Table of Contents
- llama.cpp: The Ultimate Guide to Efficient LLM Inference and Applications
- The Evolution of Large Language Models
- Understanding llama.cpp
- Background on Gerganov Contributions
- Unique Selling Point (USP) of llama.cpp
- Which Foundational Models Does llama.cpp Currently Support?
- What Is the llama.cpp Model File Format?
- How Does llama.cpp Work?
- Setup and Installation of llama.cpp
- Get the Code
- Build Options
- Building with Metal (macOS)
- Building with CUDA
- Other Backend Options
- Platform-Specific Builds
- Conclusion
- Utilizing llama.cpp: CLI, Server, and UI Integrations
- Chatting with Llama3-8B Using llama.cpp via CLI on a MacBook M3 Pro with Metal Backend
- Llama.cpp Web Server with OpenAI API
- UI Integrations Using llama.cpp
- Bindings Available for llama.cpp
- What Is llama-cpp-python?
- Installation
- High-Level API
- Pulling Models from Hugging Face Hub
- Chat Completion
- LangChain Compatibility
- OpenAI Compatible Web Server
- Conclusion
- Multimodal Chat with Llama.cpp and Llava Vision Language Model
- Summary
llama.cpp: The Ultimate Guide to Efficient LLM Inference and Applications
In this tutorial, you will learn how to use llama.cpp for efficient LLM inference and applications. You will explore its core components, supported models, and setup process. Furthermore, you’ll dive into llama-cpp-python bindings and build a real-world application showcasing the power of LLMs using llama-cpp-python, including integration with LangChain and a Gradio UI.

To learn how to leverage llama.cpp for efficient LLM inference and build powerful applications, just keep reading.
The Evolution of Large Language Models
The landscape of artificial intelligence (AI) has undergone a significant transformation with the advent of large language models (LLMs). In recent years, we have transitioned from basic language models to complex foundation models that have revolutionized various industries. This shift can be compared to the profound impact of the AlexNet architecture introduced in 2012. The evolution of LLMs has been nothing short of a technological revolution, enabling breakthroughs in natural language processing, understanding, and generation.
LLMs have driven innovation across numerous sectors, from research labs to startups, creating value and opportunities in diverse application domains. Businesses have leveraged these models to build advanced applications, leading to significant advancements in customer service, content creation, and more.
Figure 1 illustrates the timeline of major LLM developments from 2019 to 2023:
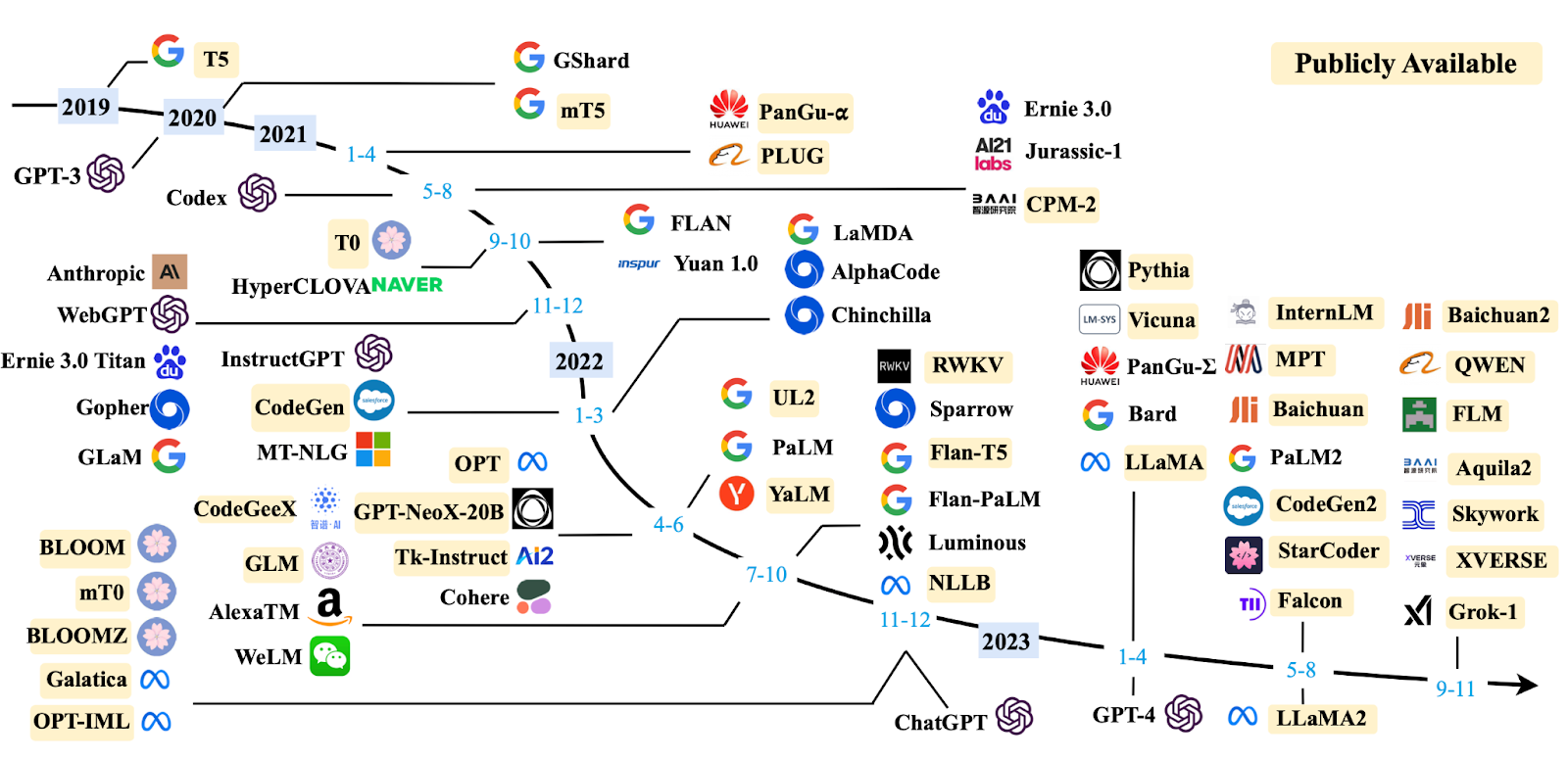
This timeline shows the rapid advancement in LLM technology. Starting with the introduction of GPT-3 in 2019, which set a new standard for language models, we have seen continuous improvements and innovations. In 2020, models like T5 and mT5 made significant strides, and by 2021, we had seen the rise of models like Codex and InstructGPT, which improved the ability of LLMs to understand and generate human-like text.
In 2022, the landscape further evolved with the introduction of models like GPT-4, GLaM, and LaMDA, which brought new capabilities in conversational AI and multimodal learning. The trend continued in 2023 with even more sophisticated models like LLaMA, Vicuna, and Falcon, each contributing to pushing the boundaries of what LLMs can achieve.
As we step into 2024, the AI community continues to witness the development of new models such as LLaMA4 and GPT-4 Omni. Google’s Gemini series, including versions like Gemini 1.5, represents another leap forward, integrating advanced features and higher efficiency. These new models promise to further revolutionize AI applications, offering unprecedented performance and scalability.
The Challenge with LLMs
Despite their transformative potential, LLMs come with their own set of challenges. The massive parameter sizes of these models, such as the 70 billion parameters of LLaMA3 or even larger models like GPT-4, necessitate high-powered computing resources. Hosting and deploying such models require substantial computational power, posing significant hurdles for building applications that are both responsive and efficient.
The high demand for computational resources means that not everyone can afford to leverage these powerful models. The initial investment in specialized hardware and the ongoing operational costs create barriers to entry, limiting the ability of smaller organizations and independent developers to harness the full potential of LLMs.
Enters llama.cpp
This is where llama.cpp, a C++ implementation of the LLaMA model family, comes into play. The goal of llama.cpp is to address these very challenges by providing a framework that allows for efficient inference and deployment of LLMs with reduced computational requirements. By optimizing model performance and enabling lightweight deployment, llama.cpp democratizes access to powerful AI capabilities, making it feasible for a broader range of users to build and deploy advanced applications.
In this guide, we will explore what llama.cpp is, its core components and architecture, the types of models it supports, and how it facilitates efficient LLM inference. We will also delve into its Python bindings, llama-cpp-python, and demonstrate practical applications using LangChain and Gradio.
Without further ado, let’s dive into the world of llama.cpp and uncover its potential for revolutionizing LLM inference and application development.

Understanding llama.cpp
llama.cpp is an open-source C++ library developed by Georgi Gerganov, designed to facilitate the efficient deployment and inference of large language models (LLMs). It has emerged as a pivotal tool in the AI ecosystem, addressing the significant computational demands typically associated with LLMs.
The primary objective of llama.cpp is to optimize the performance of LLMs, making them more accessible and usable across various platforms, including those with limited computational resources. By leveraging advanced quantization techniques, llama.cpp reduces the size and computational requirements of LLMs, enabling faster inference and broader applicability.
This framework supports a wide range of LLMs, particularly those from the LLaMA model family developed by Meta AI. It allows developers to deploy these models more efficiently, even on personal computers, laptops, and mobile devices, which would otherwise be constrained by the high computational needs of these models.
As of today, llama.cpp is a popular open-source library hosted on GitHub, boasting over 60,000 stars, more than 2,000 releases, and contributions from over 770 developers. This extensive community involvement ensures continuous improvement and robust support for various use cases.
Background on Gerganov’s Contributions
llama.cpp utilizes the GGML library, a general-purpose tensor library co-developed alongside llama.cpp. GGML is designed to enable large models and high performance on commodity hardware. This library is crucial for powering llama.cpp, providing the necessary tensor operations and optimizations to achieve efficient model inference.
Whisper.cpp, another project by Gerganov, precedes llama.cpp and implements Whisper, a speech-to-text model by OpenAI, in C++. This background highlights Gerganov’s expertise in creating high-performance, C++-based implementations of significant machine learning models.
With llama.cpp, users can achieve significant cost savings and performance improvements, making it possible to build and deploy AI applications without the need for expensive, high-end hardware. This democratizes access to advanced AI capabilities, fostering innovation and expanding the potential use cases for LLMs in various industries.
Unique Selling Point (USP) of llama.cpp
Runs Efficiently on CPU: Unlike other inference libraries that rely on closed-source, hardware-dependent libraries like CUDA, llama.cpp can run efficiently on just a CPU. This includes compatibility with various devices, including Android devices.
GPU Compatibility: It’s not limited to CPU usage; llama.cpp can also run on GPUs using multiple different backends. This ensures developers can leverage the power of GPUs for enhanced performance when available without being restricted to specific hardware requirements.
Apple Silicon Support: Efficient inference is supported on Apple silicon hardware (e.g., M1, M2, and M3 Metal), enhancing its versatility.
CPU+GPU Hybrid Inference: Supports CPU plus GPU hybrid inference to partially accelerate models that are larger than the total VRAM capacity on GPU.

Platform Support: Compatible with various platforms, including macOS, Linux, Windows, and Docker, making it highly adaptable for different development environments.
Model Support: While initially designed for the Llama family models, llama.cpp also supports various other open-source LLMs, broadening its applicability.
MIT License: Distributed under the MIT license, imposing minimal restrictions on reuse, further promoting the adoption of llama.cpp. This high license compatibility allows developers to integrate and utilize the library in their projects with ease and flexibility.
These features collectively make llama.cpp a powerful and adaptable tool for efficient LLM inference across diverse hardware environments.
Which Foundational Models Does llama.cpp Currently Support?
llama.cpp supports a wide range of foundational models, including several prominent and widely used ones. Here’s a summary of the key models and types supported:
LLaMA Family
- LLaMA 1
- LLaMA 2
- LLaMA 3
Mistral Models
- Mistral 7B
- Mixtral MOE
Other Notable Models
- Falcon
- Microsoft Phi
- Gemma
- CodeLLaMA
Vision-Language Models (Multimodal Models)
- LLaVA 1.5/1.6
- BakLLaVA
- ShareGPT4V
- MoonDream
Additional Supported Models
- Qwen 2
- DeepSeq
- CoderV2
- Command R and Command R+ by Cohere
- StarCoder2
llama.cpp supports both pre-trained models and fine-tuned versions of these base models, allowing users to leverage the power of fine-tuning for specific tasks and applications. This flexibility makes it a versatile tool for a variety of use cases in natural language processing and machine learning.
Adding Your Own Model
If you have a custom model that you would like to use with llama.cpp, the process involves several steps to ensure compatibility. Here’s a brief overview:
- Convert the Model to GGUF: Begin by converting your model to the GGUF format, which is essential for it to be used with
llama.cpp. - Define the Model Architecture: Define your model’s architecture within the
llama.cppframework. - Build the GGML Graph Implementation: Implement the GGML graph to match your model’s architecture and requirements.
- Open a Pull Request (PR): Submit your implementation as a PR to the
llama.cpprepository. - Ensure Compatibility: Make sure that your new model architecture works seamlessly with the main GGML backends, including CUDA, Metal, and CPU.
For detailed instructions on adding new models to llama.cpp, refer to the official documentation or the relevant README file. This comprehensive support for various models, along with the ability to integrate custom models, highlights the flexibility and extensibility of llama.cpp, making it a powerful tool for efficient LLM inference and application development.
What Is the llama.cpp Model File Format?
The model file format that llama.cpp uses is GGUF (GPT-Generated Unified Format). GGUF is a binary file format for storing and fast loading models for inference with GGML and executors based on GGML.
The following is a detailed look at GGUF.
- Conversion from Training Formats: Typically, large language models are trained using frameworks such as PyTorch, which have their own model formats. These pre-trained or fine-tuned models are then converted to GGUF for use in
llama.cpp(GGML). - Successor to GGML: GGUF emerged as a successor to GGML (a tensor library and format), addressing its shortcomings. GGML introduced a distinctive binary format for the distribution of LLMs. GGUF improves upon this by including architecture metadata, supporting special tokens, and being extensible to add new information without breaking backward compatibility.
- Single File Format: Unlike other formats like PyTorch, which separate the tokenizer and model weights, GGUF consolidates everything into a single file. This includes the tokenization, model weights, and all necessary metadata, making it more streamlined and easier to manage.
- Quantization Support: GGUF supports a variety of quantization types, which can reduce memory usage and increase inference speed by lowering the model precision. This includes common floating point data formats like FP32, FP16, BrainFloat 16, and various quantized integer types like 8-bit, 6-bit, 5-bit, 4-bit, 3-bit, 2-bit, and 1.5-bit.
- Enhanced Performance: GGUF enhances performance, especially with models using new special tokens and custom prompt templates. This format ensures that models can be loaded quickly and perform efficiently during inference.
- Extensibility: GGUF is designed to be extensible, allowing new information to be added to models without breaking compatibility. This makes it a robust and future-proof choice for model file storage.
- Supporting Non-Llama Models: One of the key advantages of GGUF is that it enables support for non-llama models, making it versatile for a variety of model types beyond just those in the llama family.
How Does llama.cpp Work?
llama.cpp leverages the GGML library to perform large language model (LLM) inference, ensuring efficient and flexible deployment of models. Here’s a detailed look at how it operates, including basic examples and key features.
Core Mechanism
At its core, llama.cpp uses GGML to manage and execute the computational graphs required for LLM inference. GGML provides the foundational tensor operations and optimizations necessary for high-performance computation, primarily focusing on CPU efficiency with support for SIMD (Single Instruction, Multiple Data) instructions. GGML can also leverage GPU accelerators through backends like ggml-cuda and ggml-metal.
Here are some basic examples of using GGML for model inference:
These examples demonstrate the process of loading data, building a computation graph, and computing the results, primarily focusing on running on the CPU with efficient SIMD instructions.
Key Features of llama.cpp
llama.cpp builds upon the GGML foundation by adding several features specifically tailored for LLM inference. These features include:
- Data Formats: Efficient handling of model data formats like GGUF.
- Model Architectures: Support for various LLM architectures.
- Tokenizers: Efficient tokenization and detokenization processes.
- Sampling: Techniques for selecting the next token during inference.
- Grammar and KV Cache Management: Enhanced management of key-value caches and grammar rules to optimize performance.
These additions make llama.cpp a general-purpose API that simplifies integrating GGML into projects, offering a more user-friendly approach to running LLMs.
Step-by-Step Process to Using llama.cpp
Initialization: llama.cpp initializes a llama context from a GGUF file using the llama_init_from_file function. This function reads the header and body of the GGUF file, creating a llama context object containing the model information and the backend (CPU, GPU, or Metal) to run the model on.
Tokenization: The input text is tokenized using the llama_tokenize function. This function converts the input text into a sequence of tokens based on the tokenizer specified in the GGUF file header. The tokens are stored in an array of llama tokens, which are integers representing the token IDs.
Inference: llama.cpp generates the output text using the llama_generate function, which includes the following steps.
Forward Pass
- The function takes the input tokens and the llama context as arguments and runs the model on the specified backend.
- It uses the computation graph from the GGUF file header to perform the model’s forward pass, calculating the next token probabilities.
Sampling
- The next token is sampled from the probability distribution.
- The sampled token is appended to the output tokens.
Iteration
- This process repeats until the end-of-text token or the maximum number of tokens is reached.
- The output tokens are stored in another array of llama tokens.
Detokenization: The output tokens are detokenized using the llama_detokenize function. This function converts the output tokens back into a string of text based on the tokenizer specified in the GGUF file header. It handles special tokens, such as the end-of-text token, padding token, and unknown token, returning the final output text.
Detailed Example: Understanding the GGUF File
A GGUF file consists of a header and a body. The header contains key-value pairs that provide metadata about the model, such as its name, version, source, tokenizer, computation graph, etc. The body contains the tensors that represent the model parameters, such as the weights and biases of the layers. The tensors are stored in a compressed format to reduce the file size. The GGUF file format is extensible, meaning new features can be added without breaking compatibility with older models.
The following is a detailed breakdown of how llama.cpp processes a GGUF file.
Reading GGUF Files: A GGUF file consists of a header and a body. The header contains metadata such as model name, version, source, tokenizer, and computation graph. The body contains the model parameters (tensors) stored in a compressed format.
Inference Process
- The input tokens are first searched in the GGUF file.
- Once found,
llama.cppinitializes the model using thellama_init_from_filefunction. - The input text is tokenized into tokens.
- The model inference is performed using the computation graph specified in the GGUF header.
- The next tokens are generated and appended to the output sequence until the end condition is met.
- The tokens are detokenized back into human-readable text.
Example of Running llama.cpp
To illustrate the usage of llama.cpp, consider a simple example from the examples/simple directory of the repository. This example shows the basic workflow of loading a model, tokenizing input, generating output, and detokenizing the result.
Conclusion
llama.cpp, by utilizing the GGML library and the GGUF file format, provides a robust framework for efficient LLM inference. Its ability to run on both standard CPUs and GPUs, support for multiple backends, and comprehensive feature set make it a powerful tool for developers looking to implement high-performance language models in diverse environments.
Setup and Installation of llama.cpp
To get started with llama.cpp, follow these steps for cloning the repository and building the project on macOS, specifically leveraging the integrated GPU on an Apple M3 Pro using the Metal backend.
Get the Code
First, clone the llama.cpp repository from GitHub and navigate into the directory:
git clone https://github.com/ggerganov/llama.cpp cd llama.cpp
Build Options
Using make
make -j 8 LLAMA_CURL=1
By using the flag LLAMA_CURL=1, we enable the automatic downloading of models from URLs such as Hugging Face, eliminating the need for manual downloads.
Notes:
- For faster compilation, add the
-jargument to run multiple jobs in parallel. For example,make -j 8. - For faster repeated compilation, install
ccache. - For debug builds, run
make LLAMA_DEBUG=1.
Using Homebrew
On a Mac, you can use the Homebrew package manager:
brew install llama.cpp
Building with Metal (macOS)
Metal is enabled by default on macOS. Using Metal makes the computation run on the integrated GPU. To disable the Metal build at compile time, use the GGML_NO_METAL=1 flag or the GGML_METAL=OFF cmake option. When built with Metal support, you can explicitly disable GPU inference with the --n-gpu-layers|-ngl 0 command-line argument.
Building with CUDA
For GPU acceleration using CUDA cores of Nvidia GPUs, ensure the CUDA toolkit is installed. This is more relevant if you have an NVIDIA GPU on a Linux or Windows machine.
Using make
make GGML_CUDA=1
Using CMake
cmake -B build -DGGML_CUDA=ON cmake --build build --config Release
Other Backend Options
- SYCL: For Intel GPU support, refer to
llama.cppfor SYCL. - Intel oneMKL: For Intel CPU optimization, refer to
Optimizing and Running LLaMA2 on Intel® CPU. - hipBLAS: For AMD GPU support using ROCm.
- Vulkan: For Vulkan support, detailed instructions are available in the
llama.cpprepository.
Platform-Specific Builds
- macOS: Metal is enabled by default.
- Windows: Refer to the
llama.cppGitHub repository for detailed instructions. - Linux: Options for CUDA and other GPU support are available.
Conclusion
Setting up and installing llama.cpp on macOS is straightforward, especially with the Homebrew package manager. By following these steps, you can optimize llama.cpp for your specific hardware setup, ensuring efficient LLM inference and model deployment. For other operating systems like Windows or Linux, refer to the llama.cpp GitHub repository for detailed instructions and additional build options.
Utilizing llama.cpp: CLI, Server, and UI Integrations
In this section, we will explore three primary ways to utilize llama.cpp: via the Command Line Interface (CLI), by setting up a server, and through various UI integrations. We will demonstrate how to start running a model using the CLI, set up an HTTP web server for llama.cpp, and highlight different UI frameworks that use llama.cpp as their backend. Additionally, we will touch upon various bindings available for llama.cpp, including Python, Go, Node.js, and more.
Chatting with Llama3-8B Using llama.cpp via CLI on a MacBook M3 Pro with Metal Backend
To interact with the Llama3-8B model, you can use the llama-cli tool, which will automatically download the model from the Hugging Face repository and start an interactive chat session. Follow these steps:
Navigate to the llama.cpp Directory: First, make sure you are in the Llama.cpp directory
cd llama.cpp
Run the Command to Start Chatting: Use the following command to download the Llama3-8B model from Hugging Face and start an interactive chat session:
./llama-cli --hf-repo "QuantFactory/Meta-Llama-3-8B-GGUF" \
--model Meta-Llama-3-8B.Q8_0.gguf \
--ctx_size 2048 -n -1 -b 256 \
--temp 0.8 --repeat_penalty 1.1 -t 8 \
--color -r "User:" --in-prefix " " -i -p \
'User: Hi
AI: Hello. I am an AI chatbot. Would you like to talk?
User: Sure!
AI: What would you like to talk about?
User:'
Explanation of the Command and Flags
./llama-cli: This is the command to run the llama-cli executable. It assumes you are in the directory where llama-cli is located or that it is in your PATH.--hf-repo "QuantFactory/Meta-Llama-3-8B-GGUF": This flag specifies the Hugging Face repository where the model is located. The model will be downloaded from this repository.--model Meta-Llama-3-8B.Q8_0.gguf: This flag specifies the model file to be used. In this case, it is theMeta-Llama-3-8B.Q8_0.ggufmodel file.--ctx_size 2048: This flag sets the context size for the model. The context size determines how many tokens the model can remember from the input text. Here, it is set to2048tokens.-n -1: This flag sets the number of tokens to generate. The value-1means the model will generate tokens until it reaches the end of the context or a stopping condition.-b 256: This flag sets the batch size for processing tokens. A batch size of256tokens is specified.--temp 0.8: This flag sets the temperature for the text generation. A lower temperature (closer to0) makes the model’s output more deterministic, while a higher temperature (closer to1) makes it more random. Here, it is set to0.8, providing a balance between randomness and determinism.--repeat_penalty 1.1: This flag sets the penalty for repeating tokens. A value greater than1reduces the likelihood of the model repeating the same token sequence. Here, it is set to1.1.-t 8: This flag sets the number of threads to use for computation. Here, it is set to8threads, which can improve performance on multi-core processors.--color: This flag enables colored output in the terminal, which can make it easier to distinguish between different parts of the conversation.-r "User:": This flag specifies a stopping string. The model will stop generating tokens when it encounters the specified string. Here, it is set to“User:”, which helps to stop the model’s response appropriately during an interactive session.--in-prefix " ": This flag sets a prefix to be added to each input line. Here, it is set to a space, which can help format the input properly for the model.-i: This flag indicates that the model should run in interactive mode, allowing for ongoing input and output, simulating a conversation.-p: This flag prints the prompt provided to the model, which can be useful for debugging and understanding what the model is responding to.'User: Hi AI: Hello. I am an AI chatbot. Would you like to talk? User: Sure! AI: What would you like to talk about? User:': This is the initial prompt given to the model. It sets up a conversational context where the user says “Hi,” the AI introduces itself, and the user indicates a willingness to talk.
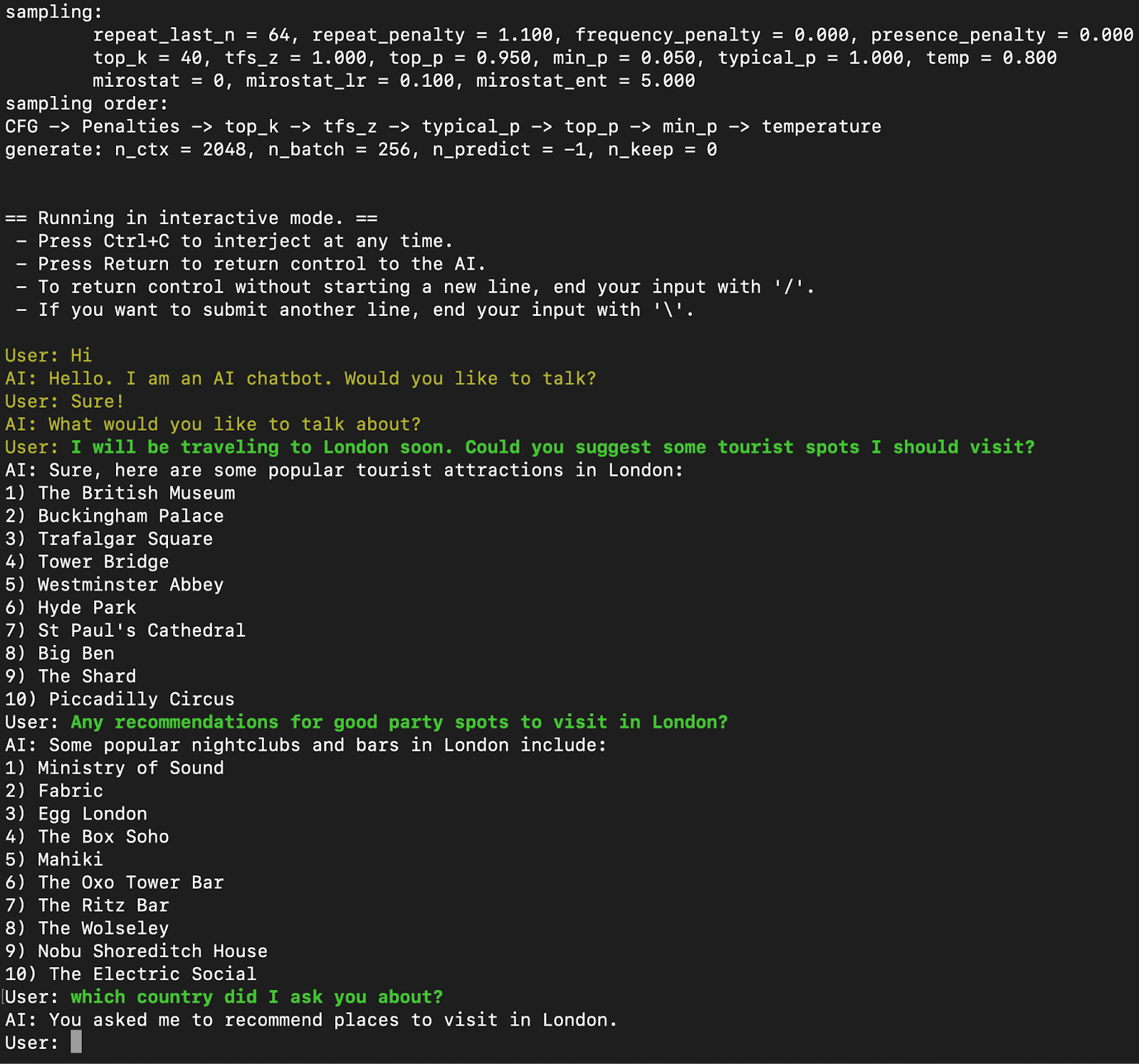
llama-cli framework.Figure 2 shows an interactive chat session with the Llama3-8B Q8_0 model using the llama-cli tool. During this session,
- The model effectively responds to user questions about tourist attractions and nightlife spots in London.
- Key parameters used include a context size of
2048tokens, a batch size of256, and a temperature of0.8, striking a balance between coherence and creativity. - The command automatically downloads the model from Hugging Face. It initiates the chat, illustrating how users can interact with the AI in real-time with
llama.cppon a MacBook M3 Pro with Metal backend.
There’s a lot more you can do with the llama.cpp CLI, which offers a wide range of functionalities and a lot of parameters, a few of which we’ve already shown you, such as the context window, batch size, interactive mode, and various sampling parameters. To learn more in-depth about the Llama CLI tool, we highly recommend checking out the Llama CLI Documentation.
Llama.cpp Web Server with OpenAI API
To set up and run the llama.cpp HTTP web server, follow these steps:
- Run the Server: When we executed the make command in
llama.cpp, it installed llama-server as well. Use the following command to start the HTTP server:
./llama-server --hf-repo "QuantFactory/Meta-Llama-3-8B-GGUF" \
--model Meta-Llama-3-8B.Q8_0.gguf \
--ctx_size 2048 -n -1 -b 256 \
--temp 0.8 --repeat_penalty 1.1 -t 8
In the llama-cli command, we included several additional arguments related to the interactive prompt configuration (e.g., --color, -r "User:", --in-prefix " ", and -i -p), followed by the initial conversation prompt. These arguments customize the CLI interaction experience.
For the llama-server command, we do not pass these interactive prompt configurations because the server handles interaction via HTTP requests instead.
--hf-repo: Specifies the Hugging Face repository to download the model from.--model: Specifies the path to the model file.--ctx_size: Sets the context size for the model.-n: Number of predictions to generate (-1means unlimited).-b: Batch size for processing.--temp: Temperature for sampling.--repeat_penalty: Penalty for repeating the same token.-t: Number of threads to use.
- Using the Server with OpenAI API Client: The following is a Python script to interact with the server using the OpenAI API client.
import openai
client = openai.OpenAI(
base_url="http://localhost:8080/v1",
api_key = "sk-no-key-required"
)
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are ChatGPT, an AI assistant. Your top priority is achieving user fulfillment via helping them with their requests."},
{"role": "user", "content": "Suggest places to Visit in London"}
]
)
print(completion.choices[0].message)
This script initializes an OpenAI client pointing to your local server and sends a chat completion request. The response includes a list of suggested places to visit in London.
Example Response
ChatCompletionMessage(content="The best places to visit in London are the iconic Big Ben clock tower, the Houses of Parliament, the London Eye, the Tower of London, the St Paul's Cathedral, the Natural History Museum, the Science Museum, the Victoria and Albert Museum, the Temple Bar, the Globe Theatre, the St James's Park, the Hyde Park, the Kensington Gardens, the Greenwich Park, the St John's Wood, the Finsbury Park, the Victoria Park, and the Regent's Park.\n\nYou can also visit the Seven Peaks – Alton Towers, Lake Garda, Lake Como, Lake Bolsena, Sibylline Mountains, and Ascent at Kilvey Hill\n```", role='assistant', function_call=None, tool_calls=None)
By following these steps, you can easily set up the llama.cpp HTTP web server and interact with it using the OpenAI API client. The server supports various configurations to optimize model performance and allows seamless integration with web-based interfaces. For more detailed information and additional parameters, refer to the llama.cpp server documentation.
UI Integrations Using llama.cpp
Several UI frameworks and local LLM platforms leverage llama.cpp as their backend. These frameworks provide user-friendly interfaces for running and interacting with LLMs without requiring deep technical expertise.

llama.cpp for a seamless user experience.Ollama
- Provides an easy-to-use wrapper around
llama.cpp. - Users can download Ollama and start interacting with models using a simple command like
ollama run model-name. - Maintains its own repository of models, simplifying the process for users unfamiliar with model setup and execution.
- Supports GGUF model file format and allows users to add custom models.
- For more details, check out our in-depth blog post.
LM Studio
- Offers a comprehensive suite for managing and interacting with LLMs.
- It uses
llama.cppas its backend - Provides features for running, chatting with LLMs, and running as a server.
- The standout feature is its intuitive and powerful UI, making it accessible to a broader audience.
- For more information, refer to our detailed blog post.
Oobabooga Text Generation UI
- Provides a seamless interface for generating text using LLMs powered by
llama.cpp. - Supports various backends like transformers, GPTQ, and AWQ, alongside
llama.cpp. - Caters to users with more knowledge about LLMs, offering features like fine-tuning models using low-rank adaptation techniques.
- For those interested in exploring further, visit its GitHub repository or read our comprehensive blog post.
Additionally, there are other popular UI frameworks that leverage llama.cpp, including:
- Jan.ai
- Faraday
- LocalAI
- GPT4All
- FreeChat
These platforms offer a variety of features and capabilities, enhancing the flexibility and usability of llama.cpp for different user needs and technical proficiencies.
Bindings Available for llama.cpp
There are various bindings available in different programming languages that allow access to the llama.cpp library. These bindings make interaction with llama.cpp versatile and easy to integrate into various programming environments and applications. While we’ll discuss the llama.cpp Python binding in detail in the next section. The following is a list of other available bindings.
- Python: abetlen/llama-cpp-python
- Node.js: withcatai/node-llama-cpp
- JavaScript: tangledgroup/llama-cpp-wasm
- Ruby: yoshoku/llama_cpp.rb
- Rust: edgenai/llama_cpp-rs
- Go: go-skynet/go-llama.cpp
- Scala 3: donderom/llm4s
- Java: kherud/java-llama.cpp
- Flutter: netdur/llama_cpp_dart
These bindings enable developers to leverage the power of llama.cpp across different programming languages, facilitating seamless integration and application development. By providing a range of bindings, llama.cpp ensures that developers can work in their preferred programming environment while utilizing the powerful inference capabilities of llama.cpp.
By offering these bindings, llama.cpp ensures that it can be integrated into a wide variety of projects, from web and mobile applications to enterprise-level systems and research projects. This flexibility is one of the key strengths of llama.cpp, making it a valuable tool for developers working across different domains and platforms. To learn more, you can refer to the links provided for each binding.
What Is llama-cpp-python?
The llama-cpp-python bindings offer a powerful and flexible way to interact with the llama.cpp library from Python. This package provides simple Python bindings for the llama.cpp library, giving both low-level access to the C API and high-level APIs for text completion and chat. Some notable features include:
- Low-level access to C API: via the
ctypesinterface. - High-level Python API for text completion: designed to be easy to use.
- OpenAI-like API: allows for seamless integration with existing OpenAI-compatible tools.
- LangChain compatibility: enables easy integration with the LangChain framework.
- LlamaIndex compatibility: allows for sophisticated indexing and querying capabilities.
- OpenAI-compatible web server: provides endpoints similar to the OpenAI API for easy deployment and interaction.
Installation
To get started with llama-cpp-python, you need Python 3.8+ and Xcode on MacOS. Here’s how to install the package.
pip install llama-cpp-python
As we have seen with llama.cpp, we will be running this on a MacBook M3 Pro using the Metal backend for acceleration. To leverage the integrated GPU using the Metal backend, use the following command.
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
If you encounter issues during installation, you can add --verbose to the pip install command to see the full CMake build log.
Supported Backends
llama-cpp-python also supports various backends for enhanced performance, including CUDA for Nvidia GPUs, OpenBLAS for CPU optimization, etc. These can be configured during installation as follows:
- CPU (OpenBLAS)
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
- CUDA (for Nvidia GPUs)
CMAKE_ARGS="-DLLAMA_CUDA=on" pip install llama-cpp-python
High-Level API
The high-level API in llama-cpp-python simplifies text and chat completion tasks. Here’s an example of how to use the Meta Llama3-8B 8-bit quantized model for basic text completion with several parameters:
from llama_cpp import Llama
llm = Llama(
model_path="./models/Meta-Llama-3-8B.Q8_0.gguf",
n_gpu_layers=-1,
ctx_size=2048,
temperature=0.8,
top_p=0.9,
max_tokens=128,
stop=["\n", "Q:"],
echo=True,
verbose=True,
seed=1234,
model_kwargs={"use_fp16": True},
generate_kwargs={"temperature": 0.7, "top_k": 50}
)
output = llm(
"Q: Name the planets in the solar system? A: ",
max_tokens=32
)
print(output)
Below is the output when you run the above code. The output showcases the performance and results of running the Llama model to answer the prompt “Name the planets in the solar system.” The detailed timings indicate the efficiency of the model, with a total load time of 533.62 ms, a sample time of 8.93 ms for 32 tokens, and an evaluation time of 1208.25 ms for 31 tokens. The completion successfully lists several planets before reaching the token limit, demonstrating the model’s quick and accurate response capabilities. The total time taken for the operation was 1762.26 ms, highlighting the model’s effective use of GPU acceleration with the Metal backend on the M3 Mac. The response includes 45 tokens in total, split between 13 prompt tokens and 32 completion tokens.
llama_print_timings: load time = 533.62 ms
llama_print_timings: sample time = 8.93 ms / 32 runs ( 0.28 ms per token, 3584.63 tokens per second)
llama_print_timings: prompt eval time = 533.60 ms / 13 tokens ( 41.05 ms per token, 24.36 tokens per second)
llama_print_timings: eval time = 1208.25 ms / 31 runs ( 38.98 ms per token, 25.66 tokens per second)
llama_print_timings: total time = 1762.26 ms / 44 tokens
{'id': 'cmpl-9d39d519-d8c7-469a-8842-5dda1dcb06de', 'object': 'text_completion', 'created': 1719866028, 'model': 'Meta-Llama-3-8B.Q4_K_M.gguf', 'choices': [{'text': '1) Mercury, 2) Venus, 3) Earth, 4) Mars, 5) Jupiter, 6) Saturn, 7)', 'index': 0, 'logprobs': None, 'finish_reason': 'length'}], 'usage': {'prompt_tokens': 13, 'completion_tokens': 32, 'total_tokens': 45}}
ggml_metal_free: deallocating
Common Parameters in Llama Class
model_path- Description: Path to the model file.
- Example:
model_path="./models/7B/llama-model.gguf"
n_gpu_layers- Description: Number of layers to run on the GPU.
- Example:
n_gpu_layers=-1offloads all layers to GPU
ctx_size- Description: Context size, determining the number of tokens the model can handle.
- Example:
ctx_size=2048
temperature- Description: Controls the randomness of predictions.
- Example:
temperature=0.8
top_p- Description: Selects tokens with cumulative probability up to this value.
- Example:
top_p=0.9
max_tokens- Description: Maximum number of tokens to generate.
- Example:
max_tokens=128
stop- Description: Sequences where the model should stop generating further tokens.
- Example:
stop=["\n", "Q:"]
echo- Description: Whether to echo back the input prompt in the generated text.
- Example:
echo=True
verbose- Description: Provides detailed logs if set to
True. - Example:
verbose=True
- Description: Provides detailed logs if set to
seed- Description: Seed for random number generation, ensuring reproducibility.
- Example:
seed=1234
model_kwargs- Description: Additional model-specific parameters.
- Example:
model_kwargs={"use_fp16": True}
generate_kwargs- Description: Additional parameters for the generation process.
- Example:
generate_kwargs={"temperature": 0.7, "top_k": 50}
Pulling Models from Hugging Face Hub
You can download models in GGUF format directly from Hugging Face using the from_pretrained method. Ensure you have the huggingface-hub package installed.
For example, as you can see, we download the Llama3-8B 4-bit k-quant medium quantized model:
from llama_cpp import Llama llm = Llama.from_pretrained(repo_id="QuantFactory/Meta-Llama-3-8B-GGUF", filename="Meta-Llama-3-8B.Q4_K_M.gguf")
By using the from_pretrained method, you can easily access and utilize various pre-trained models hosted on the Hugging Face Hub. This simplifies the process of model integration and ensures that you are working with the latest versions of the models.
Chat Completion
The llama-cpp-python bindings also support chat completion, providing interfaces to structure messages and generate responses:
from llama_cpp import Llama
llm = Llama(model_path="path/to/llama-2/llama-model.gguf", chat_format="llama-2")
response = llm.create_chat_completion(
messages=[
{"role": "system", "content": "You are an assistant who perfectly describes images."},
{"role": "user", "content": "Describe this image in detail please."}
]
)
print(response)
LangChain Compatibility
llama-cpp-python integrates effortlessly with the LangChain framework, enabling advanced workflows and applications. Here’s an example of how to use llama-cpp-python with LangChain. Make sure you have langchain installed:
from langchain.llms import LlamaCpp
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
template = "Question: {question}\nAnswer: Let's think this through step by step."
prompt = PromptTemplate(template=template)
llm = LlamaCpp(model_path="./models/7B/llama-model.gguf")
llm_chain = LLMChain(prompt=prompt, llm=llm)
question = "What are the main differences between Python and JavaScript?"
print(llm_chain.run(question))
In the above LangChain example, we define a prompt template with a placeholder for a question. The LlamaCpp class is initialized with the path to the model file. The LLMChain is then created, combining the prompt template and the LLM. When llm_chain.run(question) is called, the question is passed through the chain, and the LLM generates a detailed response. It’s important to note that LlamaCpp is integrated into LangChain, allowing seamless interaction without needing to import it directly from llama_cpp.
OpenAI Compatible Web Server
llama-cpp-python includes a web server that acts as a drop-in replacement for the OpenAI API. This server makes it easy to deploy models and interact with them through standard OpenAI-compatible endpoints.
To install the server package and start the server.
CMAKE_ARGS="-DLLAMA_METAL=on" pip install "llama-cpp-python[server]" python3 -m llama_cpp.server --model Meta-Llama-3-8B.Q8_0.gguf --n_gpu_layers -1
When you navigate to http://localhost:8000/docs, you’ll be greeted with a Swagger UI, a powerful tool for visualizing and interacting with the API. This user-friendly interface displays all available endpoints and allows you to test them directly from your browser. As seen in Figure 4, the Swagger UI for llama-cpp-python includes the following sections:
OpenAI V1 Endpoints
- POST /v1/completions: For generating text completions.
- POST /v1/embeddings: For creating text embeddings.
- POST /v1/chat/completions: For chat-based interactions.
- GET /v1/models: For retrieving available models.
Extras
- POST /extras/tokenize: For tokenizing input text.
- POST /extras/tokenize/count: For counting tokens in the input text.
- POST /extras/detokenize: For converting tokens back into text.
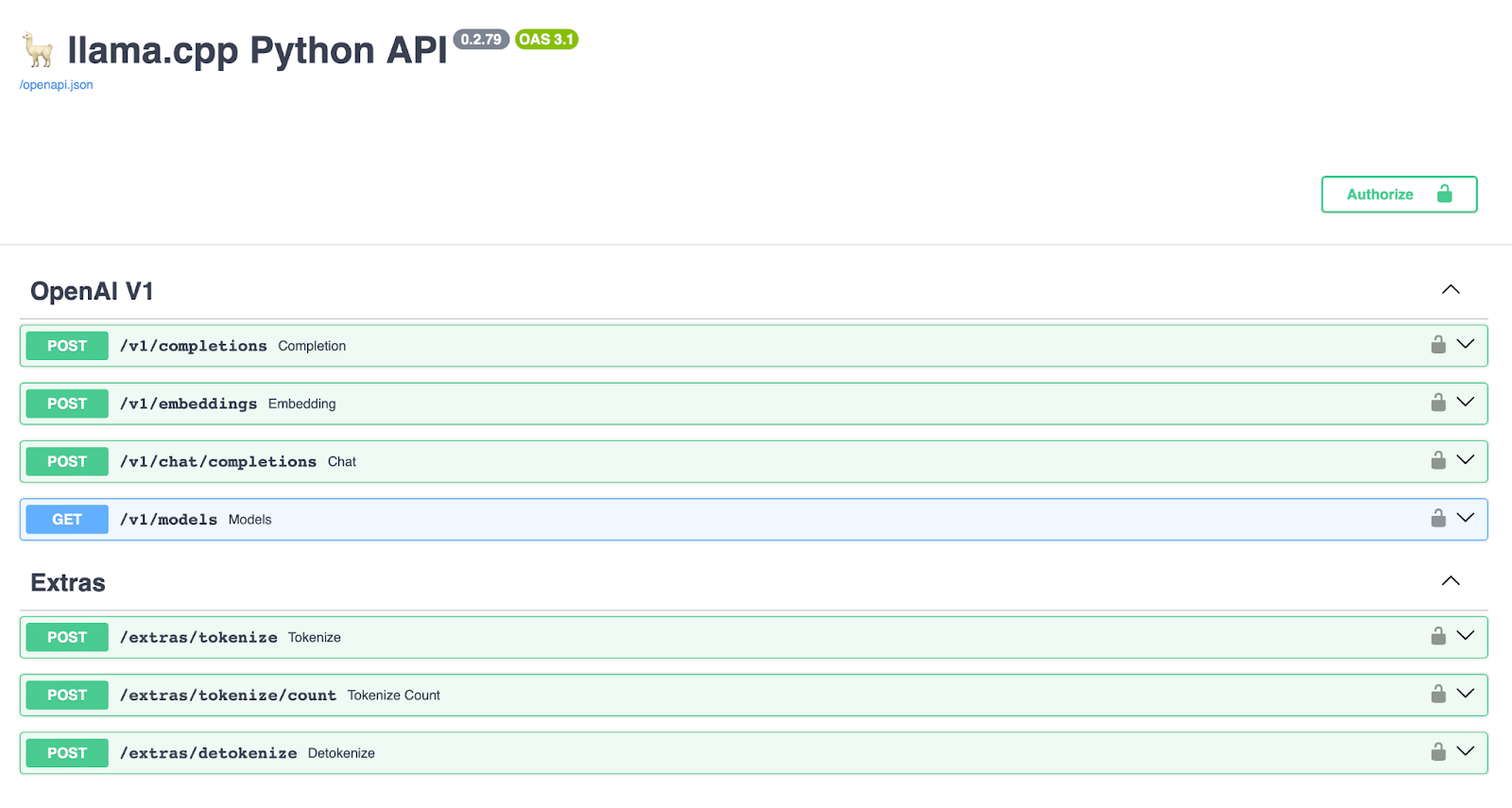
This interface not only makes it easier to understand and utilize the API but also showcases the flexibility and power of the llama-cpp-python integration. Kudos to the llama-cpp-python team for providing such a comprehensive and intuitive tool for developers!
By offering this web server, llama-cpp-python ensures that developers can integrate and build their applications efficiently using Python bindings. The complexities and technicalities (e.g., loading the model efficiently, offloading layers to the GPU with various supported backends, and much more) are handled by the llama.cpp release, allowing developers to focus on creating powerful and innovative applications.
Conclusion
The llama-cpp-python bindings provide a powerful and flexible interface for interacting with llama.cpp models in Python. With support for various backends and seamless integration with popular frameworks like LangChain and LlamaIndex, these bindings enable developers to build sophisticated AI applications efficiently.
Multimodal Chat with Llama.cpp and Llava Vision Language Model
The advent of multimodal models has opened new avenues for interactive AI applications, where users can seamlessly combine text and images to create rich and meaningful interactions. Leveraging the capabilities of Llama.cpp, we can build an advanced multimodal chat application that utilizes Llava, Moondream, and other vision language models. This section explores the development of such an application and demonstrates how Llama.cpp facilitates its creation.
Introduction
Based on the detailed deep dive we did on Llama.cpp, you already know it’s a versatile framework that allows you to load and use various open-source language models in GGUF format. It offers high-level Python bindings, making it easier to integrate these models into your applications. By utilizing these Python bindings, we are creating a multimodal chat application that processes both text and images to generate meaningful responses. This application leverages both Llava and Moondream vision language models for image understanding and text generation.
Key Features
- Multimodal Interaction: Users can upload images and ask questions about them.
- Llava Vision Language Model: Utilizes advanced vision language models for image and text processing.
- User-Friendly Interface: Built with Gradio, providing an intuitive and interactive user experience.
- Flexible Model Integration: Supports both Llava and Moondream models, allowing for customization based on user preferences.
Interface Snapshots
- Upload an Image and Ask a Question
- Users can upload an image by clicking the “Upload Image” button and selecting an image from their local machine.
- They can then enter a question about the image in the provided text box.
- Generate a Response
- After uploading the image and entering the question, users can click the “Submit” button to get the model’s response.
- The model processes the image and text inputs and generates a response based on the content of the image and the question asked.
Example Interface
Figure 5 showcases the interface of our multimodal chat application. The application allows users to upload an image and ask questions about it. The screenshot shows an uploaded image of a resort landscape with a swimming pool and palm trees. In the text input box, a user has entered the question: “Describe the landscape and the elements in it.”
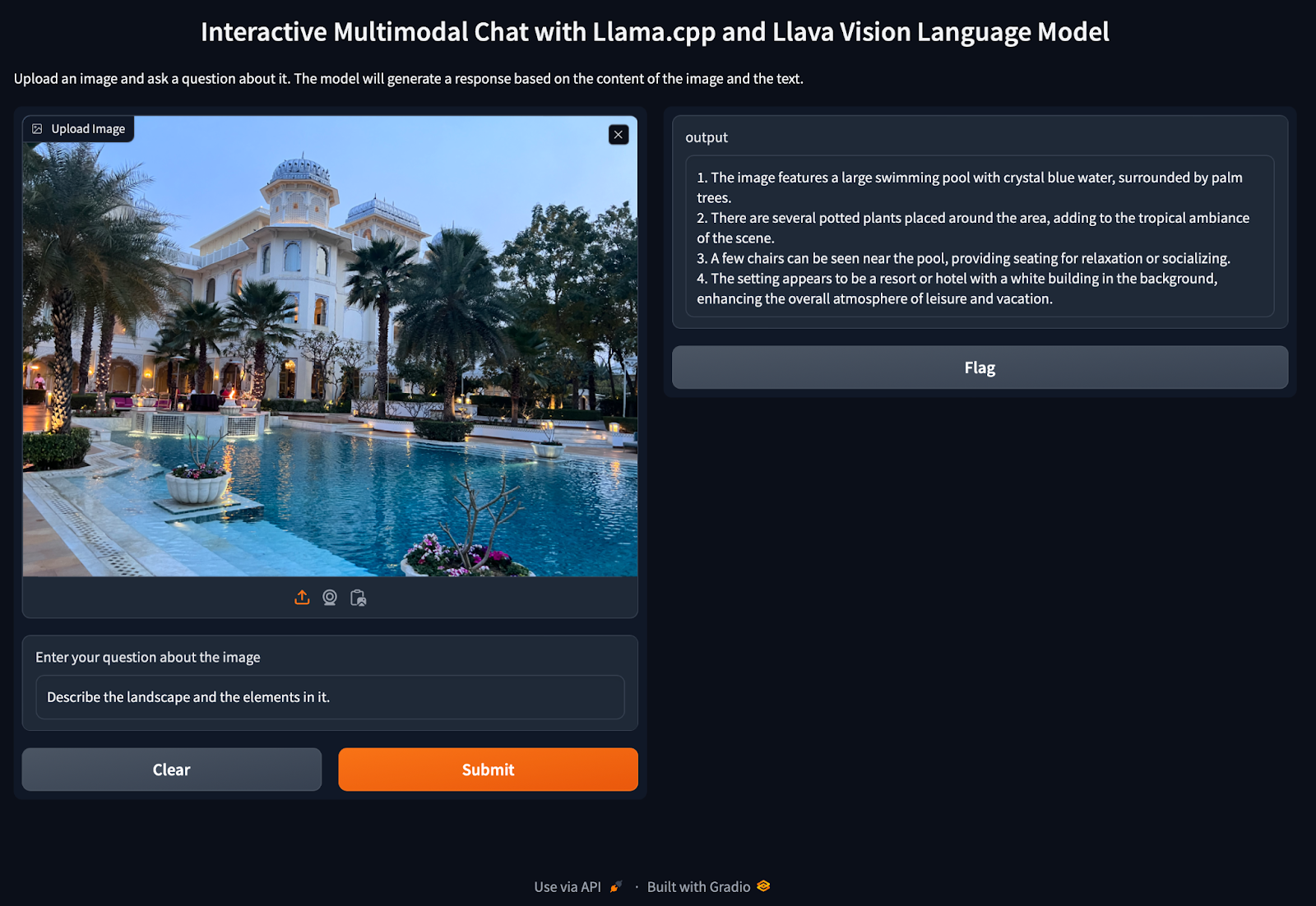
On the right side, the output from the model is displayed, which provides a detailed description of the image. The model identifies the key elements of the scene, such as the swimming pool with crystal blue water, the surrounding palm trees, the potted plants adding to the tropical ambiance, the chairs near the pool for seating, and the resort or hotel building in the background. This output demonstrates the model’s capability to analyze and describe the content of the image accurately.
This example highlights how the application leverages the Llava vision language models for image understanding and text generation, providing meaningful responses based on visual and textual inputs.
Code Walkthrough
To showcase the functionality of this multimodal chat application, we will walk through the code implementation step by step. For brevity, only essential portions of the code are displayed here, with detailed explanations for each part. The complete code, along with utility functions, is available through a subscription to PyImageSearch University. The video lesson for this tutorial provides an even deeper understanding of the Llama.cpp ecosystem, and is also available as part of the PyImageSearch University subscription.
We start by importing the necessary packages.
# import argparse for command line argument parsing import argparse # import gradio for creating the web interface import gradio as gr # import utility functions for model loading and processing images and questions from pyimagesearch.utils import load_model, process_image_and_ask_question
We import the essential libraries: argparse for handling command-line arguments, gradio for creating a user-friendly web interface, and our custom utility functions load_model and process_image_and_ask_question from the pyimagesearch.utils module.
Next, we set up command-line arguments. These arguments allow us to switch between different models (e.g., Llava and Moondream) and specify the repository ID and filenames for the Llama model and chat handler.
def main():
# set up argument parser for command line arguments
parser = argparse.ArgumentParser(description="Load Llama model with chat handler")
# add argument for the repository ID
parser.add_argument(
"--repo_id", type=str, default="mys/ggml_llava-v1.5-13b", help="Repository ID"
)
# add argument for the Llama model filename
parser.add_argument(
"--llm_filename",
type=str,
default="ggml-model-q5_k.gguf",
help="Filename for the Llama model",
)
# add argument for the chat handler filename
parser.add_argument(
"--chat_filename",
type=str,
default="mmproj-model-f16.gguf",
help="Filename for the chat handler",
)
# add argument for the model type (llava or moondream)
parser.add_argument(
"--model_type",
type=str,
choices=["llava", "moondream"],
default="llava",
help="Type of model to use: llava or moondream",
)
# parse the command line arguments
args = parser.parse_args()
Here, we define several command-line arguments.
--repo_id: specifies the repository ID.--llm_filename: specifies the filename for the Llama model.--chat_filename: specifies the filename for the chat handler.--model_type: allows us to choose between the Llava and Moondream models.
These arguments are then parsed and stored in the args variable.
Next, we load the model using the provided parameters. This step involves calling the load_model function, which loads the specified model and chat handler:
# load the model with the specified parameters
llm = load_model(
repo_id=args.repo_id,
llm_filename=args.llm_filename,
chat_filename=args.chat_filename,
model_type=args.model_type,
)
This function utilizes the arguments we parsed earlier to load the appropriate model and chat handler.
Now, we set up the Gradio interface. This is where we define how the user will interact with our application:
# create the gradio interface
iface = gr.Interface(
fn=lambda img, txt: process_image_and_ask_question(img, txt, llm),
inputs=[
# input for image upload
gr.Image(type="pil", label="Upload Image"),
# input for text question
gr.Textbox(label="Enter your question about the image"),
],
outputs="text",
title="Interactive Multimodal Chat with Llama.cpp and Llava Vision Language Model", # title of the interface
description="Upload an image and ask a question about it. The model will generate a response based on the content of the image and the text.", # description of the interface
)
In this section:
- We define a
lambdafunction that processes the image and text question using the loaded model. - We set up inputs for image uploads and text questions.
- We specify the output format as text.
- We provide a title and description for the interface.
Finally, we launch the Gradio interface:
# launch the gradio interface
iface.launch()
if __name__ == "__main__":
# run the main function
main()
This launches the application, allowing users to upload an image, ask a question about it, and receive a response generated by the model.
To conclude this section, let’s examine another result from our multimodal chat application, showcasing the power of combining Llama.cpp’s Python bindings with Llava Vision Language Models and Gradio’s user interface capabilities. This powerful integration allows us to create an intuitive and effective multimodal AI application.
In Figure 6, an image depicting a busy urban street scene is uploaded, and a question is posed about the activities and details observable in the scene. This setup illustrates the seamless interaction between text and visual data to generate meaningful responses.
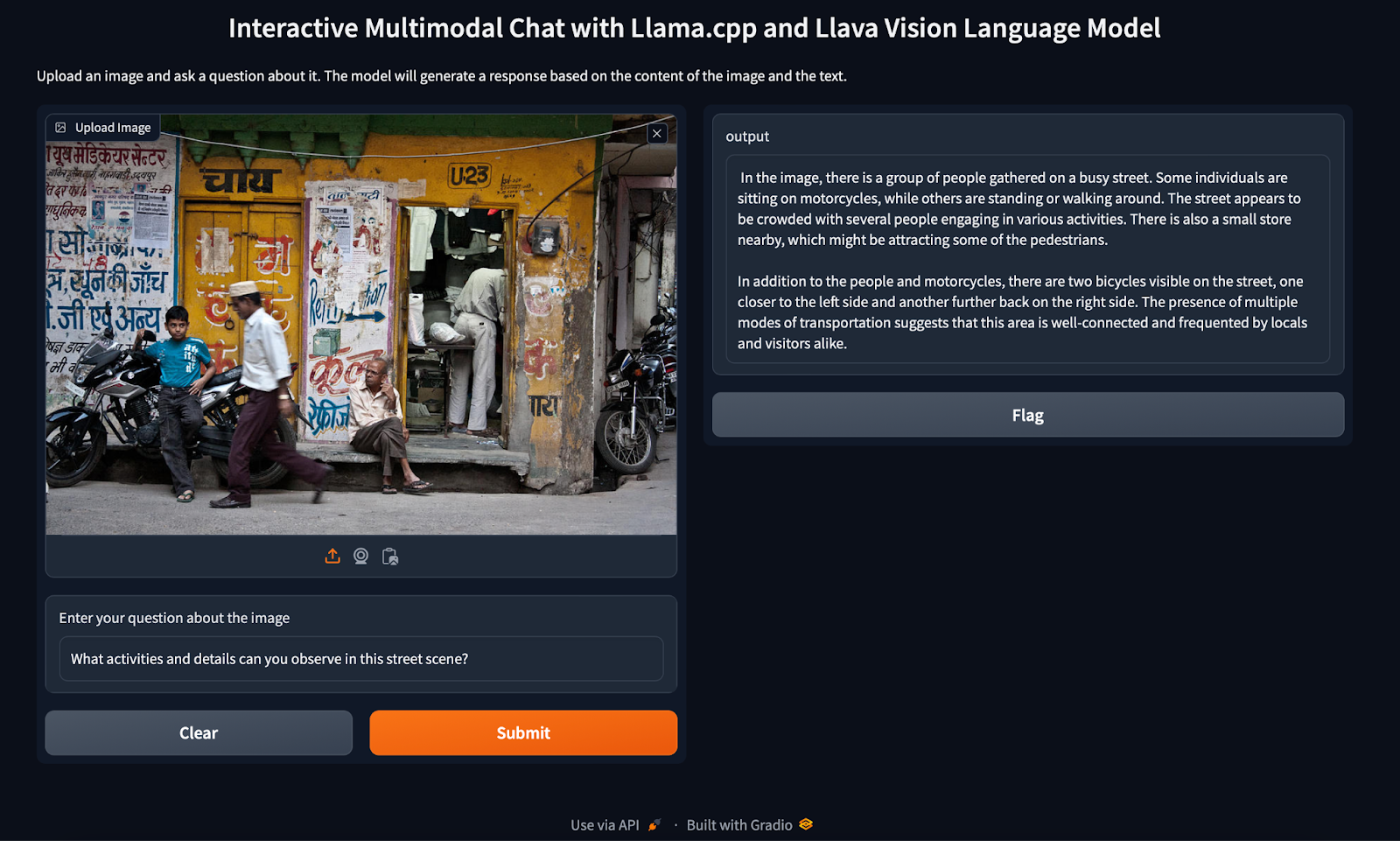
When we look at the result, the response generated by the Llava Vision Language Model is displayed on the right side. The model provides a detailed description of the scene:
- It identifies a group of people gathered on a busy street, mentioning that some individuals are sitting on motorcycles while others are standing or walking around.
- The response notes the presence of a small store that might be attracting pedestrians.
- Additionally, it highlights the presence of two bicycles, which indicates multiple modes of transportation and suggests that the area is well-connected and frequented by locals and visitors alike.
This example demonstrates how integrating Llama.cpp with Llava Vision Language Models and Gradio can create a robust and user-friendly application capable of analyzing and understanding complex images. The accurate and detailed response showcases the potential of these tools to develop powerful multimodal AI applications, making advanced AI capabilities accessible and easy to use.
What's next? We recommend PyImageSearch University.

120+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 120+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 94+ Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In the ever-evolving landscape of large language models (LLMs), llama.cpp emerges as a game-changer, offering efficient LLM inference capabilities that are both powerful and versatile. This comprehensive guide delves into the evolution of LLMs, highlighting the unique challenges they present and how llama.cpp steps in as a solution.
The post begins by providing a deep understanding of llama.cpp, including the background on its development and contributions from prominent figures like Georgi Gerganov. You’ll discover the unique selling points (USPs) of llama.cpp, such as its support for various foundational models and the ability to add custom models. The guide also explains the intricacies of the llama.cpp model file format and the core mechanisms that power its functionality.
Key features of llama.cpp are explored, followed by a step-by-step process to get started, including a detailed example of the GGUF file and how to run llama.cpp effectively. The post also covers the setup and installation of llama.cpp, providing options for different platforms, including macOS, CUDA, and other backend options.
For developers looking to integrate llama.cpp with other tools, the guide offers insights into utilizing llama.cpp via CLI, server, and UI integrations. You’ll find examples of chatting with LLaMA-3B and using llama.cpp as a web server with OpenAI API compatibility. The post also touches on llama-cpp-python, detailing installation, supported backends, API usage, and LangChain compatibility.
Finally, the blog post introduces a multimodal chat experience with llama.cpp and the Llava Vision Language Model, showcasing key features, interface snapshots, and a code walkthrough.
Whether you’re a seasoned developer or new to the world of LLMs, this guide equips you with the knowledge and tools to harness the full potential of llama.cpp.
Citation Information
Martinez, H. “llama.cpp: The Ultimate Guide to Efficient LLM Inference and Applications,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, R. Raha, and A. Sharma, eds., 2024, https://pyimg.co/iold6
@incollection{Martinez_2024_llama-cpp,
author = {Hector Martinez},
title = {llama.cpp: The Ultimate Guide to Efficient LLM Inference and Applications},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Aditya Sharma},
year = {2024},
url = {https://pyimg.co/iold6},
}
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.