Table of Contents
- Meet BLIP: The Vision-Language Model Powering Image Captioning
- What Is Image Captioning and Why Is It Challenging?
- Configuring Your Development Environment
- A Brief History of Image Captioning Models
- The Rise of Vision-Language Models (VLMs)
- What Is BLIP?
- BLIP vs. Traditional Image Captioning Models
- What We Are Building with BLIP
- Try It Yourself: Run the BLIP Model on Real Tasks
- Summary
Meet BLIP: The Vision-Language Model Powering Image Captioning
In this tutorial, you will learn how image captioning has evolved from early CNN-RNN models to today’s powerful vision-language models. We’ll explore the limitations of traditional approaches, the rise of foundation models, and how BLIP (Bootstrapping Language-Image Pre-training) stands out by combining strong visual understanding with natural language generation. You’ll also understand why BLIP is practical for real-world deployment — and get a preview of the scalable captioning system we’ll build in the rest of the series.

This lesson is the 1st of a 5-part series on Deploying BLIP for Image Captioning on AWS ECS Fargate:
- Meet BLIP: The Vision-Language Model Powering Image Captioning (this tutorial)
- Preparing the BLIP Backend for Deployment with Redis Caching and FastAPI
- Deploying the BLIP Backend to AWS ECS Fargate with Load Balancing (to be featured in a future mini-course)
- Load Testing and Auto Scaling the BLIP Backend on ECS Fargate (to be featured in a future mini-course)
- Build a Next.js Frontend for Your Image Captioning API on AWS ECS Fargate (to be featured in a future mini-course)
To learn how BLIP evolved into a production-ready vision-language model for image captioning — and why it’s a major leap from earlier approaches, just keep reading.
What Is Image Captioning and Why Is It Challenging?
Image captioning is the task of generating a natural language sentence that describes the content of an image. Unlike object detection or classification, where the goal is to recognize specific objects or assign a label, captioning requires the model to understand the full scene and compose a meaningful, fluent description of what’s happening.
Take the image below as an example:

Notice that the caption does more than just list objects. It:
- Identifies key entities (man, bike, street)
- Captures the action (riding)
- Infers contextual details (urban, busy, daylight)
This kind of output reflects real-world language — and that’s exactly what makes image captioning so difficult.
Why It’s Challenging
- To generate captions like the one above, a model must solve three complex problems at once:
- Computer Vision: The model must understand what’s in the image: detect objects, scenes, and actions. This is traditionally handled by convolutional or transformer-based vision encoders.
- Language Generation: The model needs to convert visual information into fluent, coherent, and grammatically correct text — a task historically reserved for language models (e.g., RNNs, LSTMs, or Transformers).
- Cross-Modal Reasoning: This is where things get interesting: the model must bridge vision and language, aligning what it “sees” with how humans talk about it. It’s not just about recognizing objects, but knowing what to say and in what order.
And there’s an added twist — there’s rarely just one “correct” caption.
For example, the same image above could also be described as:
- “A cyclist commutes through the downtown area.”
- “A man pedals along a sunlit city street.”
Both are valid. The model must be flexible yet accurate, which is a fine balance to strike.
Why Traditional Vision Tasks Aren’t Enough
It’s easy to assume image captioning is just detection + sentence generation. But real-world captioning:
- Requires understanding relationships (e.g., a child holding a balloon vs. a balloon next to a child)
- Involves subjective interpretation (e.g., tone, focus, emphasis)
- Needs natural language fluency, not just object names
This makes image captioning one of the most representative tasks in Vision-Language modeling — and an ideal benchmark for measuring how well models (e.g., BLIP) understand and describe the world.
Configuring Your Development Environment
To follow along with the BLIP model demo, you’ll need to install a few essential Python libraries.
Luckily, everything is pip-installable:
$ pip install transformers torchvision pillow
- transformers gives you access to the pretrained BLIP model and processor from Hugging Face.
- torchvision is used for image processing utilities and dataset support.
- pillow is required to load and manipulate image files (via
PIL.Image).
Need Help Configuring Your Development Environment?

All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code immediately on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
A Brief History of Image Captioning Models
Before we had vision-language foundation models like BLIP, image captioning relied on simpler, more modular pipelines — most notably, the combination of CNNs and RNNs. This architecture was the cornerstone of captioning systems for much of the 2010s.
The Classic Approach: CNN + RNN
The transition to neural image captioning began around 2014, when researchers first started combining Convolutional Neural Networks (CNNs) with Recurrent Neural Networks (RNNs) to generate natural language descriptions from images.
One of the earliest deep learning-based captioning models came from Mao et al. (2014), who introduced a Multimodal Recurrent Neural Network (m-RNN) framework. In their design, a CNN was used to extract visual features, which were then fed into an RNN to generate captions. While innovative, this approach was still somewhat modular and lacked full end-to-end training.
Soon after, Karpathy and Fei-Fei (2015) proposed a different strategy: instead of generating a full sentence outright, their model learned to align sentence fragments with image regions. It introduced the idea of fine-grained visual-linguistic alignment, a concept that would later influence attention mechanisms and multimodal transformers.
Then, in 2015, came a breakthrough: the Show and Tell model from Google Research. This was the first model to offer a clean, fully end-to-end trainable pipeline that connected image features directly to a language decoder.
- A Convolutional Neural Network (CNN) (e.g., Inception or ResNet) was used to extract a fixed-length vector from an input image.
- That vector was passed into a Recurrent Neural Network (RNN), typically an LSTM (Long Short-Term Memory), which decoded it into a sentence word by word.
The model learned to map image features to the semantic space of natural language using supervised training on image-caption pairs (e.g., from MS Common Objects in Context (COCO)).

Show and Tell was widely adopted because of its simplicity, effectiveness, and generalizability across datasets. It became the de facto neural baseline for captioning, and inspired countless follow-up models — including extensions with attention, region-based modeling, and reinforcement learning.
But despite its success, this CNN+RNN pipeline had important limitations — which we’ll explore next.
Limitations of the CNN+RNN Pipeline
Despite its early success, the CNN+RNN architecture had several key limitations that became more evident as vision-language datasets and expectations grew:
- Task-Specific: These models were trained only for captioning and couldn’t adapt to related tasks like visual question answering (VQA), image-text retrieval, or multimodal reasoning. Every new task required retraining from scratch.
- Weak Language Modeling: LSTMs, while powerful for their time, struggled with generating long, coherent sentences — especially when compared to transformer-based models that would emerge later. Captions often lacked diversity and grammatical richness.
- Coarse Visual Understanding: CNNs typically extract a single global feature vector for the entire image. This limited the model’s ability to reason about object relationships, scene structure, and localized attention — all critical for detailed captioning.
- Rigid Architecture: The pipeline separated vision and language into distinct stages. The CNN and RNN were trained together, but there was little opportunity for cross-modal learning or feedback. This made the model less adaptable and harder to extend.
These limitations eventually pushed the field to explore more flexible, unified architectures — ones that could jointly process visual and textual information and generalize across multiple vision-language tasks.
Toward Multimodal Learning
The evolution of language models (e.g., Transformer-based BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer)) inspired similar changes in computer vision. Researchers started combining the two worlds by building vision-language models (VLMs) that could:
- Jointly encode images and text
- Perform multiple tasks (captioning, VQA, retrieval)
- Share parameters and representations across modalities
This laid the groundwork for modern VLMs like ViLBERT, LXMERT, UNITER, and eventually BLIP.
The Rise of Vision-Language Models (VLMs)
As researchers pushed beyond the limitations of task-specific pipelines like CNN+RNN, a new class of models began to emerge — Vision-Language Models (VLMs). These models were designed to handle both visual and textual information together and perform a wide range of tasks within a single, unified architecture.
Unlike earlier models that treated image and text separately, VLMs focused on cross-modal learning, where the two modalities are deeply fused through layers of attention and representation learning.
What Are Vision-Language Models?
A Vision-Language Model (VLM) is a neural network trained on paired image and text data, with the goal of learning a shared semantic space between the two modalities. These models are designed to:
- Understand what’s in an image (visual recognition)
- Interpret how it’s described in natural language
- Align both modalities to enable tasks like image captioning, retrieval, visual question answering (VQA), segmentation, and more — often with minimal task-specific fine-tuning
At their core, VLMs treat vision and language as joint inputs and learn to reason across them in a unified framework.
What Can a Vision-Language Model Do?
A Vision-Language Model can perform a wide range of tasks using the same underlying architecture — including:
- Object localization
- Zero-shot segmentation
- Visual question answering
- One-shot learning with instructions
The input remains the same image, but the task changes based on the provided prompt or instruction. This flexibility is a defining strength of modern VLMs.

VLMs are typically built using transformer architectures, which enable rich attention mechanisms and deep cross-modal interaction. Architecturally, they come in two major forms:
- Dual-stream models: Separate encoders for image and text, followed by a fusion module (e.g., ViLBERT, LXMERT)
- Single-stream models: Images and text tokens are jointly processed in the same transformer layers (e.g., UNITER, Oscar)
This architectural flexibility — paired with their multitask capabilities — has made VLMs a cornerstone of modern AI systems and paved the way for foundation models like BLIP, which we’ll explore next.
Key Models That Paved the Way
Here are some of the foundational VLMs that led us to models like BLIP:
ViLBERT (Lu et al., 2019)
- One of the first large-scale VLMs
- Used dual-stream architecture: one transformer for images, one for text
- Introduced cross-modal attention layers to allow interaction between modalities
- Focused on VQA and retrieval, not generative tasks like captioning
LXMERT (Tan and Bansal, 2019)
- Similar to ViLBERT but with a different fusion strategy
- Used separate encoders for vision and language, followed by a joint reasoning module
- Also focused on VQA and reasoning, not captioning
UNITER (Chen et al., 2020)
- Switched to a single-stream transformer — both image regions and words go through the same encoder
- Enabled better fusion and alignment
- Supported image-text retrieval and captioning
- Trained on large datasets with contrastive and masked modeling objectives
Oscar (Li, Yin, et al., 2020)
- Enhanced the UNITER framework by incorporating object tags (e.g., “dog,” “bench”) as additional input tokens
- These tags helped models ground the language more accurately to visual content
- Strong performance on captioning and retrieval tasks
Captioning vs. Non-Captioning Models
Not all early VLMs were capable of generating captions. Here’s how they compare:

While ViLBERT and LXMERT laid the architectural foundation for cross-modal reasoning, it was UNITER and Oscar that helped VLMs become generative — a crucial step toward modern captioning models like BLIP.
Shared Vision-Language Representations
Despite their differences, all of these models moved toward a common goal: learning shared embeddings for images and text. This allows:
- Captions to align with corresponding images
- Visual regions to align with sentence fragments
- Retrieval, reasoning, and generation to happen across modalities
These shared representations are what enable VLMs to generalize across tasks — forming the backbone of today’s multitask foundation models (e.g., BLIP, CLIP, and BLIP-2).
What Is BLIP?
BLIP, short for Bootstrapped Language-Image Pretraining, is a vision-language foundation model developed by Salesforce Research. Introduced in 2022, BLIP was designed to unify the strengths of image understanding and natural language generation — while keeping the architecture efficient, flexible, and pretraining-friendly.
BLIP isn’t just an image captioning model — it’s a multitask VLM capable of:
- Generating captions (e.g., traditional captioning models)
- Answering visual questions (VQA)
- Retrieving relevant captions or images (image-text retrieval)
Its standout feature is that it can perform all these tasks using a single, unified transformer-based model, without needing to train separate architectures for each one.
Why “Bootstrapped”?
The term bootstrapped refers to BLIP’s ability to generate its own pseudo-captions during pretraining, especially when working with noisy or unlabeled web data.
Here’s how it works:
- Many real-world image-text pairs (especially scraped from the web) are noisy, vague, or irrelevant.
- BLIP uses a captioning model to generate high-quality candidate captions for these weakly labeled images.
- A filter module evaluates whether these synthetic captions are descriptive enough to be used for training.
- Only the accepted image-caption pairs are retained, effectively bootstrapping the training dataset from noisy sources.
This process improves data diversity and reduces reliance on costly human-labeled datasets — making BLIP highly scalable, efficient, and robust across domains.
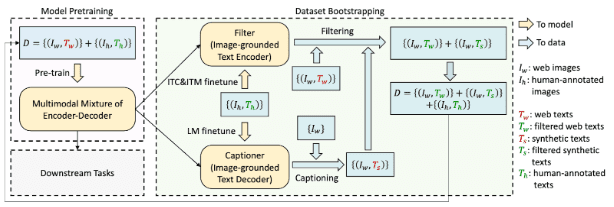
BLIP Architecture Overview
At a high level, BLIP follows a flexible, modular design that supports both vision-language understanding and language generation tasks. It integrates:
- A Vision Transformer (ViT) to encode input images into patch-level embeddings
- A Text Transformer, which can function as an encoder or decoder depending on the task
- A Cross-Modal Transformer that fuses visual and textual features using attention mechanisms
What makes BLIP special is that its architecture supports both:
- Contrastive Learning: aligning image-text pairs in a shared embedding space for tasks like image-text retrieval
- Generative Modeling: producing fluent outputs for captioning, VQA, and instruction-following
These capabilities are achieved through three core branches in the model:
- ITC (Image-Text Contrastive) Learning: Learns aligned visual-linguistic representations
- ITM (Image-Text Matching): Classifies whether a caption matches the image
- LM (Language Modeling): Generates free-form text from visual input

This modular yet unified design allows BLIP to be applied across tasks — from retrieval to captioning — without needing architecture-specific tuning. It’s one of the reasons BLIP is widely used for real-time applications.
Pretraining Objectives
BLIP is trained on large-scale image-text data using three complementary tasks, ensuring that it learns both alignment and generation:

These objectives make BLIP capable of both understanding and generating multimodal content, all in a single model.
What Makes BLIP Special?
BLIP introduces a number of innovations and practical advantages:
- Multitask-Ready: Works for captioning, VQA, and retrieval without changing architecture
- Pretrained + Open-Source: Easily available on Hugging Face (Salesforce/blip-image-captioning-base)
- Generative and Discriminative: Supports both contrastive learning and fluent caption generation
- Efficient for Deployment: Lightweight enough to run in real-time FastAPI/Docker setups
- Foundation Model Design: Learns general-purpose visual-linguistic representations that generalize well to downstream tasks
Why Not BLIP-2?
You might be wondering: why aren’t we using BLIP-2, the newer and more accurate version?
While BLIP-2 improves zero-shot reasoning and produces even richer captions, it comes with heavier computational requirements. In many cases, running BLIP-2 reliably requires GPU-backed infrastructure, which complicates deployment on serverless platforms (e.g., AWS (Amazon Web Services) Fargate).
For this series, we’ll be using the original BLIP model because:
- It’s lightweight enough to run on a CPU
- It’s fast and cost-effective for real-time inference
- It still delivers solid captioning performance out of the box
This choice keeps the focus on learning how to build and deploy VLM-powered applications — without needing expensive infrastructure from day one.
This combination of architectural flexibility, scalable pretraining, and strong real-world performance makes BLIP one of the most practical and production-ready vision-language models available today.
Up next, we’ll see how BLIP compares to traditional captioning models — and why it represents a significant evolution in how we build real-world image-to-language systems.
BLIP vs. Traditional Image Captioning Models
To fully appreciate what BLIP brings to the table, it’s useful to compare it with earlier generations of image captioning systems — particularly those based on CNN+RNN architectures. These models were influential but task-specific, whereas BLIP is a unified, general-purpose foundation model.
The following shows how they compare.
Traditional CNN + RNN Pipeline
Before models like BLIP, the most common approach to image captioning followed this structure:
- A Convolutional Neural Network (CNN) (e.g., ResNet, Inception) extracts a global feature vector from the image.
- A Recurrent Neural Network (RNN), typically an LSTM, takes that vector and generates a caption word-by-word.
- The system is trained end-to-end on image-caption pairs from datasets like MS COCO.
While effective for small-scale captioning tasks, this pipeline had limitations:
- It was task-specific — only worked for captioning, not for VQA or retrieval.
- The CNN and RNN were loosely connected, limiting multimodal reasoning.
- Language generation was often rigid or repetitive, especially on out-of-distribution inputs.
BLIP’s Foundation Model Approach
In contrast, BLIP replaces this modular pipeline with a single unified transformer architecture that:
- Processes images and text jointly using cross-modal attention
- Supports multiple tasks (captioning, retrieval, VQA) without architectural changes
- Generates fluent natural language and understands it too — all within one model
This shift mirrors what BERT and GPT did for language: from task-specific models to flexible, general-purpose systems.
Side-by-Side Comparison
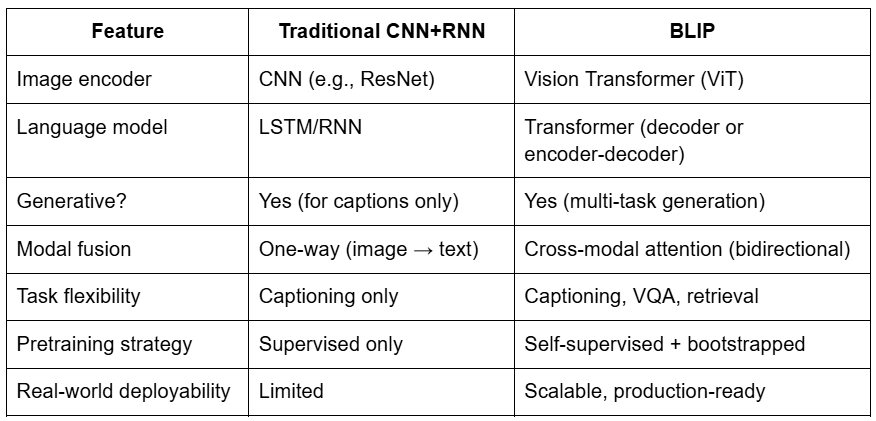
Why This Matters
BLIP’s architecture is more than just a captioning model — it’s a foundation model for vision + language. It reflects a larger trend in AI where multimodal reasoning, scalability, and generalization are more important than building separate models for each task.
While CNN+RNN systems were the early pioneers, they’ve now been largely replaced by transformer-based vision-language models (e.g., BLIP, BLIP-2, Flamingo, and PaLI).
What We Are Building with BLIP
In this mini-series, you won’t just learn what BLIP is — you’ll actually build and deploy a production-grade image captioning system that leverages BLIP’s multitask capabilities. By the end, you’ll have a real-world setup that can:
- Accept user-uploaded images
- Generate natural language captions using BLIP
- Cache repeated requests for faster inference
- Serve responses through a FastAPI backend
- Expose it via a modern frontend (Next.js + TailwindCSS)
- Deploy everything to AWS ECS (Amazon Elastic Container Service) Fargate with autoscaling
System Flow: High-Level Sequence
Here’s a step-by-step breakdown of what happens when a user uploads an image:

This sequence diagram captures the core flow of the image captioning pipeline you’ll implement:
- The user uploads an image via the Next.js frontend interface.
- The frontend sends the image to the FastAPI backend.
- The backend first checks the Redis cache to see if the caption for this image already exists (based on a hash or ID).
- If a cached caption exists, it is returned immediately — saving inference time.
- If not, the BLIP model is called to generate a new caption from the image.
- The new caption is stored in Redis for future reuse.
- The backend sends the caption back to the frontend, which then displays it to the user.
This caching-first architecture ensures that repeat uploads don’t cause unnecessary inference, improving both cost-efficiency and response time.
Why This Architecture?
This setup balances performance, scalability, and cost-efficiency:
- We use BLIP (not BLIP-2) to keep the model small and CPU-friendly.
- Redis caching helps avoid redundant computation when the same image is uploaded.
- The FastAPI backend is lightweight, async-ready, and easy to containerize.
- The frontend is clean and fast, built with React and TailwindCSS.
- AWS Fargate handles autoscaling and orchestration — no manual server management.
Try It Yourself: Run the BLIP Model on Real Tasks
Before we deploy BLIP as an inference service, let’s explore its capabilities directly in Python. In this demo, we’ll use two pretrained models from Hugging Face:
- Salesforce/blip-image-captioning-base for caption generation
- Salesforce/blip-vqa-base for visual question answering (VQA)
Together, these models showcase how BLIP handles key vision-language tasks:
- Image Captioning: Generate captions for an image in two ways:
- Unconditional: Let the model freely describe the image
- Conditional: Add a guiding text prompt like “A photo of…”
- Visual Question Answering (VQA): Ask natural-language questions about the image and get concise answers
Example 1: Image Captioning (Unconditional)
In unconditional captioning, you pass only the image, and BLIP generates a caption without any prompt.
Use case: Alt-text generation, image summarization, accessibility tools
from transformers import BlipProcessor, BlipForConditionalGeneration
from PIL import Image
import torch
# load model and processor
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
model.eval()
# load your image
image = Image.open("example.jpg").convert("RGB")
# generate caption (no text prompt)
inputs = processor(images=image, return_tensors="pt")
output = model.generate(**inputs)
caption = processor.decode(output[0], skip_special_tokens=True)
print("Unconditional Caption:", caption)
The above code runs unconditional image captioning using the BLIP model (Salesforce/blip-image-captioning-base).
- First, the model and processor are loaded from Hugging Face.
- The processor handles image preprocessing and tokenization, while the model generates the caption.
- An input image is loaded using PIL, converted to RGB, and passed to the processor without any accompanying text prompt. This allows the model to freely generate a caption based solely on the visual content of the image.
- The output tokens are decoded into a human-readable caption and printed — making this a simple, prompt-free way to describe an image.
Output Example:
“A woman sitting on the beach with her dog.”
Example 2: Image Captioning (Conditional)
Here, you provide a guiding prefix like “A photograph of” to influence the style or focus of the caption.
Use case: Product tagging, brand voice alignment, stylistic control
# conditional captioning with a prompt
prompt = "A picture of"
inputs = processor(images=image, text=prompt, return_tensors="pt")
output = model.generate(**inputs)
caption = processor.decode(output[0], skip_special_tokens=True)
print("Conditional Caption:", caption)
Here we perform conditional image captioning using BLIP, where a short text prompt is used to guide the caption generation. Instead of asking the model to describe the image freely, we provide a prefix — in this case, “A picture of” — which nudges the model to complete the sentence in a specific style or context.
The prompt and image are tokenized together using the processor, passed to the model for generation, and then decoded into a natural-language caption. This approach is useful when you want more control over the tone, framing, or focus of the generated description.
Output Example:
“A picture of a woman and her dog on the beach.”
Example 3: Visual Question Answering (VQA)
BLIP can also answer specific questions about the image — but for this, you’ll need to load a VQA-specific variant of the model:
Use case: Multimodal assistants, educational tools, image-based QA
from transformers import BlipForQuestionAnswering
# load VQA-specific model
vqa_processor = BlipProcessor.from_pretrained("Salesforce/blip-vqa-base")
vqa_model = BlipForQuestionAnswering.from_pretrained("Salesforce/blip-vqa-base")
vqa_model.eval()
question = "What is the person doing?"
inputs = vqa_processor(image, question, return_tensors="pt")
output = vqa_model.generate(**inputs)
answer = vqa_processor.decode(output[0], skip_special_tokens=True)
print("VQA Answer:", answer)
In this snippet, we load and run the BLIP model specifically trained for Visual Question Answering (VQA). Unlike the captioning variant, this model (Salesforce/blip-vqa-base) is optimized to take both an image and a natural-language question as input, and produce a concise answer.
- First, we initialize the model and its corresponding processor from the Hugging Face Transformers library.
- The processor handles both the image and the question, converting them into tokenized tensors that the model can understand.
- We also call
.eval()to ensure the model runs in inference mode (disabling dropout layers and gradient tracking).
Once loaded, we define a question — in this case, “What is the person doing?” — and pass it along with the image into the processor. This prepares the inputs in the format expected by the BLIP VQA model.
The model then generates a sequence of tokens representing the answer. We decode these tokens back into human-readable text using the processor’s .decode() method, and print the result.
This process lets you query an image conversationally, enabling intelligent visual understanding — a capability useful for educational tools, accessibility solutions, and AI assistants.
Output Example:
“petting dog”
Try your own questions like:
- “What is the person holding?”
- “How many dogs are there?”
- “Where is this photo taken?”
What You Just Saw
Without switching models or configs, BLIP handled:
- Basic captioning
- Instruction-followed captioning
- Free-form question answering
All powered by one unified transformer. This flexibility is exactly why BLIP is a great fit for real-world applications — including the one you’re about to build and deploy.
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: April 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this lesson, we explored the evolution of image captioning — from early CNN+RNN pipelines to modern, transformer-based vision-language models. We introduced BLIP (Bootstrapped Language-Image Pretraining) as a flexible foundation model that combines image understanding with natural language generation. You learned how BLIP differs from traditional captioning models by supporting multiple tasks such as captioning and visual question answering (VQA) using unified, pretrained architectures.
We examined BLIP’s architecture, its self-supervised bootstrapping strategy, and how it enables both unconditional and conditional captioning. We also clarified that while BLIP supports prompt-style prefixes, it does not handle full instruction-following prompts — a capability reserved for models like BLIP-2.
To wrap up, we ran real code examples using two separate models:
blip-image-captioning-basefor generating captionsblip-vqa-basefor answering questions about images
In the next lesson, we’ll move from experimentation to engineering — and begin building a FastAPI backend that turns BLIP into a deployable inference service.
Citation Information
Singh, V. “Meet BLIP: The Vision-Language Model Powering Image Captioning,” PyImageSearch, P. Chugh, S. Huot, A. Sharma, and P. Thakur, eds., 2025, https://pyimg.co/an023
@incollection{Singh_2025_meet-blip-the-vlm-powering-image-captioning,
author = {Vikram Singh},
title = {{Meet BLIP: The Vision-Language Model Powering Image Captioning}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Aditya Sharma and Piyush Thakur},
year = {2025},
url = {https://pyimg.co/an023},
}
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.