
Table of Contents
- Implementing a Convolutional Autoencoder with PyTorch
- Configuring Your Development Environment
- Need Help Configuring Your Development Environment?
- Project Structure
- About the Dataset
- Configuring the Prerequisites
- Defining the Utilities
- Extracting Random Images
- Displaying Images
- Displaying Random Images
- Validating Test Data
- Getting Test Embeddings
- Visualizing Latent Space
- Getting Random Test Images Embeddings
- Visualizing Image Grid on Embeddings
- Defining the Network
- Training the Autoencoder
- Post-Training Analysis of Autoencoder
- Visualize the Latent Space of the Trained Encoder
- Visualization: Sample Uniformly from Latent Space
- Visualize the Image Grid on Embeddings
- Summary
Implementing a Convolutional Autoencoder with PyTorch
In this tutorial, we will walk you through training a convolutional autoencoder utilizing the widely used Fashion-MNIST dataset. We will then explore different testing situations (e.g., visualizing the latent space, uniform sampling of data points from this latent space, and recreating images using these sampled points).

We’re about to dive deep into this tutorial. But first things first — you’ll need to access our dataset. We could have hosted it anywhere, but we chose Roboflow and for good reasons!
Let’s rewind a bit. If we got a nickel every time a dataset disappeared from the web, we’d have enough to buy a Tesla. And oh, the frustration! Datasets disappear faster than a plate of hot cookies at a tech meetup (we’re still salty about the LISA dataset, by the way, 😠).
Roboflow swooped in and saved the day, like Batman but for datasets. It keeps our datasets safe, available, and hassle-free. So, it’s not just us having your back; Roboflow has yours too.
Ready to check out the Fashion-MNIST dataset? All you need is a Roboflow account. It’s free, easy to create, and won’t demand your firstborn in return. Think of it as your all-access pass to our tutorial.
Pause momentarily, tap into your inner data scientist, and register for your no-strings-attached Roboflow account.
➤ Yes, I’m in — I’ll Register Now
Upon completing this tutorial, you will be well-equipped with the knowledge required to implement and train convolutional autoencoders using PyTorch. Moreover, you will gain valuable insights into the capabilities and limitations of convolutional autoencoders.
Let’s embark on this thrilling journey to explore the power of autoencoders with PyTorch!
This lesson is the 2nd of a 4-part series on Autoencoders:
- Introduction to Autoencoders
- Implementing a Convolutional Autoencoder with PyTorch (this tutorial)
- Lesson 3
- Lesson 4
To learn to train convolutional autoencoders in PyTorch with post-training embedding analysis on the Fashion-MNIST dataset, just keep reading.
Configuring Your Development Environment
To follow this guide, you need to have torch, torchvision, tqdm, and matplotlib libraries installed on your system.
Luckily, all these libraries are pip-installable:
$ pip install torch>=2.0.0 $ pip install torchvision>=0.15.0 $ pip install tqdm==4.65.0 $ pip install matplotlib==3.3.2
Need Help Configuring Your Development Environment?

All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code immediately on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Project Structure
We first need to review our project directory structure.
Start by accessing this tutorial’s “Downloads” section to retrieve the source code and example images.
From there, take a look at the directory structure:
$ tree . . ├── output │ ├── embedding_visualize.png │ ├── image_grid_on_embeddings.png │ ├── model_weights │ │ └── best_autoencoder.pt │ ├── real_test_images_after_train.png │ ├── real_test_images_before_train.png │ ├── reconstruct_after_train.png │ ├── reconstruct_before_train.png │ └── training_progress │ ├── epoch10_test_recon.png │ ├── epoch1_test_recon.png │ ├── epoch2_test_recon.png │ ├── epoch3_test_recon.png │ ├── epoch4_test_recon.png │ ├── epoch5_test_recon.png │ ├── epoch6_test_recon.png │ ├── epoch7_test_recon.png │ ├── epoch8_test_recon.png │ └── epoch9_test_recon.png ├── pyimagesearch │ ├── __init__.py │ ├── config.py │ ├── network.py │ └── utils.py ├── test.py └── train.py 4 directories, 23 files
In the pyimagesearch directory, we have the following files:
config.py: This configuration file is for training the autoencoder.network.py: Hosts the convolutional autoencoder implementation.utils.py: This file contains utilities for post-training autoencoder analysis and a validation method for evaluating the autoencoder during training.
In the core directory, we have the following:
test.py: This inference script evaluates the trained autoencoder on the test dataset and conducts post-training analysis.train.py: This training script trains the vanilla autoencoder on the Fashion-MNIST dataset.output: This folder hosts the model weights, training reconstruction progress over each epoch, evaluation of the test set, and post-training analysis of the autoencoder.
About the Dataset
In this tutorial, we employ the Fashion-MNIST dataset for training our autoencoder model.
Overview
Fashion-MNIST is a dataset of Zalando’s article images consisting of the following:
- training set of 60,000 examples
- test set of 10,000 examples
Each sample is a 28x28 grayscale image associated with a label from 10 classes (Figure 2). It serves as a direct drop-in replacement for the original Fashion-MNIST dataset for benchmarking machine learning algorithms, with the benefit of being more representative of the actual data tasks and challenges.

Class Distribution
The Fashion-MNIST dataset is balanced, which means it has an equal number of samples from each class. The 10 classes are T-shirt/top, Trouser, Pullover, Dress, Coat, Sandal, Shirt, Sneaker, Bag, and Ankle boot. Each class has 6,000 images in the training set and 1,000 in the test set.
Data Preprocessing
Before training the autoencoder, the images from the dataset are preprocessed. Each image in the dataset is a 28x28 grayscale image. The pixel values fall in the range of 0 to 255. As a preprocessing step, these pixel values are normalized to fall from 0 to 1. This is achieved by dividing each pixel value by 255. This normalization helps in faster and more stable convergence during training.
Data Split
The dataset is split into two parts: a training set and a test set. The training set, which contains 60,000 images, is used to train the autoencoder, and the test set, which includes 10,000 images, is used to evaluate the model’s performance. It is essential to separate the data used for training from the data used for testing to get an unbiased measure of the model’s performance.
Configuring the Prerequisites
Before we start our implementation, let’s review our project’s configuration. For that, we will move on to the config.py script located in the pyimagesearch directory.
The config.py script sets up the autoencoder model hyperparameters and creates an output directory for storing training progress metadata, model weights, and post-training analysis plots. It also defines the class labels dictionary mapping from integer to human-readable format.
# import the necessary packages
import os
import torch
# set device to 'cpu' or 'cuda' (GPU) based on availability
# for model training and testing
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# define model hyperparameters
LR = 0.001
PATIENCE = 2
IMAGE_SIZE = 32
CHANNELS = 1
BATCH_SIZE = 64
EMBEDDING_DIM = 2
EPOCHS = 10
# create output directory
output_dir = "output"
os.makedirs("output", exist_ok=True)
Lines 2-4 import the os module, which provides functionality for operating system-dependent operations, and the torch module, a widely used deep learning framework.
On Line 8, we check if CUDA is available on our machine. If CUDA is available, the code will set DEVICE to cuda, and PyTorch will perform its computations on the GPU, which can drastically speed up training for many machine learning models. If CUDA is not available, DEVICE will be set to cpu, and PyTorch will use the CPU for its computations.
Then from Lines 11-17, the following model hyperparameters are defined:
LRis the learning rate for the model, which influences how much the model changes in response to the estimated error each time the model weights are updated.PATIENCEmight be used in early stopping during model training where training is stopped when performance on a validation dataset does not improve forPATIENCE(in this case,PATIENCEis set to2) consecutive epochs.IMAGE_SIZEdefines the height and width of the input images that the model will be trained on, which in this case are32x32pixels.CHANNELSrepresents the number of color channels in the images. In this case,CHANNELSis set to1, which suggests that the images will be grayscale. IfCHANNELSwere3, that would suggest the images are in full color (red, green, blue).BATCH_SIZEis the number of training examples utilized in one iteration. In this case, the model will look at64images at a time before updating its weights.EMBEDDING_DIMis the size of the embedding space, and it’s commonly used in models like autoencoders or embedding layers. In this case, it is set to2.EPOCHSis the number of complete passes through the entire training dataset. The model will be trained over the whole dataset10times.
On Lines 20 and 21, an output directory is created where the results from the model (e.g., saved model weights or performance plots) are stored. The os.makedirs function creates the directory specified by the first argument. The exist_ok=True argument means that if the directory already exists, the function won’t raise an error and will do nothing.
# create the training_progress directory inside the output directory training_progress_dir = os.path.join(output_dir, "training_progress") os.makedirs(training_progress_dir, exist_ok=True) # create the model_weights directory inside the output directory # for storing autoencoder weights model_weights_dir = os.path.join(output_dir, "model_weights") os.makedirs(model_weights_dir, exist_ok=True)
On Line 24, the os.path.join(output_dir, "training_progress") function creates a file path that includes the output_dir and a new directory called training_progress. This new path is stored in the variable training_progress_dir. The os.makedirs function is then used to create this new directory. Again, exist_ok=True means that the function won’t throw an error if the directory already exists.
This directory would store files related to the model’s training progress (e.g., reconstruction plots).
# define model_weights, reconstruction & real before training images path
MODEL_WEIGHTS_PATH = os.path.join(model_weights_dir, "best_autoencoder.pt")
FILE_RECON_BEFORE_TRAINING = os.path.join(output_dir, "reconstruct_before_train.png")
FILE_REAL_BEFORE_TRAINING = os.path.join(
output_dir, "real_test_images_before_train.png"
)
# define reconstruction & real after training images path
FILE_RECON_AFTER_TRAINING = os.path.join(output_dir, "reconstruct_after_train.png")
FILE_REAL_AFTER_TRAINING = os.path.join(output_dir, "real_test_images_after_train.png")
# define latent space and image grid embeddings plot path
LATENT_SPACE_PLOT = os.path.join(output_dir, "embedding_visualize.png")
IMAGE_GRID_EMBEDDINGS_PLOT = os.path.join(output_dir, "image_grid_on_embeddings.png")
# define class labels dictionary
CLASS_LABELS = {
0: "T-shirt/top",
1: "Trouser",
2: "Pullover",
3: "Dress",
4: "Coat",
5: "Sandal",
6: "Shirt",
7: "Sneaker",
8: "Bag",
9: "Ankle boot",
}
Line 33 defines the path where the best autoencoder weights will be saved as a .pt (PyTorch) file. This is done so you can load the trained model later without retraining it.
Then, we define FILE_RECON_BEFORE_TRAINING and FILE_REAL_BEFORE_TRAINING: these are paths where images will be saved before training the model. The images (or plots) are initial reconstructions from an untrained model and the corresponding real images on Lines 34-37.
On Lines 40 and 41, we define FILE_RECON_AFTER_TRAINING and FILE_REAL_AFTER_TRAINING: these are paths where images will be saved after training the model. The images (or plots) are reconstructions from the trained model and the corresponding real images.
Then on Line 44, we define the path for LATENT_SPACE_PLOT: this is the path where a plot of the embeddings in the latent space will be saved. This would be a 2D plot since the EMBEDDING_DIM is 2.
The IMAGE_GRID_EMBEDDINGS_PLOT path is defined where a plot of the image grid on embeddings will be saved on Line 45. This is a visualization where each point in the 2D latent space corresponds to an image, showing how the model groups similar images together.
From Lines 48-59, the CLASS_LABELS dictionary associates class labels (integers from 0 to 9) with their respective class names. This aids in assessing the reconstruction quality. For instance, during testing, when test images are fed into our autoencoder, these labels help identify the class of the reconstructed image since we would have a human-readable label for the test image, thereby allowing us to evaluate the reconstruction’s accuracy.
Defining the Utilities
Now that the configuration has been defined, we can determine the utilities for validating the autoencoder during training and post-training analysis plots. The utils.py script defines several functions:
extract_random_imagesto randomly select a set of random images and their corresponding labels from a PyTorch DataLoader objectdisplay_imagesto display a grid of imagesdisplay_random_imagesis used to extract a random subset of images from a DataLoader (usingextract_random_images) and potentially apply transformations (via an encoder and decoder) before displaying them.validatefunction evaluates the autoencoder after every epoch.get_test_embeddingsmethod leverages a trained decoder model to extract embeddings from images.plot_latent_spaceplots the latent space of the trained encoder model using test data.get_random_test_images_embeddingsproduces embeddings from a random set of test images using an encoder model.plot_image_grid_on_embeddingsvisualizes how the encoder has learned to represent the images from the test dataset in latent space and how these encodings are reconstructed back to the original image space by the decoder.
Extracting Random Images
# import the necessary packages
import matplotlib
import numpy as np
import torch
import torchvision
from pyimagesearch import config
matplotlib.use("agg")
import matplotlib.cm as cm
import matplotlib.colors as mcolors
import matplotlib.pyplot as plt
from matplotlib.offsetbox import AnnotationBbox, OffsetImage
from tqdm import tqdm
We start by importing several necessary packages like the following:
matplotlib: For creating static, animated, and interactive visualizations in Python. Thematplotlib.use("agg")line sets the backend of matplotlib to the ‘agg’ backend, which is a backend used for rendering into a raster format like a PNG file.numpy: It supports arrays and a collection of mathematical functions to operate on these arrays.torch: The most important library that helps create and train the autoencoder model.torchvision: This is a part of PyTorch, consisting of popular datasets, model architectures, and common image transformations for computer vision.config: This module contains various configuration parameters for our project.matplotlib.cm: This is a module for colormap handling utilities. Colormaps are used in Matplotlib to map normalized data values to colors.matplotlib.colors: This module provides classes for converting number or color arguments to RGB or RGBA.matplotlib.pyplot: This module is a state-based interface to matplotlib and provides a MATLAB-like interface.matplotlib.offsetbox: This module provides classes for creating a box around an image and creating an annotation box. It is useful for adding more detailed images or labels to a plot.tqdm: This is a fast, extensible progress bar that we will use to track the autoencoder training progress for each epoch.
def extract_random_images(data_loader, num_images):
# initialize empty lists to store all images and labels
all_images = []
all_labels = []
# iterate through the data loader to get images and labels
for images, labels in data_loader:
# append the current batch of images and labels to the respective lists
all_images.append(images)
all_labels.append(labels)
# stop the iteration if the total number of images exceeds 1000
if len(all_images) * data_loader.batch_size > 1000:
break
# concatenate all the images and labels tensors along the 0th dimension
all_images = torch.cat(all_images, dim=0)
all_labels = torch.cat(all_labels, dim=0)
# generate random indices for selecting a subset of images and labels
random_indices = np.random.choice(len(all_images), num_images, replace=False)
# use the random indices to extract the corresponding images and labels
random_images = all_images[random_indices]
random_labels = all_labels[random_indices]
# return the randomly selected images and labels to the calling function
return random_images, random_labels
The extract_random_images function randomly selects a certain number of images and their corresponding labels from a PyTorch DataLoader object. Let’s break down the function line-by-line.
On Lines 19 and 20, we initialize two empty lists, all_images and all_labels, to store the images and labels from the DataLoader:
Then from Lines 23-29 we,
- Iterate through the DataLoader, which yields batches of images and labels.
- Append each batch of images and labels to the respective lists.
- Stop the iteration if the total number of images exceeds
1000:
On Lines 32 and 33, we concatenate all the image and label tensors along the 0th dimension (i.e., the batch size dimension).
Next, we generate some random indices using num_images, which will be used to select a random subset of images and labels on Line 36.
Once we have the random_indices, we select the corresponding images and labels on Lines 38 and 39.
Finally, we return the randomly selected images and labels on Line 42.
Displaying Images
def display_images(images, labels, num_images_per_row, title, filename=None, show=True):
# calculate the number of rows needed to display all the images
num_rows = len(images) // num_images_per_row
# create a grid of images using torchvision's make_grid function
grid = torchvision.utils.make_grid(
images.cpu(), nrow=num_images_per_row, padding=2, normalize=True
)
# convert the grid to a NumPy array and transpose it to
# the correct dimensions
grid_np = grid.numpy().transpose((1, 2, 0))
# create a new figure with the appropriate size
plt.figure(figsize=(num_images_per_row * 2, num_rows * 2))
# show the grid of images
plt.imshow(grid_np)
# remove the axis ticks
plt.axis("off")
# set the title of the plot
plt.title(title, fontsize=16)
The display_images method displays a grid of images with a specific title. First, we calculate the number of rows to show all the images on Line 47.
Next, we create a grid of images using torchvision’s make_grid function on Lines 50-52. The make_grid function takes a 4D mini-batch Tensor of shape (B x C x H x W) and makes a grid of images. nrow is the number of images per row. padding is the amount of padding. normalize=True will shift/resize the images to the range of (0, 1).
On Line 55, we convert the grid to a NumPy array and transpose it to the correct dimensions. This conversion to array is required because PyTorch images are in (C x H x W) format, but matplotlib requires images in (H x W x C) format.
From Lines 58-64, we
- create a new figure with the appropriate size
- show the grid of images
- remove the axis ticks
- set the title of the plot
# add labels for each image in the grid
for i in range(len(images)):
# calculate the row and column of the current image in the grid
row = i // num_images_per_row
col = i % num_images_per_row
# get the name of the label for the current image
label_name = config.CLASS_LABELS[labels[i].item()]
# add the label name as text to the plot
plt.text(
col * (images.shape[3] + 2) + images.shape[3] // 2,
(row + 1) * (images.shape[2] + 2) - 5,
label_name,
fontsize=12,
ha="center",
va="center",
color="white",
bbox=dict(facecolor="black", alpha=0.5, lw=0),
)
# if show is True, display the plot
if show:
plt.show()
else:
# otherwise, save the plot to a file and close the figure
plt.savefig(filename, bbox_inches="tight")
plt.close()
From Lines 67-83, we add labels for each image in the grid:
- For each image, it calculates the row and column of the image in the grid.
- It retrieves the image’s label from the
config.CLASS_LABELSdictionary using its label as the key. - It then uses
plt.textto add the label’s name as text to the plot at the calculated coordinates. The text is white, centered, and placed on a semi-transparent black background for readability.
Finally, we close the function on Lines 86-91 with a condition that checks:
- If
showisTrue, the function displays the plot. - Otherwise, we save the plot to a file specified by
filenameand close the figure.
This allows you to either directly visualize the grid of images or save it to the disk for later use.
Displaying Random Images
def display_random_images(
data_loader,
encoder=None,
decoder=None,
file_recon=None,
file_real=None,
title_recon=None,
title_real=None,
display_real=True,
num_images=32,
num_images_per_row=8,
):
# extract a random subset of images and labels from the data loader
random_images, random_labels = extract_random_images(data_loader, num_images)
The display_random_images function extracts a random subset of images from a DataLoader and potentially applies transformations (via an encoder and decoder) before displaying them.
Let’s understand the parameters the function accepts:
data_loader: A DataLoader object that yields batches of images and labels.encoderanddecoder: Optional PyTorch models or functions that transform the images. If provided, the images will be passed through the encoder and decoder before being displayed.file_reconandfile_real: Optional filenames to save the reconstructed and real images.title_reconandtitle_real: Optional titles for the reconstructed and real image plots.display_real: A boolean determining whether to display the real images.num_images: The number of images to extract from the DataLoader.num_images_per_row: The number of images to display per row in the plot.
On Line 107, we call the extract_random_images function to extract a random subset of images and their corresponding labels from the DataLoader.
# if an encoder and decoder are provided,
# use them to generate reconstructions
if encoder is not None and decoder is not None:
# set the encoder and decoder to evaluation mode
encoder.eval()
decoder.eval()
# move the random images to the appropriate device
random_images = random_images.to(config.DEVICE)
# generate embeddings for the random images using the encoder
random_embeddings = encoder(random_images)
# generate reconstructions for the random images using the decoder
random_reconstructions = decoder(random_embeddings)
# display the reconstructed images
display_images(
random_reconstructions.cpu(),
random_labels,
num_images_per_row,
title_recon,
file_recon,
show=False,
)
# if specified, also display the original images
if display_real:
display_images(
random_images.cpu(),
random_labels,
num_images_per_row,
title_real,
file_real,
show=False,
)
# if no encoder and decoder are provided, simply display the original images
else:
display_images(
random_images, random_labels, num_images_per_row, title="Real Images"
)
From Lines 111-129, we check if both encoder and decoder are provided (we use them to generate reconstructions of the images):
- We set the
encoderanddecoderto evaluation mode, necessary if the models contain layers like dropout or batch normalization that behave differently during training and evaluation. - Then move the randomly selected images to the device specified in the
config(either a CPU or a GPU). - Use the
encoderto generate embeddings for the images and thedecoderto generate reconstructions of the images. - Finally, leverage the
display_imagesfunction to display the reconstructed images and, optionally, the original images. If filenames are provided, it saves the plots to these files.
Else on Lines 141-144, if no encoder and decoder is provided, we simply display the original images using the display_images function.
Validating Test Data
def validate(encoder, decoder, test_loader, criterion):
# set the encoder and decoder to evaluation mode
encoder.eval()
decoder.eval()
# initialize the running loss to 0.0
running_loss = 0.0
# disable gradient calculation during validation
with torch.no_grad():
# iterate through the test loader
for batch_idx, (data, _) in tqdm(
enumerate(test_loader), total=len(test_loader)
):
# move the data to the appropriate device CPU/GPU
data = data.to(config.DEVICE)
# encode the data using the encoder
encoded = encoder(data)
# decode the encoded data using the decoder
decoded = decoder(encoded)
# calculate the loss between the decoded and original data
loss = criterion(decoded, data)
# add the loss to the running loss
running_loss += loss.item()
# calculate the average loss over all batches
# and return to the calling function
return running_loss / len(test_loader)
The validate function is used to evaluate the performance of an encoder-decoder model (often used in autoencoders) on a test dataset.
On Lines 149 and 150, we set the encoder and decoder to evaluation mode. This is necessary because some layers in PyTorch models, such as dropout or batch normalization, behave differently during training and evaluation.
Then, on Line 153, initialize the running loss to 0.0. This will accumulate the loss for each batch in the test dataset.
At Line 156, we disable gradient calculation because it is not necessary during evaluation and can help save memory.
Lines 158-170 iterate over all batches in the test dataset. For each batch:
- Move the data to the device specified in the
config(either a CPU or a GPU). - Use the
encoderto generate embeddings for the data and thedecoderto reconstruct the original data from these embeddings. - Calculate the loss between the reconstructed and original data using the provided
criterion. - Add this loss to the running loss.
Finally, on Line 174, after iterating over all test batches, calculate the average loss by dividing the running loss by the number of batches. This gives the mean loss per batch, which is then returned to the calling function.
Getting Test Embeddings
def get_test_embeddings(test_loader, encoder):
# switch the model to evaluation mode
encoder.eval()
# initialize empty lists to store the embeddings and labels
points = []
label_idcs = []
# iterate through the test loader
for i, data in enumerate(test_loader):
# move the images and labels to the appropriate device
img, label = [d.to(config.DEVICE) for d in data]
# encode the test images using the encoder
proj = encoder(img)
# convert the embeddings and labels to NumPy arrays
# and append them to the respective lists
points.extend(proj.detach().cpu().numpy())
label_idcs.extend(label.detach().cpu().numpy())
# free up memory by deleting the images and labels
del img, label
# convert the embeddings and labels to NumPy arrays
points = np.array(points)
label_idcs = np.array(label_idcs)
# return the embeddings and labels to the calling function
return points, label_idcs
The get_test_embeddings function generates and collects the embeddings for all the images in a test dataset using an encoder model.
We start by setting the encoder to evaluation mode on Line 179. As discussed before, this is necessary because some layers in PyTorch models, such as dropout or batch normalization, behave differently during training and evaluation.
Initialize two empty lists, points and label_idcs, to store the embeddings and labels of the test images on Lines 182 and 183.
From Lines 186-196, we iterate over all the batches in the test dataset. For each batch:
- Move the images and labels to the device specified in the
config(either a CPU or a GPU). - Use the
encoderto generate embeddings for the images. - Convert the embeddings and labels to NumPy arrays and extend them to their respective lists.
- Delete the images and labels to free up memory.
On Lines 199 and 200, convert the lists of embeddings and labels to NumPy arrays.
Finally, on Line 203, we return the embeddings and labels to the calling function.
Visualizing Latent Space
def plot_latent_space(test_loader, encoder, show=False):
# get the embeddings and labels for the test images
points, label_idcs = get_test_embeddings(test_loader, encoder)
# create a new figure and axis for the plot
fig, ax = plt.subplots(figsize=(10, 10) if not show else (8, 8))
# create a scatter plot of the embeddings, colored by the labels
scatter = ax.scatter(
x=points[:, 0],
y=points[:, 1],
s=2.0,
c=label_idcs,
cmap="tab10",
alpha=0.9,
zorder=2,
)
# remove the top and right spines from the plot
ax.spines["right"].set_visible(False)
ax.spines["top"].set_visible(False)
# add a colorbar to the plot
cbar = plt.colorbar(scatter, ax=ax)
cbar.ax.set_ylabel("Labels", rotation=270, labelpad=20)
# if show is True, display the plot
if show:
# add a grid to the plot
ax.grid(True, color="lightgray", alpha=1.0, zorder=0)
plt.show()
# otherwise, save the plot to a file and close the figure
else:
plt.savefig(config.LATENT_SPACE_PLOT, bbox_inches="tight")
plt.close()
The plot_latent_space function is used to visualize the embeddings produced by the encoder in a 2D scatter plot. Each point in the plot corresponds to an image, and the point’s color indicates the image’s label. It allows you to visualize how well the encoder has learned to distinguish different classes of images based on their embeddings. If the encoder has learned well, images of the same class should have similar embeddings and thus be close to each other in the scatter plot.
On Line 208, we first use the get_test_embeddings function to generate and collect the embeddings for all the images in the test dataset.
Then, on Line 211, we create a new figure and axis for the plot.
We create a scatter plot of the embeddings on Lines 214-222. The x and y coordinates of the points are the two dimensions of the embeddings. The color of each point is determined by the label of the corresponding image.
On Lines 225 and 226, we remove the top and right spines from the plot. Then, we add a colorbar to the plot on Lines 229 and 230.
Finally, on Lines 233-240, if show is True, it displays the plot; otherwise, it saves the plot to a file and closes the figure.
Getting Random Test Images Embeddings
def get_random_test_images_embeddings(test_loader, encoder, imgs_visualize=5000):
# get all the images and labels from the test loader
all_images, all_labels = [], []
for batch in test_loader:
images_batch, labels_batch = batch
all_images.append(images_batch)
all_labels.append(labels_batch)
# concatenate all the images and labels into a single tensor
all_images = torch.cat(all_images, dim=0)
all_labels = torch.cat(all_labels, dim=0)
# randomly select a subset of the images and labels to visualize
index = np.random.choice(range(len(all_images)), imgs_visualize)
images = all_images[index]
labels = all_labels[index]
# get the embeddings for all the test images
points, _ = get_test_embeddings(test_loader, encoder)
# select the embeddings corresponding to the randomly selected images
embeddings = points[index]
# return the randomly selected images, their labels, and their embeddings
return images, labels, embeddings
The get_random_test_images_embeddings function extracts a random subset of images, their labels, and their embeddings from the test dataset. This function is useful for visualizing a subset of the images in the latent space, which can help you understand how the encoder maps images to embeddings.
We start by looping over the batch in the test dataset, and append the images and labels of each batch to the all_images and all_labels lists, respectively, on Lines 245-249.
Then, on Lines 252 and 253, we concatenate all the images and labels into a single torch tensor along the batch dimension.
We then randomly select a subset of the images and labels on Lines 256-258. The imgs_visualize parameter specifies the number of images to select.
On Line 261, we get the embeddings for all the test images using the get_test_embeddings function. We select the embeddings corresponding to the randomly selected images on Line 264.
Finally, on Line 267, we return the randomly selected images, their labels, and their embeddings.
Visualizing Image Grid on Embeddings
def plot_image_grid_on_embeddings(
test_loader, encoder, decoder, grid_size=15, figsize=12, show=True
):
# get a random subset of test images
# and their corresponding embeddings and labels
_, labels, embeddings = get_random_test_images_embeddings(test_loader, encoder)
# create a single figure for the plot
fig, ax = plt.subplots(figsize=(figsize, figsize))
# define a custom color map with discrete colors for each unique label
unique_labels = np.unique(labels)
num_classes = len(unique_labels)
cmap = cm.get_cmap("rainbow", num_classes)
bounds = np.linspace(0, num_classes, num_classes + 1)
norm = mcolors.BoundaryNorm(bounds, cmap.N)
# Plot the scatter plot of the embeddings colored by label
scatter = ax.scatter(
embeddings[:, 0],
embeddings[:, 1],
cmap=cmap,
c=labels,
norm=norm,
alpha=0.8,
s=300,
)
# Create the colorbar with discrete ticks corresponding to unique labels
cb = plt.colorbar(scatter, ticks=range(num_classes), spacing="proportional", ax=ax)
cb.set_ticklabels(unique_labels)
The plot_image_grid_on_embeddings function is essentially:
- Visualizing how the model (encoder) has learned to represent the images from the test dataset in a lower-dimensional space (latent space)
- And how the decoder reconstructs these representations back to the original image space.
The function creates a scatter plot of the latent vectors (embeddings) and overlays the reconstructed images on the scatter plot. By visualizing this information, one can better understand the quality of the learned embeddings and the effectiveness of the decoder.
Let’s now break down the code line-by-line.
On Line 275, we randomly select a subset of images and their labels from the test dataset. We generate their corresponding embeddings (latent vectors) using the provided encoder. This is done with the help of the get_random_test_images_embeddings function.
Next, on Line 278, a matplotlib figure and axes are initialized with the desired size.
Then, from Lines 281-285, a colormap is created to provide a unique color to each unique label in the subset of images. The color map is of type rainbow and is discretized into several slots equal to the number of unique labels.
A scatter plot is created with the embeddings as points on Lines 288-296. The color of each point is determined by its corresponding label. The colormap made earlier is used for this purpose.
Then, on Lines 299 and 300, a colorbar is added to the plot to show the color-label relationship. Each unique label gets a tick on the colorbar.
# Create the grid of images to overlay on the scatter plot
x = np.linspace(embeddings[:, 0].min(), embeddings[:, 0].max(), grid_size)
y = np.linspace(embeddings[:, 1].max(), embeddings[:, 1].min(), grid_size)
xv, yv = np.meshgrid(x, y)
grid = np.column_stack((xv.ravel(), yv.ravel()))
# convert the numpy array to a PyTorch tensor
# and get reconstructions from the decoder
grid_tensor = torch.tensor(grid, dtype=torch.float32)
reconstructions = decoder(grid_tensor.to(config.DEVICE))
# overlay the images on the scatter plot
for i, (grid_point, img) in enumerate(zip(grid, reconstructions)):
img = img.squeeze().detach().cpu().numpy()
imagebox = OffsetImage(img, cmap="Greys", zoom=0.5)
ab = AnnotationBbox(
imagebox, grid_point, frameon=False, pad=0.0, box_alignment=(0.5, 0.5)
)
ax.add_artist(ab)
plt.show()
From Lines 303-311,
- A grid of linearly separable points is generated in the latent space.
- The grid covers the range of the scatter plot.
- This grid is then converted into a tensor and fed into the decoder to generate image reconstructions.
- Each point in the grid represents a position in the latent space, and the decoder generates an image for each position.
Then, from Lines 314-320, each reconstructed image is overlaid on the scatter plot at its corresponding position in the latent space. This is done by
- Creating an
AnnotationBboxfor each image, which contains the image and its position, and adding it to the axes (ax). - The
OffsetImageclass creates an image box that can be added to theAnnotationBbox. - The image is scaled down by setting
zoom=0.5. Theframeon=Falseandpad=0.0parameters ensure that the image box has no frame or padding, andbox_alignment=(0.5, 0.5)centers the image at its position.
Finally, Line 323 displays the plot using plt.show().
Defining the Network
# import the necessary packages import numpy as np import torch import torch.nn as nn import torch.nn.functional as F
We start by importing the necessary packages, such as numpy for scientific computing, torch for applying the sigmoid activation function, and torch.nn for creating and training an autoencoder network. And finally, torch.nn.functional for applying a ReLU activation in the network. You could even use torch.nn.ReLU() as a replacement.
class Encoder(nn.Module):
def __init__(self, image_size, channels, embedding_dim):
super(Encoder, self).__init__()
# define convolutional layers
self.conv1 = nn.Conv2d(channels, 32, kernel_size=3, stride=2, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=2, padding=1)
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1)
# variable to store the shape of the output tensor before flattening
# the features, it will be used in decoders input while reconstructing
self.shape_before_flattening = None
# compute the flattened size after convolutions
flattened_size = (image_size // 8) * (image_size // 8) * 128
# define fully connected layer to create embeddings
self.fc = nn.Linear(flattened_size, embedding_dim)
def forward(self, x):
# apply ReLU activations after each convolutional layer
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
# store the shape before flattening
self.shape_before_flattening = x.shape[1:]
# flatten the tensor
x = x.view(x.size(0), -1)
# apply fully connected layer to generate embeddings
x = self.fc(x)
return x
As defined above, the Encoder class is a subclass of the PyTorch nn.Module class and defines the encoder part of an autoencoder. The purpose of the encoder is to take an input image and transform it into a lower-dimensional embedding or “code” that represents the essential features of the image.
On Lines 9 and 10, the initialization and super method of the Encoder class is defined:
- The
superfunction allows this class to inherit methods and attributes from its parent classnn.Module. - Three parameters are provided to the initialization method:
image_size(the height/width of the input images),channels(the number of color channels in the input images), andembedding_dim(the size of the output embeddings).
Then, from Lines 12-14, three 2D convolutional layers are defined. These layers are used to extract features from the input images. Each convolutional layer halves the height and width of its input due to the stride of 2, while increasing the number of channels.
Line 18 initializes a variable to store the shape of the output tensor before it is flattened. This will be used later to reshape the tensor during the decoding process.
On Lines 21-23, the size of the output tensor, after it is flattened, is computed, and a fully connected (linear) layer is defined. This layer will transform the flattened tensor into the final embedding.
Then on Line 25, a forward method defines the computations the encoder performs on its input. From Lines 27-29, the input is passed through each convolutional layer and then through a ReLU activation function.
Before flattening the tensor, its shape is stored for later use during decoding on Line 32.
Finally, the tensor is flattened into a 1D tensor and passed through the fully connected layer to generate the final embeddings on Lines 35-37.
In conclusion, this Encoder class defines a typical convolutional encoder for an autoencoder. The encoder takes in an image, extracts features using convolutional layers, and then generates a lower-dimensional embedding of the image using a fully connected layer.
class Decoder(nn.Module):
def __init__(self, embedding_dim, shape_before_flattening, channels):
super(Decoder, self).__init__()
# define fully connected layer to unflatten the embeddings
self.fc = nn.Linear(embedding_dim, np.prod(shape_before_flattening))
# store the shape before flattening
self.reshape_dim = shape_before_flattening
# define transpose convolutional layers
self.deconv1 = nn.ConvTranspose2d(
128, 128, kernel_size=3, stride=2, padding=1, output_padding=1
)
self.deconv2 = nn.ConvTranspose2d(
128, 64, kernel_size=3, stride=2, padding=1, output_padding=1
)
self.deconv3 = nn.ConvTranspose2d(
64, 32, kernel_size=3, stride=2, padding=1, output_padding=1
)
# define final convolutional layer to generate output image
self.conv1 = nn.Conv2d(32, channels, kernel_size=3, stride=1, padding=1)
def forward(self, x):
# apply fully connected layer to unflatten the embeddings
x = self.fc(x)
# reshape the tensor to match shape before flattening
x = x.view(x.size(0), *self.reshape_dim)
# apply ReLU activations after each transpose convolutional layer
x = F.relu(self.deconv1(x))
x = F.relu(self.deconv2(x))
x = F.relu(self.deconv3(x))
# apply sigmoid activation to the final convolutional layer to generate output image
x = torch.sigmoid(self.conv1(x))
return x
The Decoder class, similar to the Encoder class, is a subclass of the PyTorch nn.Module class and defines the decoder part of an autoencoder. The purpose of the decoder is to take an encoded lower-dimensional embedding or “code” and transform it back into the original image.
As before, we define the initialization method of the Decoder class on Line 42. The super function is called (on Line 43) to allow this class to inherit methods and attributes from its parent class nn.Module. Three parameters are provided for the initialization method:
embedding_dim: the size of the input embeddingsshape_before_flattening: the shape of the tensor before it was flattened in the encoderchannels: the number of color channels in the output images
On Line 46, a fully connected (linear) layer is defined. This layer will transform the input embeddings into a flattened tensor that has the same size as the tensor before it was flattened in the encoder.
Line 48 stores the shape before flattening it for later use in reshaping the tensor.
From Lines 51-59, three 2D transposed convolutional layers (also known as deconvolutional layers) are defined. These layers increase the tensor’s spatial dimensions (height and width) and decrease the number of channels.
Finally, in the __init__ method, a convolutional layer is defined on Line 61. This layer is used to generate the output image from the upsampled tensor.
Moving on to the forward method on Line 63, it defines the computations that the decoder performs on its input.
On Lines 65-67, the input is passed through the fully connected layer and then reshaped to match the tensor’s shape before it is flattened in the encoder.
The reshaped tensor is then passed through each transposed convolutional layer, followed by a ReLU activation function on Lines 70-72.
Finally, on Line 74, the tensor is passed through the final convolutional layer, and a sigmoid activation function is applied to generate the output image. The sigmoid function is used here because it squashes its input into the range [0, 1], which is the desired range for the pixel intensities of the output image.
Training the Autoencoder
# USAGE # python train.py # import the necessary packages import os import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from tqdm import tqdm from pyimagesearch import config, network, utils
We start by importing the necessary libraries. torch is the main library that provides multi-dimensional arrays (tensors) and various methods to manipulate them. torchvision is used to load and transform the data, and tqdm is used for displaying progress bars. The modules from the pyimagesearch package (i.e., config, network, and utils) are also imported.
# define the transformation to be applied to the data
transform = transforms.Compose([transforms.Pad(padding=2), transforms.ToTensor()])
# load the FashionMNIST training data and create a dataloader
trainset = datasets.FashionMNIST("data", train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(
trainset, batch_size=config.BATCH_SIZE, shuffle=True
)
# Load the FashionMNIST test data and create a dataloader
testset = datasets.FashionMNIST("data", train=False, download=True, transform=transform)
test_loader = torch.utils.data.DataLoader(
testset, batch_size=config.BATCH_SIZE, shuffle=True
)
Next, we set up the data transformations and load the FashionMNIST dataset for both training and testing. The images are padded and converted into PyTorch tensors. The data is loaded in batches defined in the configuration file (config.BATCH_SIZE).
Using Roboflow to Download the Dataset (Optional)
You could also use Roboflow to download the Fashion-MNIST dataset. Roboflow provides a convenient way to download datasets directly via the command line.
Note: Be sure to use your own download link, which contains a private key tied to your Roboflow account. Do not share your private key publicly.
$ mkdir fashion_mnist $ cd fashion_mnist $ curl -L -s "YOUR_ROBOFLOW_DOWNLOAD_LINK" > fashion_mnist.zip $ unzip -q fashion_mni!mkdir fashion_mnist $ !rm fashion_mnist.zip
Be sure to replace YOUR_ROBOFLOW_DOWNLOAD_LINK with the link you obtain from Roboflow.
To load the Fashion-MNIST dataset, we will use the ImageFolder dataset class from torchvision since the Roboflow method would download the Fashion-MNIST dataset into a directory.
# Define the transformation to be applied to the data
transform = transforms.Compose([
transforms.Pad(padding=2),
transforms.ToTensor()
])
# Load the training data
train_dataset = datasets.ImageFolder(root='fashion_mnist/train', transform=transform)
train_loader = torch.utils.data.DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True)
# Load the test data
test_dataset = datasets.ImageFolder(root='fashion_mnist/test', transform=transform)
test_loader = torch.utils.data.DataLoader(testset, batch_size=BATCH_SIZE, shuffle=True)
# create an encoder instance with the specified channels,
# image size, and embedding dimensions
# then move it to the device (CPU or GPU) specified in the config
encoder = Encoder(
channels=config.CHANNELS,
image_size=config.IMAGE_SIZE,
embedding_dim=config.EMBEDDING_DIM,
).to(config.DEVICE)
# pass the dummy input through the encoder and
# get the output (encoded representation)
enc_out = encoder(dummy_input.to(config.DEVICE))
# get the shape of the tensor before it was flattened in the encoder
shape_before_flattening = encoder.shape_before_flattening
# create a decoder instance with the specified embedding dimensions,
# shape before flattening, and channels
# then move it to the device (CPU or GPU) specified in the config
decoder = Decoder(config.EMBEDDING_DIM, shape_before_flattening, config.CHANNELS).to(
config.DEVICE
)
# instantiate loss, optimizer, and scheduler
criterion = nn.BCELoss()
optimizer = optim.Adam(
list(encoder.parameters()) + list(decoder.parameters()), lr=config.LR
)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer, mode="min", factor=0.1, patience=config.PATIENCE, verbose=True
)
From Lines 33-51, we create instances of the Encoder and Decoder classes defined in the network module. The model parameters like the number of channels, image size, and embedding dimension are taken from the configuration file. The encoder and decoder are moved to the device specified in the configuration file (config.DEVICE).
Then, the loss function, optimizer, and learning rate scheduler are set up from Lines 54-60. The loss function is Binary Cross-Entropy (nn.BCELoss), suitable for binary classification problems and is often used in autoencoders. The optimizer is Adam, and the learning rate scheduler is ReduceLROnPlateau.
The ReduceLROnPlateau scheduler adjusts the learning rate based on a metric. In this case, it reduces the learning rate when a metric has stopped improving. The metric is minimized (mode='min'), the learning rate is multiplied by factor (0.1 in this case) when the metric has stopped improving, and patience is the number of epochs with no improvement, after which the learning rate will be reduced.
# call the 'display_random_images' function from the 'utils' module to display
# and save random reconstructed images from the test data
# before the autoencoder training
utils.display_random_images(
test_loader,
encoder,
decoder,
title_recon="Reconstructed Before Training",
title_real="Real Test Images",
file_recon=config.FILE_RECON_BEFORE_TRAINING,
file_real=config.FILE_REAL_BEFORE_TRAINING,
)
This display_random_images utility function displays a set of random images from the test dataset before training the autoencoder. It shows both the original and the corresponding reconstructed images before training the autoencoder, as shown in Figure 3 and Figure 4.


# initialize the best validation loss as infinity
best_val_loss = float("inf")
# start training by looping over the number of epochs
for epoch in range(config.EPOCHS):
print(f"Epoch: {epoch + 1}/{config.EPOCHS}")
# set the encoder and decoder models to training mode
encoder.train()
decoder.train()
# initialize running loss as 0
running_loss = 0.0
# loop over the batches of the training dataset
for batch_idx, (data, _) in tqdm(enumerate(train_loader), total=len(train_loader)):
# move the data to the device (GPU or CPU)
data = data.to(config.DEVICE)
# reset the gradients of the optimizer
optimizer.zero_grad()
# forward pass: encode the data and decode the encoded representation
encoded = encoder(data)
decoded = decoder(encoded)
# compute the reconstruction loss between the decoded output and
# the original data
loss = criterion(decoded, data)
# backward pass: compute the gradients
loss.backward()
# update the model weights
optimizer.step()
# accumulate the loss for the current batch
running_loss += loss.item()
On Line 76, best_val_loss is initialized to infinity. This variable will keep track of the model that gives the smallest validation loss across all epochs.
The training process starts from Line 79, looping over the number of epochs specified in config.EPOCHS. encoder.train() and decoder.train() set the encoder and decoder in training mode, which is necessary because some layers (e.g., Dropout and Batch Normalization) behave differently during training and testing on Lines 82 and 83.
Before each epoch, the running_loss is reset to 0.0 on Line 86. This variable accumulates the loss over each batch within the current epoch.
Line 89 starts the loop over each batch in the training dataset. data represents the input data for the current batch, which is moved to the device specified in config.DEVICE on Line 91 (either a GPU or CPU). On Line 93, optimizer.zero_grad() resets the gradients to zero before starting to do backpropagation because PyTorch accumulates the gradients on subsequent backward passes.
Lines 96 and 97 are the forward pass of encoder and decoder. The input data is passed through the encoder to generate an encoded representation, which is then passed through the decoder to produce the reconstructed output.
Then, on Line 101, the reconstruction loss between the original data and the decoded output is then computed using the Binary Cross-Entropy (BCE) loss function specified in criterion.
Line 104 is the backward pass. The backward() function computes the gradient of the loss with respect to the model parameters, and optimizer.step() on Line 106 updates the model parameters based on the computed gradients.
The loss of the current batch (converted to a Python float using item()) is added to running_loss to accumulate the loss over the entire epoch on Line 109.
This process is repeated for each batch in the dataset and each epoch. This will train the autoencoder model by iteratively improving its ability to reconstruct the input data.
# compute the average training loss for the epoch
train_loss = running_loss / len(train_loader)
# compute the validation loss
val_loss = utils.validate(encoder, decoder, test_loader, criterion)
# print training and validation loss for current epoch
print(
f"Epoch {epoch + 1} | Train Loss: {train_loss:.4f} "
f"| Val Loss: {val_loss:.4f}"
)
# save best model weights based on validation loss
if val_loss < best_val_loss:
best_val_loss = val_loss
torch.save(
{"encoder": encoder.state_dict(), "decoder": decoder.state_dict()},
config.MODEL_WEIGHTS_PATH,
)
# adjust learning rate based on the validation loss
scheduler.step(val_loss)
# save validation output reconstruction for the current epoch
utils.display_random_images(
data_loader=test_loader,
encoder=encoder,
decoder=decoder,
file_recon=os.path.join(
config.training_progress_dir, f"epoch{epoch + 1}_test_recon.png"
),
display_real=False,
)
print("Training finished!")
Line 112 computes the average training loss for the current epoch by dividing the total accumulated loss (running_loss) by the number of batches in the training dataset (len(train_loader)).
The utils.validate() function is used to compute the validation loss on Line 115. The encoder and decoder models, the validation data loader (test_loader), and the loss function (criterion) are passed as arguments.
Then, on Lines 124-129, we check if the validation loss for the current epoch is less than the best validation loss seen so far (best_val_loss), then the current model’s weights are saved. The encoder and decoder state dictionaries (which include the model parameters) are saved in the file specified by config.MODEL_WEIGHTS_PATH.
Line 132 adjusts the learning rate based on the validation loss. The ReduceLROnPlateau scheduler multiplies the learning rate by a factor (default 0.1) whenever the validation loss does not decrease for a specified number of epochs (referred to as patience).
Finally, at the end of each epoch, a set of random images from the validation data is passed through the encoder-decoder pipeline, and the reconstructed images are displayed on Lines 135-143. This provides a visual check on how the model improves its reconstruction ability as it is trained.
The loop continues for the specified number of epochs.
Post-Training Analysis of Autoencoder
# USAGE
# python test.py
# import the necessary packages
import logging
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from tqdm import tqdm
from pyimagesearch import config, utils
from pyimagesearch.network import Decoder, Encoder
# set up logging configuration
logging.basicConfig(
level=logging.INFO, format="%(asctime)s - " "%(levelname)s - %(message)s"
)
We start by importing the necessary packages,
loggingto record events or issues that occur when running the code.osmodule that provides a way to use system-dependent functionality like reading/writing to the file system.torch,torch.nn,torch.optim: These are parts of the PyTorch library.torchis the main PyTorch library,torch.nnprovides classes for building neural networks, andtorch.optimprovides classes for optimization algorithms (e.g., SGD, Adam, etc.).torchvision: It provides access to popular datasets, model architectures, and image transformations for computer vision.tqdm: This is a third-party library for creating console progress bars.pyimagesearch: is our custom module containing the project’s utility functions, network definition, and configuration variables.Decoder,Encoder: These are imported from thenetworkmodule inpyimagesearchand represent the architecture of an autoencoder model’s Encoder and Decoder parts.
On Lines 18-20, the logging.basicConfig() function configures the logging system. The level argument is set to logging.INFO, which means the logger will handle all messages with a severity level of INFO and above. The format argument specifies the format of the log messages. In this case, each message will include the time the log was created, the severity level, and the actual log message.
# generate a random input tensor with the same shape as the input images
# (1: batch size, config.CHANNELS: number of channels,
# config.IMAGE_SIZE: height, config.IMAGE_SIZE: width)
dummy_input = torch.randn(1, config.CHANNELS, config.IMAGE_SIZE, config.IMAGE_SIZE)
# create an encoder instance with the specified channels,
# image size, and embedding dimensions
# then move it to the device (CPU or GPU) specified in the config
encoder = Encoder(
channels=config.CHANNELS,
image_size=config.IMAGE_SIZE,
embedding_dim=config.EMBEDDING_DIM,
).to(config.DEVICE)
# pass the dummy input through the encoder and
# get the output (encoded representation)
enc_out = encoder(dummy_input.to(config.DEVICE))
# get the shape of the tensor before it was flattened in the encoder
shape_before_flattening = encoder.shape_before_flattening
# create a decoder instance with the specified embedding dimensions,
# shape before flattening, and channels
# then move it to the device (CPU or GPU) specified in the config
decoder = Decoder(config.EMBEDDING_DIM, shape_before_flattening, config.CHANNELS).to(
config.DEVICE
)
# load the saved state dictionaries for the encoder and decoder
checkpoint = torch.load(config.MODEL_WEIGHTS_PATH)
encoder.load_state_dict(checkpoint["encoder"])
decoder.load_state_dict(checkpoint["decoder"])
# set the models to evaluation mode
encoder.eval()
decoder.eval()
Line 25 creates a random tensor with the same shape as the input images. This tensor is useful for fetching the tensor’s shape before it is flattened in the encoder and would be required to be passed to the Decoder model.
From Lines 30-34, an instance of the Encoder class is created. The parameters for the class (number of channels, image size, and embedding dimensions) are provided in the configuration file. After creating the instance, it’s moved to the device specified in the config file (either a CPU or a GPU) using the .to() method.
Next, on Line 38, the dummy_input tensor is passed through the encoder to get an encoded representation. It’s moved to the specified device before it’s passed to the encoder.
Line 41 retrieves the shape of the tensor before it is flattened in the encoder. This is necessary for the decoder to reshape the tensor during the decoding process correctly.
From Lines 46-48, an instance of the Decoder class is created. The parameters are the embedding dimensions, the shape before flattening, and the number of channels. Like the encoder, the decoder is also moved to the specified device.
Lines 51-53 load the saved state dictionaries (which contain the trained weights) for the encoder and decoder from the path specified in the config file.
Lastly, on Lines 56 and 57, the models are set to evaluation mode with the .eval() method. This is necessary because certain layers, like dropout and batch normalization, behave differently during training and evaluation.
# define the transformation to be applied to the data
transform = transforms.Compose([transforms.Pad(padding=2), transforms.ToTensor()])
# load the test data
testset = datasets.FashionMNIST("data", train=False, download=True, transform=transform)
test_loader = torch.utils.data.DataLoader(
testset, batch_size=config.BATCH_SIZE, shuffle=True
)
Line 60 defines a series of transformations that will be applied to the images in the dataset. The transforms.Compose function combines all transforms provided in the list. In this case, it applies a padding of 2 pixels around the image and then converts it to a PyTorch tensor.
Then on Lines 63, we load the FashionMNIST test dataset from PyTorch’s dataset library. train=False specifies that you want to load the test set. If the dataset doesn’t exist in the local directory (“data” in this case), it’ll be downloaded automatically due to download=True. When loaded, the transform=transform applies the defined transformations to the data.
Lines 64-66 wrap the dataset in a DataLoader, allowing easy iteration over the dataset and providing many other features. The batch_size is set according to the configuration file, and shuffle=True means data will be shuffled at every epoch.
logging.info("Creating and Saving Reconstructed Images with Trained Autoencoder")
# call the 'display_random_images' function from the 'utils' module to display
# and save random reconstructed images from the test data
# after the autoencoder training
utils.display_random_images(
test_loader,
encoder,
decoder,
title_recon="Reconstructed After Training",
title_real="Real Test Images After Training",
file_recon=config.FILE_RECON_AFTER_TRAINING,
file_real=config.FILE_REAL_AFTER_TRAINING,
)
Here, we generate and save a few randomly selected images from the test set, along with their corresponding reconstructions, by the trained autoencoder.
Line 68 logs the start of the image generation process.
The display_random_images function from the utils module is called on Lines 72-80.
- This function randomly selects a batch of images from the test data loader, passes them through the encoder and decoder to generate the reconstructed images, and then saves both the original and reconstructed images.
- The saved images’ specific titles and file paths are provided as parameters.
- The
title_reconandtitle_realparameters specify the titles for the reconstructed and real images, respectively. - The
file_reconandfile_realparameters specify the file paths where the images will be saved.
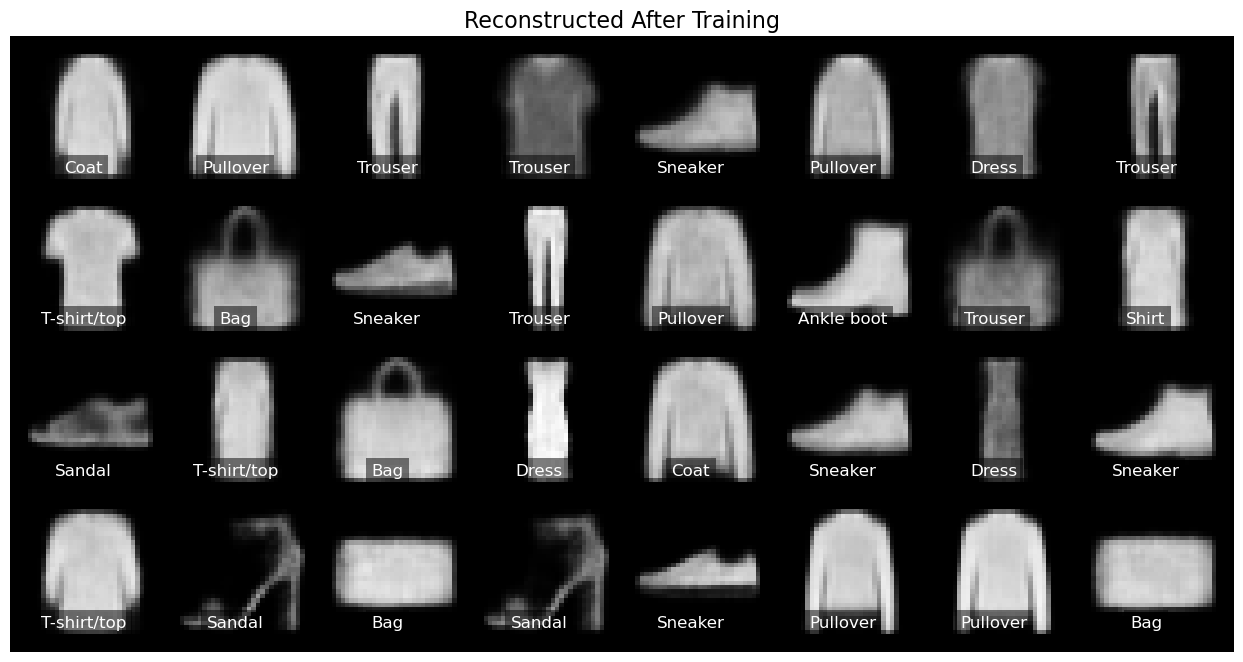
Figure 5 presents the reconstructions obtained from the autoencoder after it was trained on the test images depicted in Figure 6. The reconstructed images appear impressively well-rendered, indicating that the autoencoder manages to do a reasonably good job of reconstructing the input image. However, upon closer examination of both figures, it’s amusing that the model misinterpreted a trouser as a bag and a t-shirt 😀!

Visualize the Latent Space of the Trained Encoder
logging.info("Creating and Saving the Latent Space Plot of Trained Autoencoder")
# call the 'plot_latent_space' function from the 'utils' module to create a 2D
# scatter plot of the latent space representations of the test data
utils.plot_latent_space(test_loader, encoder, show=False)
Here, we create a 2D scatter plot of the latent space representations of the test data.
The plot_latent_space function from the utils module is called. This function takes the test data loader and the trained encoder as inputs. It then passes the test data through the encoder to generate the latent space representations, which are then plotted on a 2D scatter plot.
The show=False parameter indicates that the plot should not be displayed immediately after creation. Instead, the plot will be saved as a file for later viewing. Note that the file path for saving the plot should be specified within the plot_latent_space function.
Figure 7 shows the encoder’s latent space visualization when trained on the Fashion-MNIST dataset. We color each point in the latent space by the corresponding image’s label to produce the visualization below. Now the structure becomes very clear!

The beauty of the autoencoder is that even though the clothing labels were never shown to the model during training, the autoencoder has naturally grouped items that look alike into the same part of the latent space. For example, the orange cloud of points in the top right corner of the latent space are all different images of trousers, and the blue cloud of points toward the center top are all T-shirt/top categories.
Visualization: Sample Uniformly from Latent Space
We can create original images by picking random points within the latent space and employing the decoder to transform these back into pixel or image space.
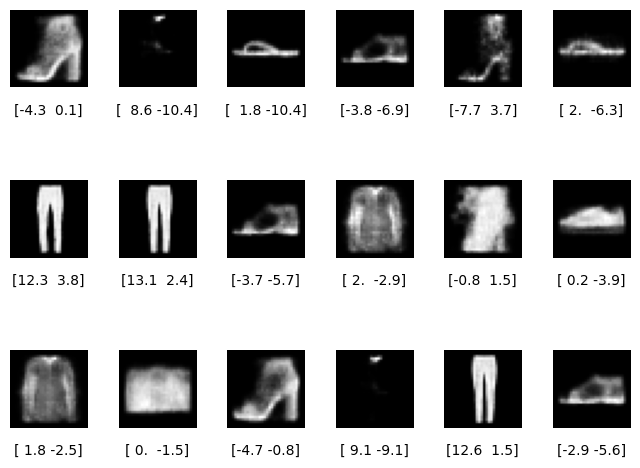
Figure 8 shows the uniformly sampled embeddings (in blue) in the latent space, with corresponding images generated by the decoder in Figure 9.
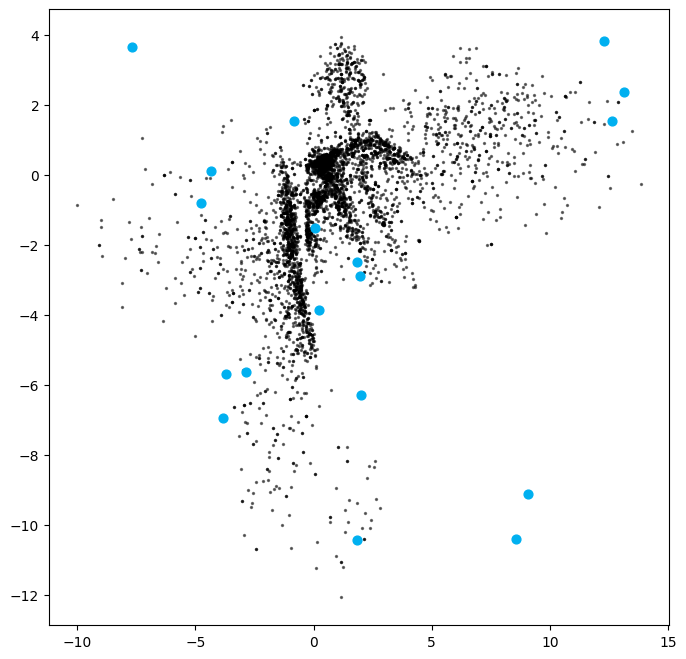
Each blue dot (in Figure 8) corresponds to one of the images shown in Figure 9, with the embedding vector displayed beneath. Observe that some generated items appear more lifelike than others. What could be the reason for this?
To address this query, let’s first note some characteristics of the overall distribution of points in the latent space, referring to Figure 7:
- Certain clothing items occupy a very small region, while others span a much larger area.
- The distribution is neither symmetrical around the point
(0, 0)nor confined. For instance, there are significantly more points with negativey-values than positive ones, and similarly, there are more points with positivex-values than negative ones. Some points even stretch to ay-value of more than .
. - There are substantial gaps between colors with scarce points.
 .
.These characteristics make the sampling from the latent space quite complex. Later, we will overlay the latent space with images of decoded points on a grid to better understand why this unbounded and asymmetrical latent space can pose challenges.
The outputs depicted below are of subpar quality in terms of their reconstruction. They come across as blurry, pixelated, and poorly formed. For example, the images in the first-row second column, and third-row fourth column, are not only ill-formed but also make it challenging to discern the corresponding reconstructed class from the Fashion-MNIST dataset.
One might attribute this poor reconstruction to the corresponding points in the latent space positioned on the boundary. However, we couldn’t expect a superior-quality reconstruction even if these points were centrally placed within the latent space. This is due to the inherent lack of continuity in the autoencoder’s latent space.
Visualize the Image Grid on Embeddings
logging.info(
"Finally, Creating and Saving the Linearly Separated Image (Grid) on "
"Embeddings of Trained Autoencoder"
)
# Call the 'plot_image_grid_on_embeddings' function from the 'utils' module
# to create a grid of images linearly interpolated
# between embedding pairs in the latent space
utils.plot_image_grid_on_embeddings(test_loader, encoder, decoder, show=False)
Finally, we create a grid of linearly interpolated images between embedding pairs in the latent space.
The plot_image_grid_on_embeddings function from the utils module is called.
- This function inputs the test data loader, the trained encoder, and the trained decoder.
- It uses the encoder to generate latent space embeddings of the test data.
- Then, it selects pairs of these embeddings and linearly interpolates between them to create new embeddings.
- These interpolated embeddings are then passed through the decoder to generate new images.
- These images are arranged on a grid, each row corresponding to one pair of embeddings.
In Figure 10, we’ve superimposed the latent space with decoded images arranged on a grid, and it’s already apparent that the decoder’s reconstructions are not meeting the desired standard.
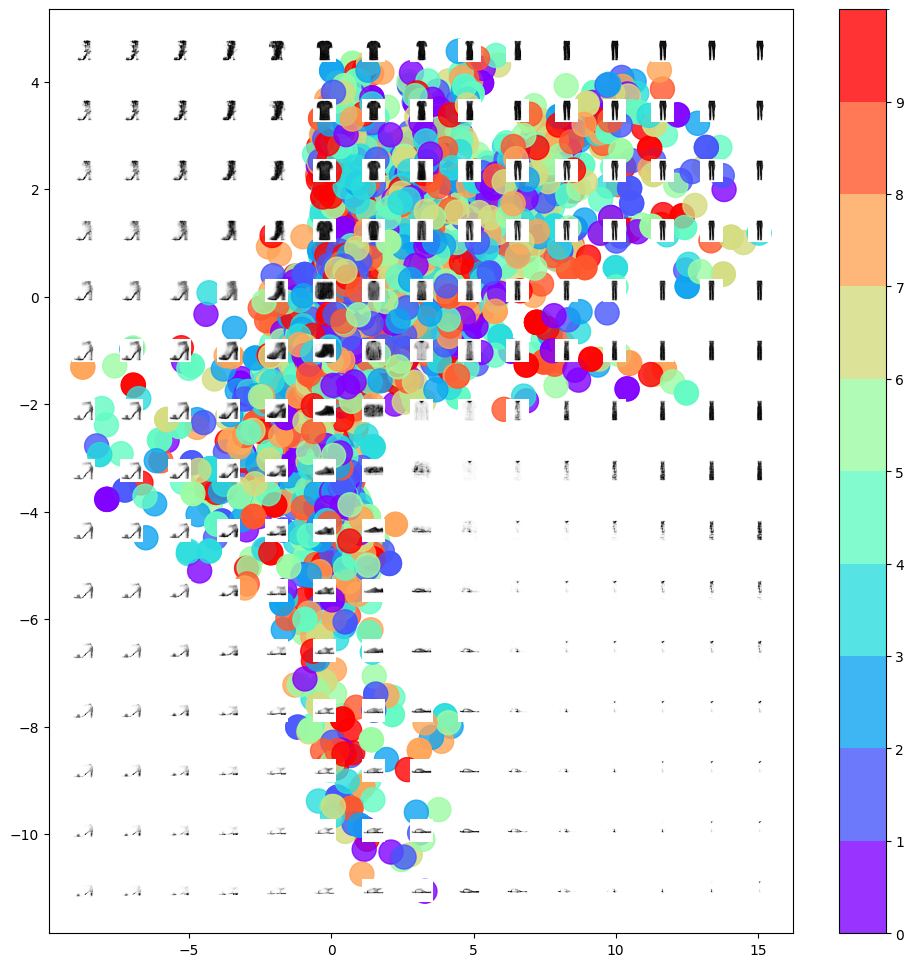
Let’s further analyze the issues and limitations of the autoencoder, as demonstrated in Figure 10:
- We observe that if we select points linearly in a confined space that we’ve defined, it’s more likely to yield something resembling a sandal (
class id 5) or trousers (class id 1) rather than a bag (class id 8). This is because the segment of the latent space dedicated to the sandal (brown, see Figure 7) is larger than that for the bag (light green). - Additionally, the question arises as to how we should select a random point in the latent space since the distribution of these points is undefined. Technically, any point on the 2D plane could be a valid choice! There’s no guarantee that points will be centered around
(0,0), which poses a challenge when sampling from our latent space. - Finally, we notice voids in the latent space where none of the original images are encoded. For instance, large white spaces are visible at the domain’s edge—the autoencoder has no incentive to ensure that points here decode into recognizable clothing items since very few images from the training set are encoded here.
Even central points may not decode into well-formed images (e.g., points where  and
and  ). In these regions, the sampled embeddings decode into an image that isn’t well formed. This happens because the autoencoder isn’t compelled to ensure the space’s continuity. For instance, even though the point
). In these regions, the sampled embeddings decode into an image that isn’t well formed. This happens because the autoencoder isn’t compelled to ensure the space’s continuity. For instance, even though the point ") might decode to provide a satisfactory sandal image, there’s no mechanism in place to ensure that the point
might decode to provide a satisfactory sandal image, there’s no mechanism in place to ensure that the point ") also yields a satisfactory sandal image.
also yields a satisfactory sandal image.
This issue is subtle in two dimensions; the autoencoder only has a small number of dimensions to work with, so it naturally compresses clothing groups together, leaving the space between clothing groups relatively small. However, this problem becomes more glaring as we use more dimensions in the latent space to generate more complex images, like faces. Suppose we allow the autoencoder free rein over how it utilizes the latent space to encode images. In that case, there will be massive gaps between groups of similar points, with no incentive for the intervening space to generate well-formed images.
In the next installment of our autoencoder series, we will explore how variational autoencoders address the above-mentioned challenges.
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: April 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
This tutorial focused on the practical aspects of an autoencoder, beginning with an overview of the dataset used, including its class distribution, data preprocessing steps, and the split between training and testing data.
While we set up the environment for implementation, the post details the configuration of prerequisites and defines essential utilities. These include functions for extracting and displaying random images, validating results, obtaining test embeddings, and plotting the latent space.
With everything set up, the post walks through the process of training the autoencoder, highlighting key considerations and potential challenges. Finally, it tests the trained autoencoder with various experiments, demonstrating its effectiveness and limitations in producing reconstructions. The post ends by showing readers how to interpret and utilize the results generated by the autoencoder.
Citation Information
Sharma, A. “Implementing a Convolutional Autoencoder with PyTorch,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, and R. Raha, eds., 2023, https://pyimg.co/t0noi
@incollection{Sharma_2023_Implementing,
author = {Aditya Sharma},
title = {Implementing a Convolutional Autoencoder with PyTorch},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha},
year = {2023},
url = {https://pyimg.co/t0noi},
}

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.