In this tutorial, you will learn how to utilize YOLO and Tiny-YOLO for near real-time object detection on the Raspberry Pi with a Movidius NCS.
The YOLO object detector is often cited as being one of the fastest deep learning-based object detectors, achieving a higher FPS rate than computationally expensive two-stage detectors (ex. Faster R-CNN) and some single-stage detectors (ex. RetinaNet and some, but not all, variations of SSDs).
However, even with all that speed, YOLO is still not fast enough to run on embedded devices such as the Raspberry Pi — even with the aid of the Movidius NCS.
To help make YOLO even faster, Redmon et al. (the creators of YOLO), defined a variation of the YOLO architecture called Tiny-YOLO.
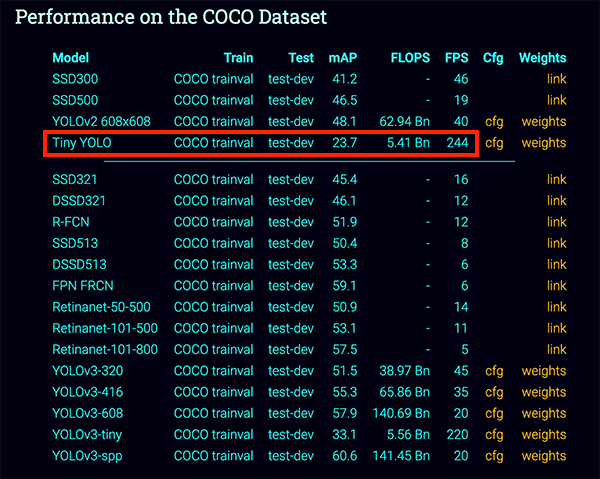
The Tiny-YOLO architecture is approximately 442% faster than it’s larger big brothers, achieving upwards of 244 FPS on a single GPU.
The small model size (< 50MB) and fast inference speed make the Tiny-YOLO object detector naturally suited for embedded computer vision/deep learning devices such as the Raspberry Pi, Google Coral, and NVIDIA Jetson Nano.
Today you’ll learn how to take Tiny-YOLO and then deploy it to the Raspberry Pi using a Movidius NCS to obtain near real-time object detection.
To learn how to utilize YOLO and TinyYOLO for object detection on the Raspberry Pi with the Movidius NCS, just keep reading!
YOLO and Tiny-YOLO object detection on the Raspberry Pi and Movidius NCS
In the first part of this tutorial, we’ll learn about the YOLO and Tiny-YOLO object detectors.
From there, I’ll show you how to configure your Raspberry Pi and OpenVINO development environment so that they can utilize Tiny-YOLO.
We’ll then review our directory structure for the project, including a shell script required to properly access your OpenVINO environment.
Once we understand our project structure, we’ll move on to implementing a Python script that:
- Accesses our OpenVINO environment.
- Reads frames from a video stream.
- Performs near real-time object detection using a Raspberry Pi, Movidius NCS, and Tiny-YOLO.
We’ll wrap up the tutorial by examining the results of our script.
What are YOLO and Tiny-YOLO?
Tiny-YOLO is a variation of the “You Only Look Once” (YOLO) object detector proposed by Redmon et al. in their 2016 paper, You Only Look Once: Unified, Real-Time Object Detection.
YOLO was created to help improve the speed of slower two-stage object detectors, such as Faster R-CNN.
While R-CNNs are accurate they are quite slow, even when running on a GPU.
On the contrary, single-stage detectors such as YOLO are quite fast, obtaining super real-time performance on a GPU.
The downside, of course, is that YOLO tends to be less accurate (and in my experience, much harder to train than SSDs or RetinaNet).
Since Tiny-YOLO is a smaller version than its big brothers, this also means that Tiny-YOLO is unfortunately even less accurate.
For reference, Redmon et al. report ~51-57% mAP for YOLO on the COCO benchmark dataset while Tiny-YOLO is only 23.7% mAP — less than half of the accuracy of its bigger brothers.
That said, 23% mAP is still reasonable enough for some applications.
My general advice when using YOLO is to “simply give it a try”:
- In some cases, it may work perfectly fine for your project.
- And in others, you may seek more accurate detectors (Faster R-CNN, SSDs, RetinaNet, etc.).
To learn more about YOLO, Tiny-YOLO, and other YOLO variants, be sure to refer to Redmon et al.’s 2018 publication.
Configuring your Raspberry Pi + OpenVINO environment

This tutorial requires a Raspberry Pi 4B and Movidius NCS2 (the NCS1 is not supported) in order to replicate my results.
Configuring your Raspberry Pi with the Intel Movidius NCS for this project is admittedly challenging.
I suggest you (1) pick up a copy of Raspberry Pi for Computer Vision, and (2) flash the included pre-configured .img to your microSD. The .img that comes included with the book is worth its weight in gold as it will save you countless hours of toiling and frustration.
For the stubborn few who wish to configure their Raspberry Pi + OpenVINO on their own, here is a brief guide:
- Head to my BusterOS install guide and follow all instructions to create an environment named
cv. - Follow my OpenVINO installation guide and create a 2nd environment named
openvino. Be sure to download OpenVINO 4.1.1 (4.1.2 has unresolved issues).
You will need a package called JSON-Minify to parse our JSON configuration. You may install it into your virtual environment:
$ pip install json_minify
At this point, your RPi will have both a normal OpenCV environment as well as an OpenVINO-OpenCV environment. You will use the openvino environment for this tutorial.
Now, simply plug in your NCS2 into a blue USB 3.0 port (the RPi 4B has USB 3.0 for maximum speed) and start your environment using either of the following methods:
Option A: Use the shell script on my Pre-configured Raspbian .img (the same shell script is described in the “Recommended: Create a shell script for starting your OpenVINO environment” section of my OpenVINO installation guide).
From here on, you can activate your OpenVINO environment with one simple command (as opposed to two commands like in the previous step:
$ source ~/start_openvino.sh Starting Python 3.7 with OpenCV-OpenVINO 4.1.1 bindings...
Option B: One-two punch method.
If you don’t mind executing two commands instead of one, you can open a terminal and perform the following:
$ workon openvino $ source ~/openvino/bin/setupvars.sh
The first command activates our OpenVINO virtual environment. The second command sets up the Movidius NCS with OpenVINO (and is very important, otherwise your script will error out).
Both Option A and Option B assume that you either are using my Pre-configured Raspbian .img or that you followed my OpenVINO installation guide and installed OpenVINO 4.1.1 on your own.
Caveats:
- Some versions of OpenVINO struggle to read .mp4 videos. This is a known bug that PyImageSearch has reported to the Intel team. Our preconfigured .img includes a fix. Abhishek Thanki edited the source code and compiled OpenVINO from source. This blog post is long enough as is, so I cannot include the compile-from-source instructions. If you encounter this issue please encourage Intel to fix the problem, and either (A) compile from source using our customer portal instructions, or (B) pick up a copy of Raspberry Pi for Computer Vision and use the pre-configured .img.
- The NCS1 does not support the TinyYOLO model provided with this tutorial. This is atypical — usually, the NCS2 and NCS1 are very compatible (with the NCS2 being faster).
- We will add to this list if we discover other caveats.
Project Structure
Go ahead and grab today’s downloadable .zip from the “Downloads” section of today’s tutorial. Let’s inspect our project structure directly in the terminal with the tree command:
$ tree --dirsfirst . ├── config │ └── config.json ├── intel │ ├── __init__.py │ ├── tinyyolo.py │ └── yoloparams.py ├── pyimagesearch │ ├── utils │ │ ├── __init__.py │ │ └── conf.py │ └── __init__.py ├── videos │ └── test_video.mp4 ├── yolo │ ├── coco.names │ ├── frozen_darknet_tinyyolov3_model.bin │ ├── frozen_darknet_tinyyolov3_model.mapping │ └── frozen_darknet_tinyyolov3_model.xml └── detect_realtime_tinyyolo_ncs.py 6 directories, 13 files
Our TinyYOLO model trained on the COCO dataset is provided via the yolo/ directory.
The intel/ directory contains two classes provided by Intel Corporation:
TinyYOLOv3: A class for parsing, scaling, and computing Intersection over Union for the TinyYOLO results.TinyYOLOV3Params: A class for building a layer parameters object.
We will not review either of the Intel-provided scripts today. You are encouraged to review the files on your own.
Our pyimagesearch module contains our Conf class, a utility responsible for parsing config.json.
A testing video of people walking through a public place (grabbed from Oxford University‘s site) is provided for you to perform TinyYOLO object detection on. I encourage you to add your own videos/ as well.
The heart of today’s tutorial lies in detect_realtime_tinyyolo_ncs.py. This script loads the TinyYOLOv3 model and performs inference on every frame of a realtime video stream. You may use your PiCamera, USB camera, or a video file residing on disk. The script will calculate the overall frames per second (FPS) benchmark for near real-time TinyYOLOv3 inference on your Raspberry Pi 4B and NCS2.
Our Configuration File

Our configuration variables are housed in our config.json file. Go ahead and open it now and let’s inspect the contents:
{
// path to YOLO architecture definition XML file
"xml_path": "yolo/frozen_darknet_tinyyolov3_model.xml",
// path to the YOLO weights
"bin_path": "yolo/frozen_darknet_tinyyolov3_model.bin",
// path to the file containing COCO labels
"labels_path": "yolo/coco.names",
Line 3 defines our TinyYOLOv3 architecture definition file path while Line 6 specifies the path to the pre-trained TinyYOLOv3 COCO weights.
We then provide the path to the COCO dataset label names on Line 9.
Let’s now look at variables used to filter detections:
// probability threshold for detections filtering "prob_threshold": 0.2, // intersection over union threshold for filtering overlapping // detections "iou_threshold": 0.15 }
Lines 12-16 define the probability and Intersection over Union (IoU) thresholds so that weak detections may be filtered by our driver script. If you are experiencing too many false positive object detections, you should increase these numbers. As a general rule, I like to start my probability threshold at 0.5.
Implementing the YOLO and Tiny-YOLO object detection script for the Movidius NCS
We are now ready to implement our Tiny-YOLO object detection script!
Open up the detect_realtime_tinyyolo_ncs.py file in your directory structure and insert the following code:
# import the necessary packages from openvino.inference_engine import IENetwork from openvino.inference_engine import IEPlugin from intel.yoloparams import TinyYOLOV3Params from intel.tinyyolo import TinyYOLOv3 from imutils.video import VideoStream from pyimagesearch.utils import Conf from imutils.video import FPS import numpy as np import argparse import imutils import time import cv2 import os
We begin on Lines 2-14 by importing necessary packages; let’s review the most important ones:
openvino: TheIENetworkandIEPluginimports allow our Movidius NCS to take over the TinyYOLOv3 inference.intel: TheTinyYOLOv3andTinyYOLOV3Paramsclasses are provided by Intel Corporation (i.e., not developed by us) and assist with parsing the TinyYOLOv3 results.imutils: TheVideoStreamclass is threaded for speedy camera frame capture. TheFPSclass provides a framework for calculating frames per second benchmarks.Conf: A class to parse commented JSON files.cv2: OpenVINO’s modified OpenCV is optimized for Intel devices.
With our imports ready to go, now we’ll load our configuration file:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--conf", required=True,
help="Path to the input configuration file")
ap.add_argument("-i", "--input", help="path to the input video file")
args = vars(ap.parse_args())
# load the configuration file
conf = Conf(args["conf"])
The command line arguments for our Python script include:
--conf: The path to the input configuration file that we reviewed in the previous section.--input: An optional path to an input video file. If no input file is specified, the script will use a camera instead.
With our configuration path specified, Line 24 loads our configuration file from disk.
Now that our configuration resides in memory, now we’ll proceed to load our COCO class labels:
# load the COCO class labels our YOLO model was trained on and
# initialize a list of colors to represent each possible class
# label
LABELS = open(conf["labels_path"]).read().strip().split("\n")
np.random.seed(42)
COLORS = np.random.uniform(0, 255, size=(len(LABELS), 3))
Lines 29-31 load our COCO dataset class labels and associate a random color with each label. We will use the colors when it comes to annotating our resulting bounding boxes and class labels.
Next, we’ll load our TinyYOLOv3 model onto our Movidius NCS:
# initialize the plugin in for specified device
plugin = IEPlugin(device="MYRIAD")
# read the IR generated by the Model Optimizer (.xml and .bin files)
print("[INFO] loading models...")
net = IENetwork(model=conf["xml_path"], weights=conf["bin_path"])
# prepare inputs
print("[INFO] preparing inputs...")
inputBlob = next(iter(net.inputs))
# set the default batch size as 1 and get the number of input blobs,
# number of channels, the height, and width of the input blob
net.batch_size = 1
(n, c, h, w) = net.inputs[inputBlob].shape
Our first interaction with the OpenVINO API is to initialize our NCS’s Myriad processor and loads the pre-trained TinyYOLOv3 from disk (Lines 34-38).
We then:
- Prepare our
inputBlob(Line 42). - Set the batch size to
1as we will be processing a single frame at a time (Line 46). - Determine the input volume shape dimensions (Line 47).
Let’s go ahead and initialize our camera or file video stream:
# if a video path was not supplied, grab a reference to the webcam
if args["input"] is None:
print("[INFO] starting video stream...")
# vs = VideoStream(src=0).start()
vs = VideoStream(usePiCamera=True).start()
time.sleep(2.0)
# otherwise, grab a reference to the video file
else:
print("[INFO] opening video file...")
vs = cv2.VideoCapture(os.path.abspath(args["input"]))
# loading model to the plugin and start the frames per second
# throughput estimator
print("[INFO] loading model to the plugin...")
execNet = plugin.load(network=net, num_requests=1)
fps = FPS().start()
We query our --input argument to determine if we will process frames from a camera or video file and set up the appropriate video stream (Lines 50-59).
Due to a bug in Intel’s OpenCV-OpenVINO implementation, if you are using a video file you must specify the absolute path in the cv2.VideoCapture function. If you do not, OpenCV-OpenVINO will not be able to process the file.
Note: If the --input command line argument is not provided, a camera will be used instead. By default, your PiCamera (Line 53) is selected. If you prefer to use a USB camera, simply comment out Line 53 and uncomment Line 52.
Our next interaction with the OpenVINO API is to load TinyYOLOv3 onto our Movidius NCS (Line 64) while Line 65 starts measuring FPS throughput.
At this point, we’re done with the setup and we can now begin processing frames and performing TinyYOLOv3 detection:
# loop over the frames from the video stream
while True:
# grab the next frame and handle if we are reading from either
# VideoCapture or VideoStream
orig = vs.read()
orig = orig[1] if args["input"] is not None else orig
# if we are viewing a video and we did not grab a frame then we
# have reached the end of the video
if args["input"] is not None and orig is None:
break
# resize original frame to have a maximum width of 500 pixel and
# input_frame to network size
orig = imutils.resize(orig, width=500)
frame = cv2.resize(orig, (w, h))
# change data layout from HxWxC to CxHxW
frame = frame.transpose((2, 0, 1))
frame = frame.reshape((n, c, h, w))
# start inference and initialize list to collect object detection
# results
output = execNet.infer({inputBlob: frame})
objects = []
Line 68 begins our realtime TinyYOLOv3 object detection loop.
First, we grab and preprocess our frame (Lines 71-86).
Then, we performs object detection inference (Line 90).
Line 91 initializes an objects list which we’ll populate next:
# loop over the output items for (layerName, outBlob) in output.items(): # create a new object which contains the required tinyYOLOv3 # parameters layerParams = TinyYOLOV3Params(net.layers[layerName].params, outBlob.shape[2]) # parse the output region objects += TinyYOLOv3.parse_yolo_region(outBlob, frame.shape[2:], orig.shape[:-1], layerParams, conf["prob_threshold"])
To populate our objects list, we loop over the output items, create our layerParams, and parse the output region (Lines 94-103). Take note that we are using Intel-provided code to assist with parsing our YOLO output.
YOLO and TinyYOLO tend to produce quite a few false-positives. To combat this, next, we’ll devise two weak detection filters:
# loop over each of the objects for i in range(len(objects)): # check if the confidence of the detected object is zero, if # it is, then skip this iteration, indicating that the object # should be ignored if objects[i]["confidence"] == 0: continue # loop over remaining objects for j in range(i + 1, len(objects)): # check if the IoU of both the objects exceeds a # threshold, if it does, then set the confidence of that # object to zero if TinyYOLOv3.intersection_over_union(objects[i], objects[j]) > conf["iou_threshold"]: objects[j]["confidence"] = 0 # filter objects by using the probability threshold -- if a an # object is below the threshold, ignore it objects = [obj for obj in objects if obj['confidence'] >= \ conf["prob_threshold"]]
Line 106 begins a loop over our parsed objects for our first filter:
- We allow only objects with confidence values not equal to zero (Lines 110 and 111).
- Then we actually modify the confidence value (sets it to zero) for any object that does not pass our Intersection over Union (IoU) threshold (Lines 114-120).
- Effectively, objects with a low IoU will be ignored.
Lines 124 and 125 compactly account for our second filter. Inspecting the code carefully, these two lines:
- Rebuild (overwrite) our
objectslist. - Effectively, we are filtering out objects that do not meet the probability threshold.
Now that our objects only contain those which we care about, we’ll annotate our output frame with bounding boxes and class labels:
# store the height and width of the original frame
(endY, endX) = orig.shape[:-1]
# loop through all the remaining objects
for obj in objects:
# validate the bounding box of the detected object, ensuring
# we don't have any invalid bounding boxes
if obj["xmax"] > endX or obj["ymax"] > endY or obj["xmin"] \
< 0 or obj["ymin"] < 0:
continue
# build a label consisting of the predicted class and
# associated probability
label = "{}: {:.2f}%".format(LABELS[obj["class_id"]],
obj["confidence"] * 100)
# calculate the y-coordinate used to write the label on the
# frame depending on the bounding box coordinate
y = obj["ymin"] - 15 if obj["ymin"] - 15 > 15 else \
obj["ymin"] + 15
# draw a bounding box rectangle and label on the frame
cv2.rectangle(orig, (obj["xmin"], obj["ymin"]), (obj["xmax"],
obj["ymax"]), COLORS[obj["class_id"]], 2)
cv2.putText(orig, label, (obj["xmin"], y),
cv2.FONT_HERSHEY_SIMPLEX, 1, COLORS[obj["class_id"]], 3)
Line 128 extracts the height and width of our original frame. We’ll need these values for annotation.
We then loop over our filtered objects. Inside the loop beginning on Line 131, we:
- Check to see if the detected (x, y)-coordinates fall outside the bounds of the original image dimensions; if so, we discard the detection (Lines 134-136).
- Build our bounding box
labelconsisting of the object"class_id"and"confidence". - Annotate the bounding box rectangle and label using the
COLORS(from Line 31) on the output frame (Lines 145-152). If the top of the box is close to the top of the frame, Lines 145 and 146 move the label down by15pixels.
Finally, we’ll display our frame, calculate statistics, and clean up:
# display the current frame to the screen and record if a user
# presses a key
cv2.imshow("TinyYOLOv3", orig)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# update the FPS counter
fps.update()
# stop the timer and display FPS information
fps.stop()
print("[INFO] elapsed time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
# stop the video stream and close any open windows1
vs.stop() if args["input"] is None else vs.release()
cv2.destroyAllWindows()
Wrapping up, we display the output frame and wait for the q key to be pressed at which point we’ll break out of the loop (Lines 156-161).
Line 164 updates our FPS calculator.
When either (1) the video file has no more frames, or (2) the user presses the q key on either a video or camera stream, the loop exits. At that point, Lines 167-169 print FPS statistics to your terminal. Lines 172 and 173 stop the stream and destroy GUI windows.
YOLO and Tiny-YOLO object detection results on the Raspberry Pi and Movidius NCS
To utilize Tiny-YOLO on the Raspberry Pi with the Movidius NCS, make sure you have:
- Followed the instructions in “Configuring your Raspberry Pi + OpenVINO environment” to configure your development environment.
- Used the “Downloads” section of this tutorial to download the source code and pre-trained model weights.
After unarchiving the source code/model weights, you can open up a terminal and execute the following command:
$ python detect_realtime_tinyyolo_ncs.py --conf config/config.json \ --input videos/test_video.mp4 [INFO] loading models... [INFO] preparing inputs... [INFO] opening video file... [INFO] loading model to the plugin... [INFO] elapsed time: 199.86 [INFO] approx. FPS: 2.66
Here we have supplied the path to an input video file.
Our combination of Raspberry Pi, Movidius NCS, and Tiny-YOLO can apply object detection at the rate of ~2.66 FPS.
Video Credit: Oxford University.
Let’s now try using a camera rather than a video file, simply by omitting the --input command line argument:
$ python detect_realtime_tinyyolo_ncs.py --conf config/config.json [INFO] loading models... [INFO] preparing inputs... [INFO] starting video stream... [INFO] loading model to the plugin... [INFO] elapsed time: 804.18 [INFO] approx. FPS: 4.28
Notice that processing a camera stream leads to a higher FPS (~4.28 FPS versus 2.66 FPS respectively).
So, why is running object detection on a camera stream faster than applying object detection to a video file?
The reason is quite simple — it takes the CPU more cycles to decode frames from a video file than it does to read a raw frame from a camera stream.
Video files typically apply some level of compression to reduce the resulting video file size.
While the output file size is reduced, the frame still needs to be decompressed when read — the CPU is responsible for that operation.
On the contrary, the CPU has significantly less work to do when a frame is read from a webcam, USB camera, or RPi camera module, hence why our script runs faster on a camera stream versus a video file.
It’s also worth noting that the fastest speed can be obtained using a Raspberry Pi camera module. When using the RPi camera module the onboard display and stream processing GPU (no, not a deep learning GPU) on the RPi handles reading and processing frames so the CPU doesn’t have to be involved.
I’ll leave it as an experiment to you, the reader, to compare USB camera vs. RPi camera module throughput rates.
Note: All FPS statistics collected on RPi 4B 4GB, NCS2 (connected to USB 3.0) and serving an OpenCV GUI window on the Raspbian desktop which is being displayed over VNC. If you were to run the algorithm headless (i.e. no GUI), you may be able to achieve 0.5 or more FPS gains because displaying frames to the screen also takes precious CPU cycles. Please keep this in mind as you compare your results.
Drawbacks and limitations of Tiny-YOLO
While Tiny-YOLO is fast and more than capable of running on the Raspberry Pi, the biggest issue you’ll find with it is accuracy — the smaller model size results in a substantially less accurate model.
For reference, Tiny-YOLO achieves only 23.7% mAP on the COCO dataset while the larger YOLO models achieve 51-57% mAP, well over double the accuracy of Tiny-YOLO.
When testing Tiny-YOLO I found that it worked well in some images/videos, and in others, it was totally unusable.
Don’t be discouraged if Tiny-YOLO isn’t giving you the results that you want, it’s likely that the model just isn’t suited for your particular application.
Instead, consider trying a more accurate object detector, including:
- Larger, more accurate YOLO models
- Single Shot Detectors (SSDs)
- Faster R-CNNs
- RetinaNet
For embedded devices such as the Raspberry Pi, I typically always recommend Single Shot Detectors (SSDs) with a MobileNet base. These models are challenging to train (i.e. optimizing hyperparameters), but once you have a solid model, the speed and accuracy tradeoffs are well worth it.
If you’re interested in learning more about these object detectors, my book, Deep Learning for Computer Vision with Python, shows you how to train each of these object detectors from scratch and then deploy them for object detection in images and video streams.
Inside of Raspberry Pi for Computer Vision you’ll learn how to train MobileNet SSD and InceptionNet SSD object detectors and deploy the models to embedded devices as well.
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this tutorial, you learned how to utilize Tiny-YOLO for near real-time object detection on the Raspberry Pi using the Movidius NCS.
Due to Tiny-YOLO’s small size (< 50MB) and fast inference speed (~244 FPS on a GPU), the model is well suited for usage on embedded devices such as the Raspberry Pi, Google Coral, and NVIDIA Jetson Nano.
Using both a Raspberry Pi and Movidius NCS, we were capable of obtaining ~4.28 FPS.
I would suggest using the code and pre-trained model provided in this tutorial as a template/starting point for your own projects — extend them to fit your own needs.
To download the source code and pre-trained Tiny-YOLO model (and be notified when future tutorials are published here on PyImageSearch), just enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

