feature is treated as missing during serving time, and the ranking is done based on the scores from the main ranking network.
What's next? We recommend PyImageSearch University.
120+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: August 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 120+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 94+ Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
This lesson discussed how YouTube video recommendations work behind the scenes. YouTube video recommendation is challenging because of a vast corpus of users and videos dynamically updated every few seconds. Hence, YouTube leverages a two-tier recommendation system consisting of a candidate generation network and a ranking network.
The candidate generation network aims to select a few thousand video candidates from the vast corpus of videos relevant to the user and the current context. These candidates are generally relevant to the user with high precision. The candidate generation network comprises several features like user watch history, search query, demographics, user gender, example age, etc. All these features are concatenated and fed to a feed-forward network comprising fully connected layers and ReLU activation.
To train the network, YouTube leverages implicit feedback signals where a user completing a video is considered a positive example. The training involves predicting future viewings given past search queries and watch history.
On the other hand, the ranking network distinguishes candidates and assigns them a rank according to their relevance to the user with a high recall. This model uses a rich set of features describing the video (e.g., video thumbnail, video content, etc.) and the user’s relationship to the video to assign the relevance score between a candidate video and the user.
The main objective of the ranking system here is to improve the likelihood of a video being watched or clicked. However, in reality, the task of recommending videos is multi-objective. For example, engagement level objectives include clicks, watches, the intensity of watching, etc., and satisfaction objectives include liking a video, leaving a rating, sharing, etc.
To model these multiple objectives, YouTube leverages a Multi-Gate Mixture of Experts (MMoE) to learn parameters to share across potentially conflicting objectives. The mixture of experts is a popular machine-learning technique that uses multiple expert networks.
This is just the tip of the iceberg, as there is much more to YouTube recommendation systems. Stay tuned for the last lesson of this series, where we will discuss Spotify music recommendation systems.
Citation Information
Mangla, P. “YouTube Video Recommendation Systems,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, and R. Raha, eds., 2023, https://pyimg.co/rvdym
@incollection{Mangla_2023_YouTube,
author = {Puneet Mangla},
title = {{YouTube} Video Recommendation Systems},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha},
year = {2023},
note = {https://pyimg.co/rvdym},
}

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.