Table of Contents
Sharpen Your Vision: Super-Resolution of CCTV Images Using Hugging Face Diffusers
Hello! Welcome to the 2nd part of the series on Image Super-Resolution. In the previous tutorial, we took a deep-dive into traditional ways in which we covered a few concepts around interpolation, the different methods of how to perform interpolation, and how one can go about doing them with Python. We also saw some interesting applications where this can be used to bring about results in the real world.

This tutorial will dive into one of those applications, specifically around solving for improving the clarity of real-life CCTV images.
In this tutorial, you will learn how you can perform Image Super-resolution on real-life CCTV (Closed-Circuit Television) images using Hugging Face Diffusers.
This lesson is the last of a 2-part series on Image Super-Resolution:
- Unlocking Image Clarity: A Comprehensive Guide to Super-Resolution Techniques
- Sharpen Your Vision: Super-Resolution of CCTV Images Using Hugging Face Diffusers (this tutorial)
To learn how to perform Image Super-Resolution, just keep reading.
Configuring Your Development Environment
To follow this guide, you need to have OpenCV and the Hugging Face ecosystem libraries installed on your system.
Luckily, all these libraries are pip-installable:
$ pip install roboflow diffusers accelerate huggingface_hub peft transformers datasets safetensors scipy bitsandbytes xformers -qqq
If you need help configuring your development environment for OpenCV, we highly recommend that you read our pip install OpenCV guide — it will have you up and running in minutes.
Need Help Configuring Your Development Environment?

All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code immediately on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Problem Statement
CCTV Cameras are ubiquitous around the world. They are important tools for surveillance and for maintaining safety in large public spaces or appropriate settings. But more often than not, these devices have a low resolution that fails to capture enough features of a face, vehicle, or object of interest. This can lead to those objects not being distinguishable enough for recognition or other downstream applications.

Another important reason is the factor of cost. Laying down CCTV cameras across an entire city or a large area comes with huge installation and maintenance costs. For that reason, image quality is often compromised.
Hence, our problem statement would include capturing the still image outputs of these CCTV cameras and performing super-resolution on them directly. We are going to take a look at how this can be accomplished using some current State-of-the-art techniques, and then we will implement one of them.
How Does Super-Resolution Solve This?
Using state-of-the-art super-resolution techniques, CCTV still images can be post-processed to retain enough information that can be utilized for downstream tasks. Interpolation may not be the best choice in such real-life applications, as the lack of information within the original image only compounds the problem and makes the image worse with each change/iteration.
Current super-resolution techniques draw from their knowledge of certain scenes and their general world knowledge to synthesize new information while keeping the available information center-stage. They add synthetic information that is in line with already-existing image information so as not to distort the image or make it worse off due to the inadvertent introduction of noise through this process.
State-of-the-Art Approaches
Several state-of-the-art approaches exist to Image Super-Resolution, but two of the strongest current candidates for the same are Generative Adversarial Networks and Diffusion Models. Let’s take a good look at both of them.
Generative Adversarial Networks (GANs)
Generative Adversarial Networks, introduced first by Ian Goodfellow, are among the most popular generative models available. These models describe the generation of any information as a minimax problem, wherein a “generator” tends to create data or information that is then passed to a “discriminator” that discerns whether the data it saw was generated synthetically or is part of the real data.
In this setup, the job of the Generator is to make sure that it ends up “fooling” the Discriminator, wherein it would reduce its own loss by increasing the Discriminator’s loss. On the other hand, the Discriminator’s job was to make sure it was certain that each sample it tested was perfectly classified into real or generated with 100% certainty.
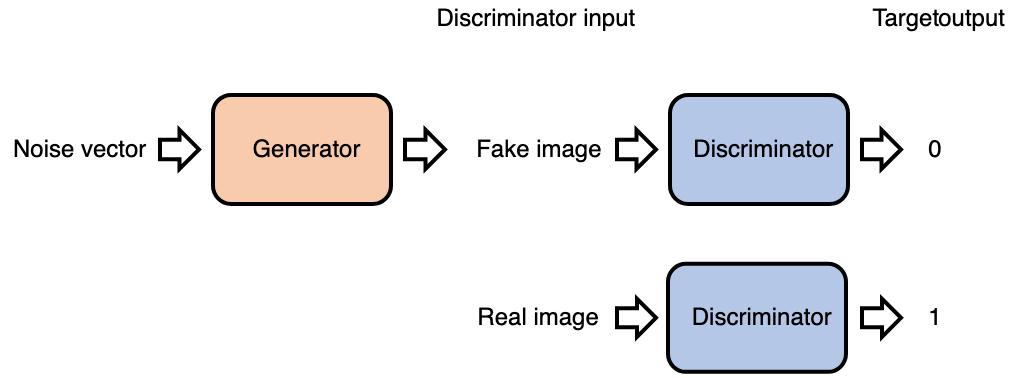
For this reason, GANs are said to be trained in a way different from how normal neural networks are trained. This “competition” setting means that the ideal case for a GAN’s training is to have a 50% certainty on the Discriminator and a 50% certainty on the Generator. This suggests that the Discriminator is absolutely confused about which samples are real or generated, while the Generator is not strong enough to confuse the Discriminator at all times completely.
Keeping this in mind is important because even though loss values can become favorable, GANs are notoriously difficult to get good qualitative outputs from. Since the loss values of the Generator and Discriminator are essentially fighting against each other, this also means that the learning capabilities (from backpropagation of loss values through the network).
The process of performing Super-Resolution using GANs involves using the Generator to simply upscale the image with Transpose Convolutions or by using any network that produces an upscaled version, compared to the original input.
Current super-resolution GAN techniques include the SRGAN, ESRGAN, and its variants. To learn more about these techniques and their varied uses, take a look at our curated blogs on the GAN architecture. If you’re interested only in Super-Resolution, though, you should check out our blogs on the SRGAN and ESRGAN, featuring from-scratch implementations!
Diffusion Models
Diffusion Models are a new class of models that have been developed and popularized because of their strong results for unconditional and conditional generation. The first version of what we call a standard Diffusion model today was the DDPM (Denoising Diffusion Probabilistic Model), which described a simple process for performing generation.
- Add Noise to an Initial Image: This entails the use of a noise scheduler. The scheduler is a function that adds random Gaussian noise to the image over multiple steps. Over time, the added noise destroys all the information in the image.
- Learn How to Remove the Noise: Using a denoising model such as a UNet, we attempt to predict a denoised version of the image for a given time step. This step is performed for the same number of times as the original noising process. In some iterations of Diffusion models, this step consists of predicting the “noise” that was added for the corresponding timestep and its subsequent subtraction against the random image obtained after adding noise. Whereas, a few iterations try to predict the noise-subtracted image directly, among many other such ideas. Doing this over time should end up yielding the original image.
- Perform Inference: Now that we have this denoising network trained, we can take any image of random noise and continue passing it through the denoising network until we get a realistic image.

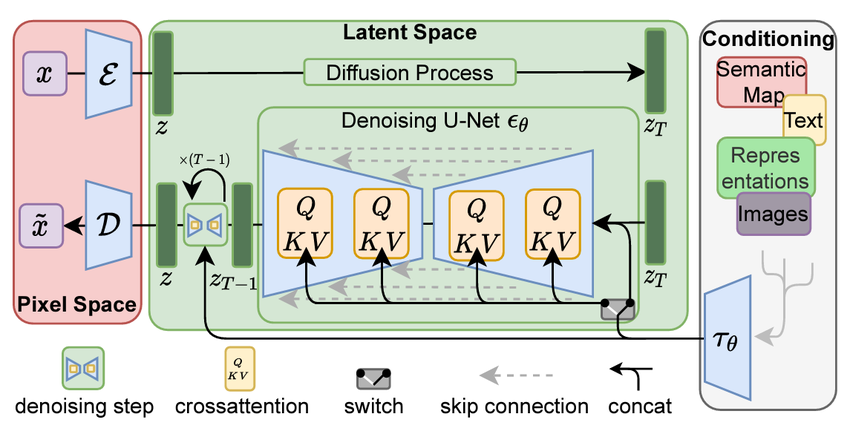
In the landscape of Diffusion models, the next generation has been the Latent Diffusion Model by Rombach et al. (2022) from LMU and Runway ML. The model we are going to utilize for our problem today is also based on the LDM approach!
The Latent Diffusion Model (LDM) approach was pioneering in how it treated the images and introduced a new technique for controlling the generation using text prompts.
LDMs implement the following approach:
- The image is encoded into a latent space representation, which is then converted into a Tensor representation. This is done by using an image encoder, which is often a Neural Network that has been previously pre-trained on large-scale image data.
- The process of adding noise is now performed on the latent space representation instead. This increases the efficiency of the operation as the number of operations per noise-step injection reduces drastically and does not depend on the image size anymore.
- The Denoising network is trained to reverse this process and finally predict a latent representation that would decode to a clean image instead of directly predicting the noise or the image itself.
- If we apply “text conditioning” (i.e., using text prompts to control the content of our image), we can pass our prompt through a text encoder, which is subsequently injected as information into the denoising network. For our current use case of super-resolution, we do not utilize this section.
- After denoising, the final latent representation is then passed through an image decoder, which is usually another Neural network. In our case, this network accepts the latent representation and produces a higher-resolution output compared to the original input.
Now that we have a fair idea of how this works, let’s see how we can implement it using Hugging Face Diffusers!
Implementing Diffusion-Based Upscaler Using Hugging Face 🤗 Diffusers
This section discusses how to use the Diffusers library to achieve image super-resolution. Currently, we will utilize real-world data taken from Roboflow, but the workflow and pipeline remain fairly standard across different kinds of data.
Loading Our Data Using Roboflow and Hugging Face Datasets
As always, we first get started with making all our imports and getting them in place. We specifically import the following libraries:
- 🤗Diffusers for model loading and inference
- Roboflow for Dataset loading
- Torch for Tensor manipulation
- Matplotlib for Image plotting
- Datasets for Dataset registration and manipulation
- Numpy for Array manipulation
import os import torch import numpy as np from roboflow import Roboflow import matplotlib.pyplot as plt from datasets import load_dataset from diffusers import LDMSuperResolutionPipeline from mpl_toolkits.axes_grid1.inset_locator import mark_inset, zoomed_inset_axes
Now, let’s also define some constants as per our future requirements. We define the device constant for automatically choosing the GPU as required. We also define the model ID, which references the unique model available on Hugging Face Hub. We also define a num_samples variable that helps us control the number of samples we’d like to generate.
device = "cuda" if torch.cuda.is_available() else "cpu" model_id = "CompVis/ldm-super-resolution-4x-openimages" num_samples = 3
We download our data from Roboflow. This can be done very quickly using their own loading script, which uses the Roboflow API (which requires a free API key) to download the dataset to your local machine.
We then use the datasets library to load the dataset in a Hugging Face-compatible dataset representation (that is also compatible with the torch.utils.data.Dataset APIs).
rf = Roboflow(api_key="")
project = rf.workspace("combine-iixr2").project("retailshop-1gysu")
version = project.version(4)
dataset = version.download("yolov5")
dataset = load_dataset(
"imagefolder",
data_dir="/content/RetailShop-4"
).shuffle(seed=42)
Defining Our Model and Inference Pipeline
Once our data has been shuffled and kept ready, we define our pipeline by importing it from Diffusers and by specifying the model ID, the data type to use for storing the weights, and the device we’d like to utilize for inference.
If you have access to an Ampere GPU or above, you can utilize the torch.bfloat16 datatype to make your model more efficient.
ldm_pipeline = LDMSuperResolutionPipeline.from_pretrained(
model_id, torch_dtype=torch.float16
# if using an Ampere-class GPU or above, use torch.bfloat16 for benefits
)
ldm_pipeline = ldm_pipeline.to(device)
We now define a runner function called pipe that basically wraps the original pipeline inference call with our own controls and only returns the images from it.
def pipe(image):
return ldm_pipeline(image, num_inference_steps=100, eta=1).images
Now that we have our data and our model, we quickly run a loop to generate the higher-resolution images. We append them to a list for quick plotting.
res_originals = []
res_outputs = []
for idx in range(0, num_samples):
item = dataset["train"][idx]
res_image = pipe(item["image"])
res_originals.append(item["image"])
res_outputs.append(res_image)
Plotting Our Results
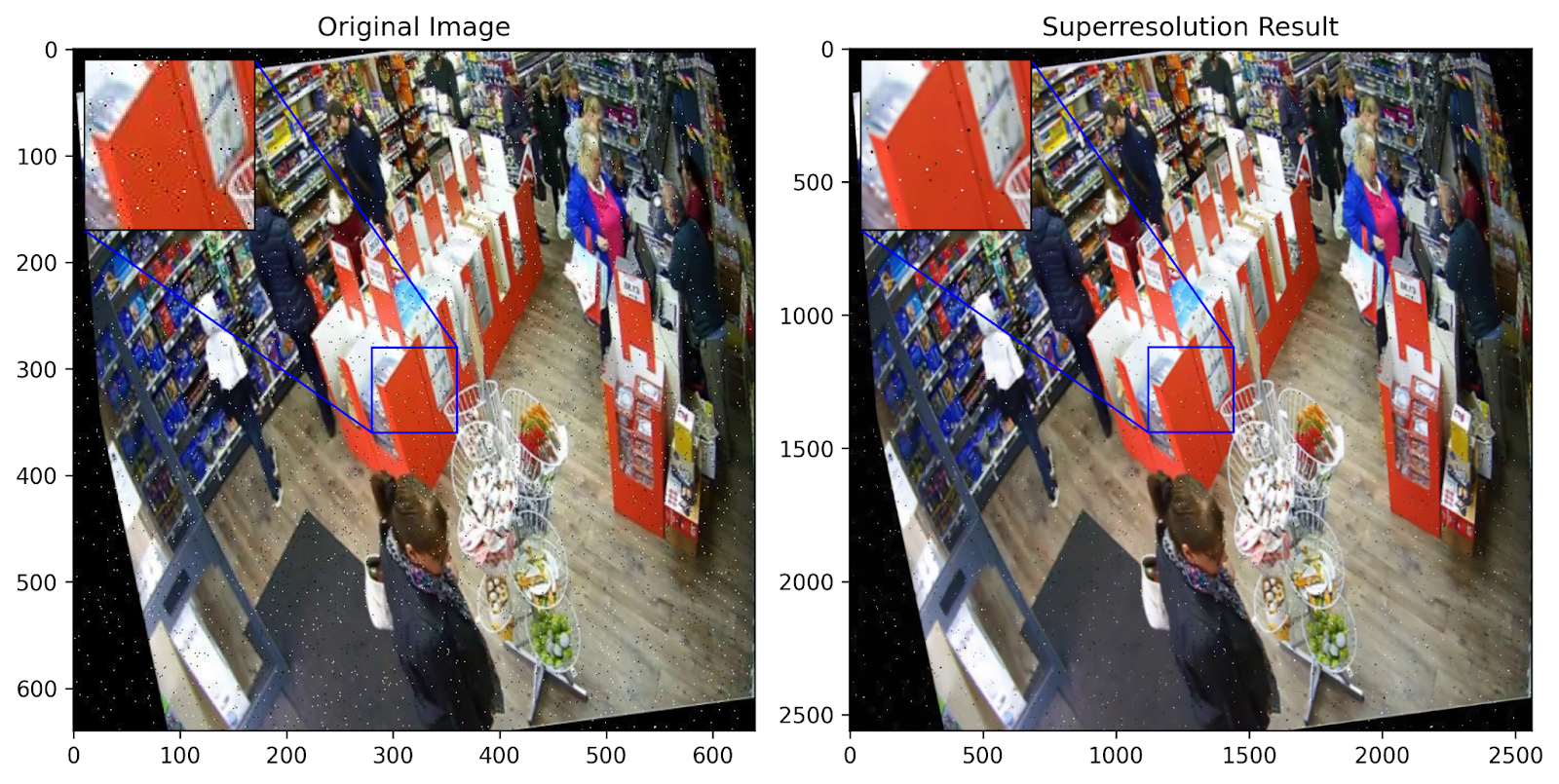
A good plotting function is always important to understand the effects of our results. Taking some inspiration from this awesome tutorial on Keras.io, we define our own plotting function that accepts the original and higher-resolution image and performs some zooming and nifty tricks to get an awesome visualization experience!
plt.rcParams["figure.figsize"] = (num_samples*5, 5) # Adjust as needed
plt.rcParams["figure.dpi"] = 300
def plot_image_with_zoom(original_img, res_img):
original_np_img = np.asarray(original_img)
res_np_img = np.asarray(res_img).squeeze(0)
original_np_img = original_np_img.astype("float32") / 255.0
res_np_img = res_np_img.astype("float32") / 255.0
fig, ax = plt.subplots(1, 2, figsize=(num_samples*5, 5), dpi=200)
ax[0].imshow(original_np_img)
ax[0].set_title("Original Image")
ax[1].imshow(res_np_img)
ax[1].set_title("Superresolution Result")
original_axins = zoomed_inset_axes(ax[0], 2, loc=2)
original_axins.imshow(original_np_img[::-1], origin="lower")
res_axins = zoomed_inset_axes(ax[1], 2, loc=2)
res_axins.imshow(res_np_img[::-1], origin="lower")
x1, x2, y1, y2 = 280, 360, 280, 360
original_axins.set_xlim(x1, x2)
original_axins.set_ylim(y1, y2)
x1, x2, y1, y2 = 1120, 1440, 1120, 1440
res_axins.set_xlim(x1, x2)
res_axins.set_ylim(y1, y2)
original_axins.set_xticks([])
original_axins.set_yticks([])
res_axins.set_xticks([])
res_axins.set_yticks([])
mark_inset(ax[0], original_axins, loc1=1, loc2=3, fc="none", ec="blue")
mark_inset(ax[1], res_axins, loc1=1, loc2=3, fc="none", ec="blue")
plt.show()
There we go! Let’s quickly use our function to plot some samples of our own.
plot_image_with_zoom(res_originals[0], res_outputs[0]) # Iterate over each of the samples to get the result
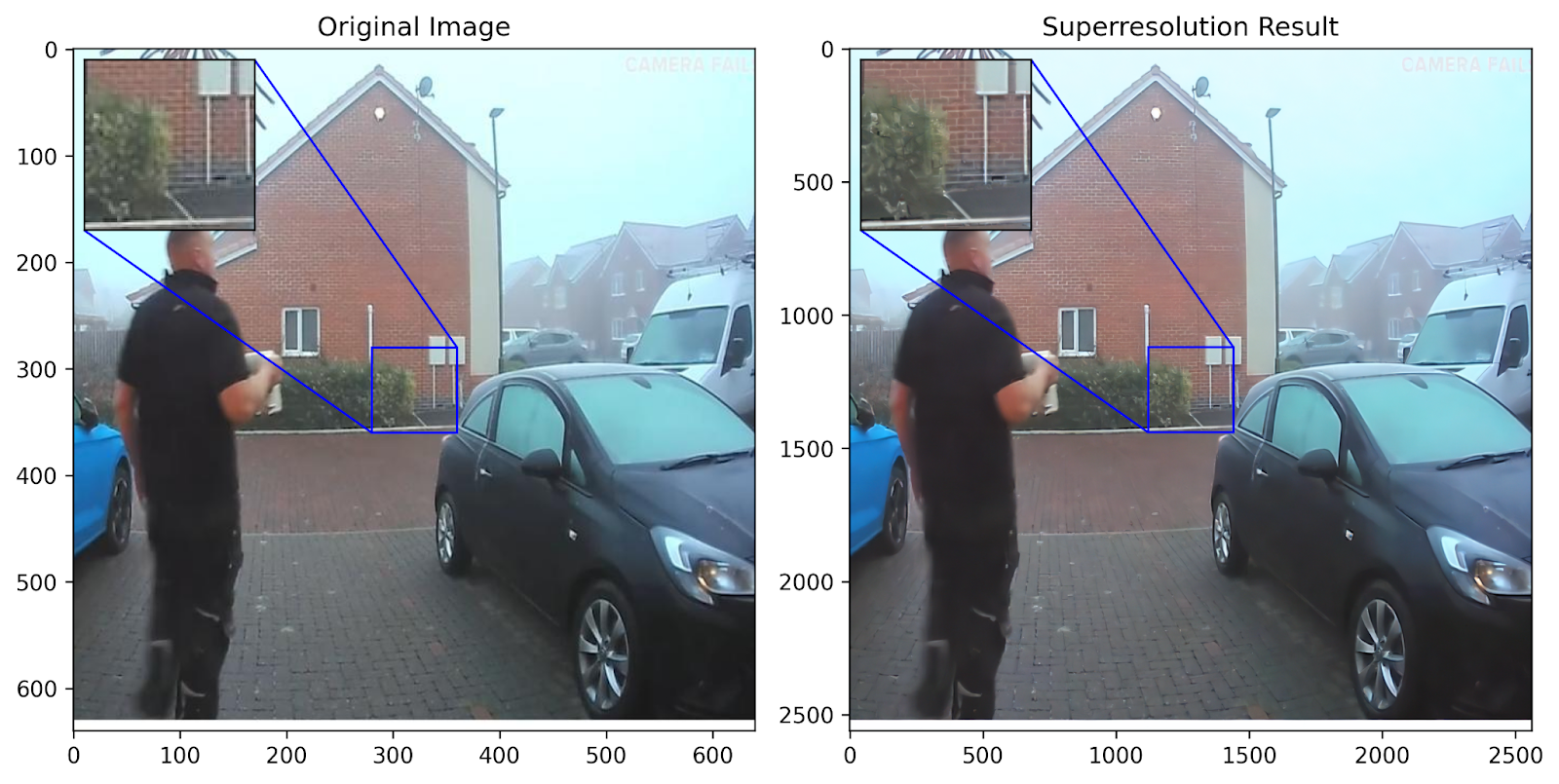
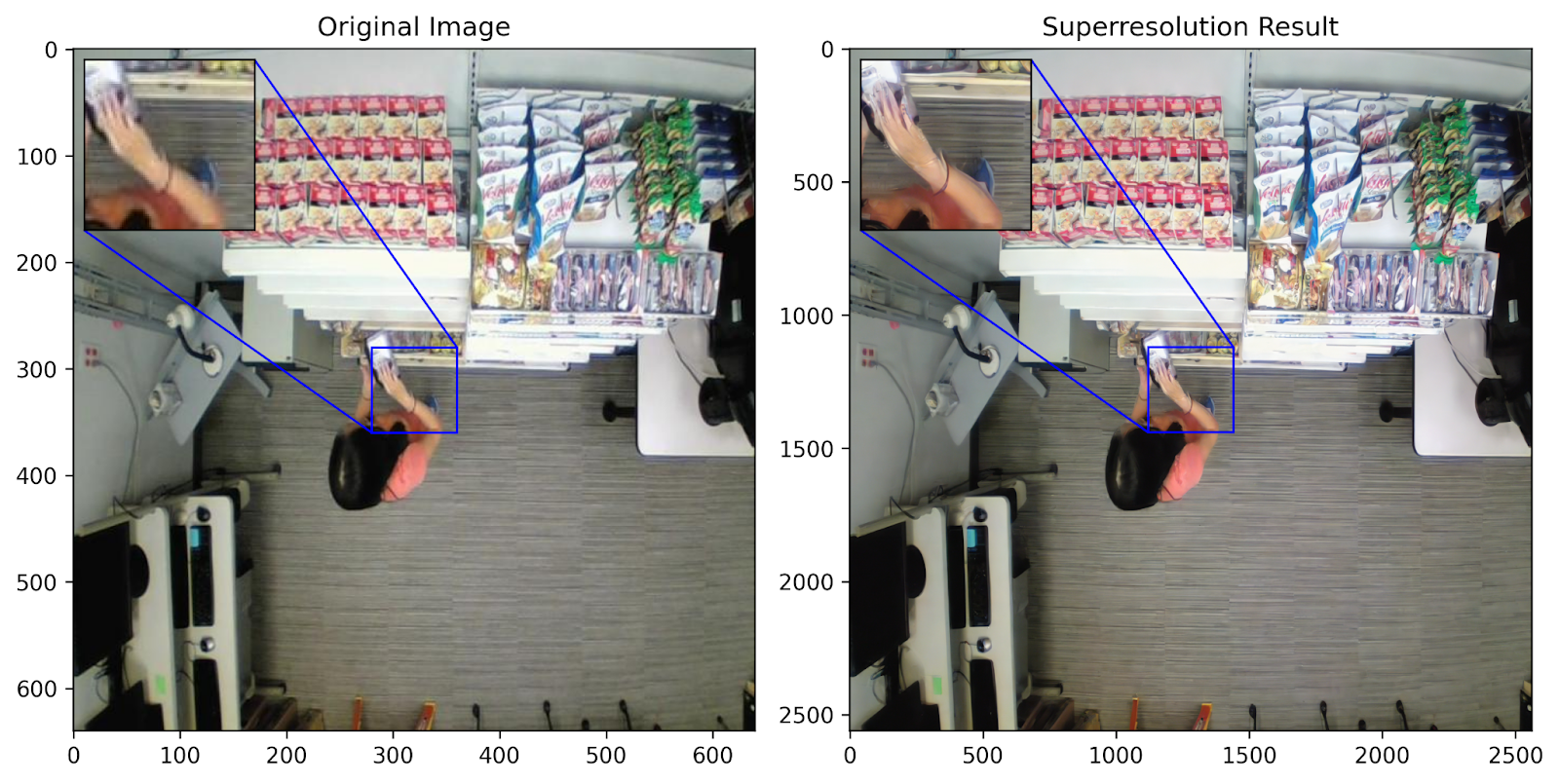
The Way Forward
Super-resolution is an exciting field. It is one of the most practical tasks available in the field of Computer Vision, which has tons of real-world applications. Advances in this field come every day, and it’s important to keep up. Some of the best resources and spaces to keep an eye on include:
- Controlled Image Super-Resolution with Diffusion Models: This process includes using text prompts while performing super-resolution. It gives a stronger signal for the model to perform the task, while allowing the user to control certain details or ideas that need to be focused on by the model.
- Approaches Involving Transformers: Transformers have shown the ability to solve long-range dependencies, meaning they are better at extrapolating information over large distances in order to make the final result coherent. For our task, this is a useful trait since the models would be able to recreate non-local features with ease.
- Fast Fourier Transform-Based Convolutions: Current techniques have also proposed using Fast Fourier Transforms as a method for feature engineering and extraction to help bring out stronger information signals from the image inputs and make the model more receptive to understanding the semantics of a scene.
- SWIN Transformer-Based Techniques: These techniques talk about the use of the Shifted-Windows approach popularized by the SWIN Transformer and how they can be utilized for sharing information over different receptive fields, which can, in turn, help build a more efficient and robust model that can make strong predictions.
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: April 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
That’s it! We just went over quite a few things together at the same time. To quickly look back, we covered the following:
- A quick overview of a problem statement involving the upscaling of CCTV images simply because of how difficult they are to interpret
- Current state-of-the-art approaches through GANs and Diffusion Models
- Implementation of a pipeline using Hugging Face Diffusers that allows us to perform super-resolution efficiently
- Plotting our results with a strong emphasis on details within the image
- How to go ahead from here into further deep-dives in depth
Thank you for following along, and see you soon for the next tutorials!
Citation Information
Mukherjee, S. “Sharpen Your Vision: Super-Resolution of CCTV Images Using Hugging Face Diffusers,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, and R. Raha, eds., 2024, https://pyimg.co/eoubf
@incollection{Mukherjee_2024_SR-CCTV,
author = {Suvaditya Mukherjee},
title = {Sharpen Your Vision: Super-Resolution of CCTV Images Using Hugging Face Diffusers},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha},
year = {2024},
url = {https://pyimg.co/eoubf},
}

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

{kind=link}
{kind=link}
Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.