
Table of Contents
CycleGAN: Unpaired Image-to-Image Translation (Part 1)
In this tutorial, you will learn about image-to-image translation and how we can achieve it in case we have unpaired image data. Further, we will see how CycleGAN, one of the most famous efforts toward unpaired image translation, works and take an in-depth dive into the mechanism it uses to seamlessly translate images from one domain to another without needing paired image data.
Specifically, in detail, we will discuss the following in this tutorial.
- The paradigm of Unpaired Image Translation
- The idea and intuition behind CycleGAN (one of the most successful methods for unpaired image translation)
- The details and intuition behind the loss functions used by CycleGAN, especially cyclic consistency loss
- Details about the pipeline and training process of CycleGAN for unpaired image translation
This lesson is the first in a 3-part series on GANs 301:
- CycleGAN: Unpaired Image-to-Image Translation (Part 1) (this tutorial)
- CycleGAN: Unpaired Image-to-Image Translation (Part 2)
- CycleGAN: Unpaired Image-to-Image Translation (Part 3)
In the first part of this series (this tutorial), we will learn about the idea behind CycleGAN and understand the mechanism it uses to perform image translation. Further, we will understand the concept of cycle consistency that allows CycleGAN to perform image translation without needing paired data.
Next, in Part 2 of this series, we will start implementing the CycleGAN model using TensorFlow and Keras and dive into the details of the model architecture and the Apples-to-Oranges Dataset, which we will use for our unpaired image translation task.
Finally, in the last part, we will look into the training details and generate images to see our real-time CycleGAN model in action.
To learn how CycleGAN performs image-to-image translation from unpaired images, just keep reading.
CycleGAN: Unpaired Image-to-Image Translation (Part 1)
Introduction
A pivotal point in the journey toward high-quality image generation was the inception of Generative Adversarial Networks in the year 2014. We have seen in a previous tutorial how GAN can be used to generate images from arbitrary distributions. Further, in another tutorial, we have seen how we can transform the training paradigm of GANs and generate high-resolution images suited for practical applications.
This is mainly possible due to the elegant adversarial training paradigm that forms the basis for GAN training. It is worth noting that the underlying 2-player-based adversarial paradigm can be used to match arbitrary distributions by formulating it as a competition between the generator and discriminator.
This raises the question of whether such a powerful GAN framework can be used for more than just image generation. In one of our previous tutorials, we took a detailed dive into how these networks can be repurposed for translating images from one domain to another: a task called Image Translation.
However, the pix-to-pix model relies on the presence of paired data in the two domains across which image translation has to be performed. Figure 1 shows examples of paired and unpaired data.
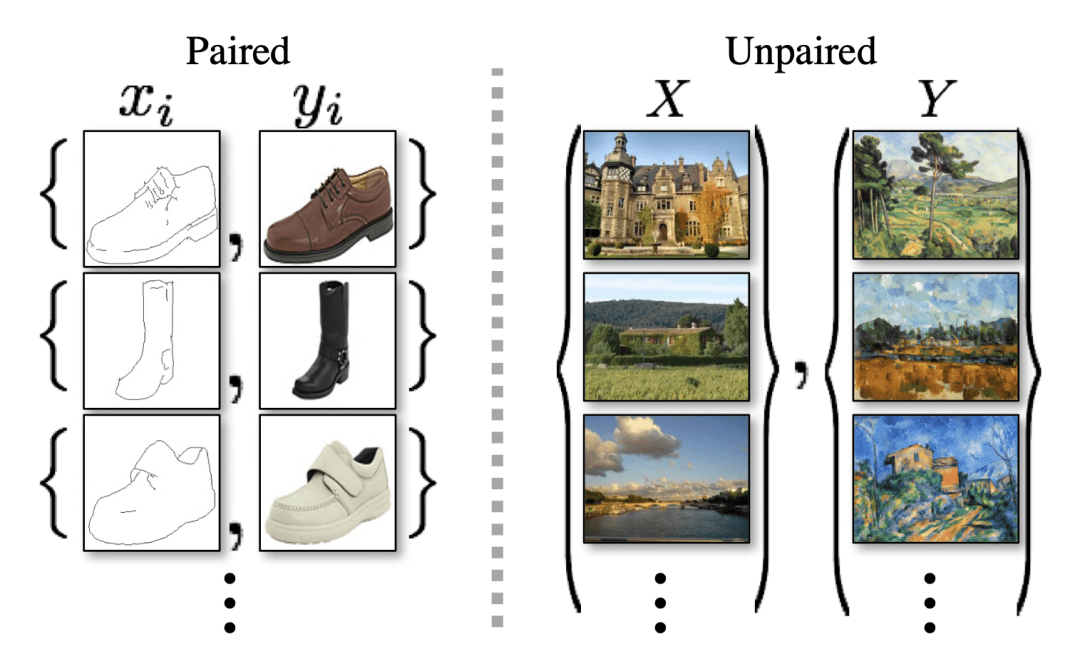
This creates a bottleneck and hinders utilization in practical scenarios where such tailored paired image datasets might not be present due to availability, practical feasibility constraints, or high annotation costs. Thus, it is natural to ask if we can still harness the capabilities of GANs for image translation without the need for paired images.
Unpaired Image Translation
The CycleGAN model marks one of the first and most elegant solutions to tackle the problem of unpaired image-to-image translations. Instead of using the conventional supervised paradigm, which requires one-to-one mapping in dataset images, it proposes to use cycle consistency loss to achieve image translation from unpaired datasets.
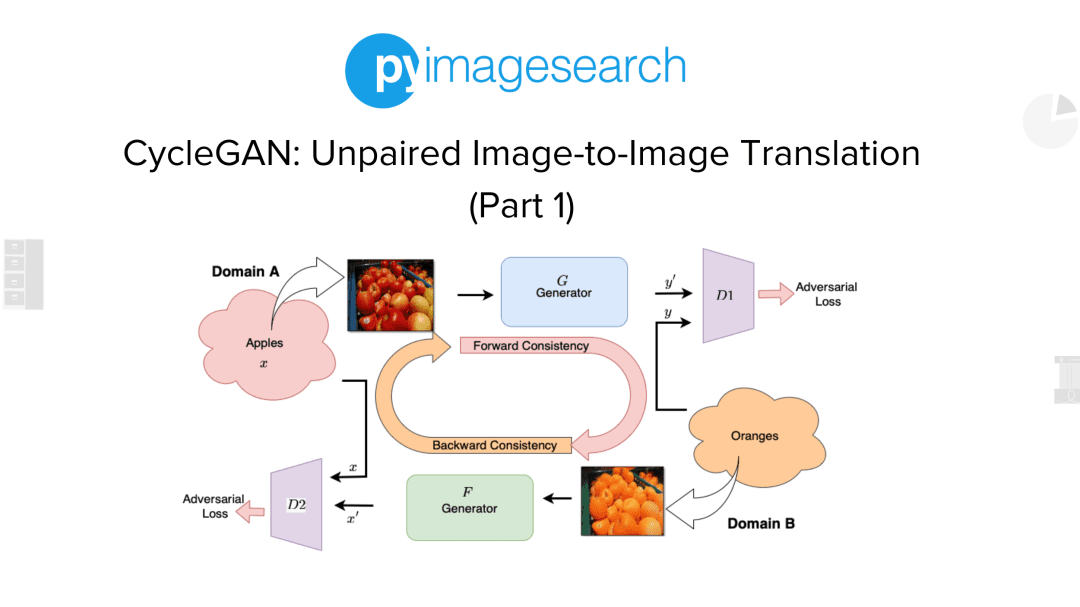
Formally, given a source domain X and a target domain Y, CycleGAN aims to learn a mapping G: X → Y such that the G(X) is the translation of the image from domain X to domain Y. Additionally, it also aims to learn a reverse mapping F: Y → X such that the F(Y) is the translation of the image from domain Y to domain X. Figure 2 shows the overview of the components of CycleGAN.
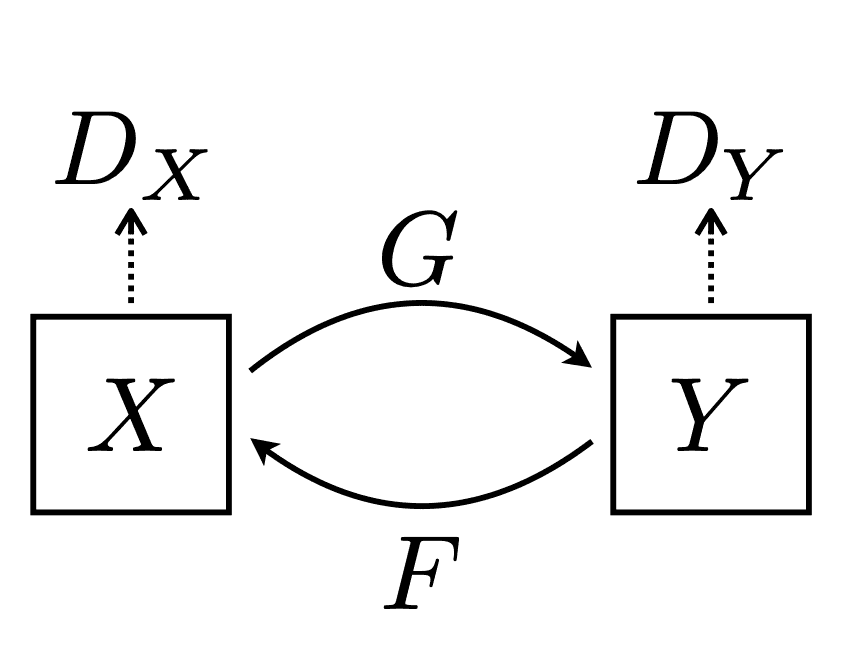
For example, this could mean translating zebra images into corresponding horse images (changing class semantics), transferring the stylistic difference from a summer view to a winter view, or predicting segmentation masks of an image scene, as shown in Figure 3.

However, it is worth noting that adversarial loss only ensures correspondence at the distribution level. Thus it can ensure that an image that belongs to the distribution of images from Domain A is translated into an image from the distribution of images from Domain B. It does not guarantee correspondence of images at the sample level.
Let us understand this with an example where we want to translate a zebra (Domain A) to a horse (Domain B). As shown in Figure 4, we see that the first is an image that belongs to the distribution of zebra images, and the second and third are images that belong to the distribution of horse images.

However, note that only the second image is the corresponding sample to the first image, and the third image (even though an image from Domain B) is not a corresponding sample for the first image. Applying adversarial loss can ensure that the translated image belongs to the distribution of images from Domain B but cannot guarantee that we get the exact corresponding sample in Domain B.
In the case of pix-to-pix, a translation of an image from Domain A to a corresponding image from Domain B was easily possible since we had paired samples from both domains. Thus, a simple supervised loss like the mean absolute error on the output of the generator and the ground-truth image in Domain B was enough to ensure that the translation of an image from Domain A results in the corresponding image in Domain B.
However, since we do not have access to corresponding paired samples in the task of unpaired image translation, we cannot use supervised loss, which makes it difficult to ensure correspondence at the sample level in the two domains.
In order to tackle this issue, the CycleGAN framework proposes to use cyclic consistency loss, which we discuss in detail later. The cyclic consistency loss ensures that the two functions learned are inverse functions of each other. Since the requirement for functions to have an inverse is that they have to be bijective (i.e., one-one and onto), it implicitly ensures a one-to-one correspondence at the sample level in the case of unpaired image translation.
CycleGAN Pipeline and Training
Now that we have understood the intuition behind CycleGAN, let us take a deeper dive into its mechanism for performing unpaired image translation.
Since we will be using the Apples-to-Oranges Dataset for our implementation in later tutorials, let us consider a case where we have to translate an image x in Domain A, that is, apples, to an image y in Domain B, that is, Oranges.
Figure 5 shows the overall pipeline of a CycleGAN.

First, we take image x from Domain A, which belongs to the distribution of images that depict apples (top). This image is passed through Generator G (as shown), which tries to output an image that belongs to the distribution of images in Domain B.
Discriminator D is an adversary against which differentiates between the samples generated by Generator G (i.e., y′) and actual samples from Domain B (i.e., y). The generator is trained against this adversary using an adversarial training paradigm. This allows the generator to generate images at the output that belong to Domain B’s distribution (i.e., oranges).
Similarly, we take an image y from Domain B, which belongs to the distribution of images that depict oranges (bottom). This image is passed through a Generator F (as shown), which tries to output an image that belongs to the distribution of images in Domain A.
Discriminator D is an adversary against which differentiates between the samples generated by Generator F (i.e., x′) and actual samples from Domain A (i.e., x). The generator is trained against this adversary using an adversarial training paradigm. This allows the generator to generate images at the output that belong to the distribution of Domain A (i.e., apples).
Finally, we notice that in addition to the two adversarial losses, we also have the forward and backward cyclic consistency losses. This ensures that:
- for each image x from Domain A, the image translation cycle should be able to bring x back to the original image
- for each image y from Domain B, the image translation cycle should be able to bring y back to the original image
Loss Formulation
Finally, to complete our understanding of the training process, let us look at the mathematical formulation of the loss functions employed by CysleGAN during training.
As discussed earlier, CycleGAN basically uses two loss functions (i.e., adversarial loss and cyclic consistency loss). Let us now take a look at the formulation of these losses.
Adversarial Loss
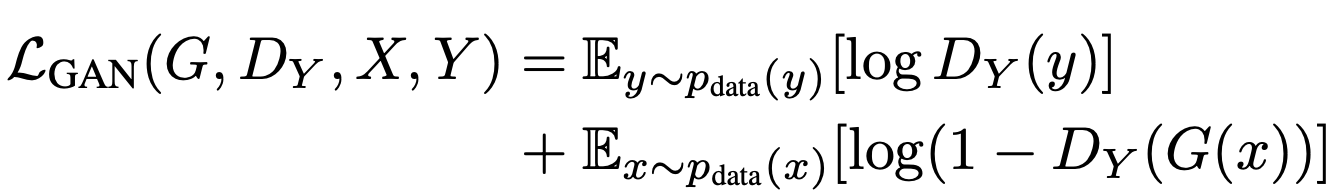
The mathematical formulation of adversarial loss is defined by Equation 1.
Here, the generator tries to generate images that look like they belong to the distribution of images from Domain B. On the other hand, the adversary or the discriminator tries to distinguish between the output of the generator (i.e., G(x)) and real samples from Domain B (i.e., Y).

Thus, at each training iteration:
- the discriminator is updated to maximize the loss (with the generator frozen)
- the generator is updated to minimize the loss (with the discriminator frozen)
Following the adversarial training paradigm, eventually, the generator learns and can generate images from the distribution of Domain B (which are indistinguishable from original samples y).

Similarly, as discussed earlier, another adversarial loss is imposed for the reverse mapping from domain Y to domain X. Here, Generator F tries to generate images that resemble the distribution of Domain A. Also, Discriminator DX tries to distinguish between the output of the generator (i.e., F(x)) and the real samples from Domain A (i.e., X).
Cycle Consistency
As we have seen earlier, the adversarial loss only ensures consistency at the distribution level. However, to ensure that corresponding samples are generated when image translation is performed, CycleGAN utilizes cyclic consistency loss at the sample level.
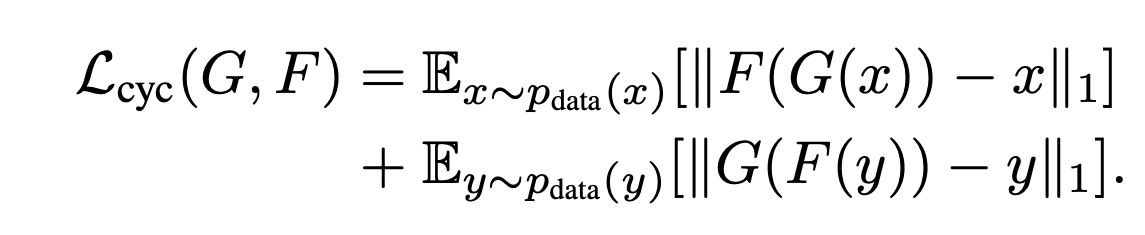
As shown in Equation 4, the cycle consistency loss consists of two terms:
- forward cyclic consistency
- backward cycle consistency
Specifically, the first term ensures that when a sample in Domain A (say x) is passed through Generator G (that transforms from Domain A to B) and then through Generator F (when it transforms it back to Domain A), the output that is F(G(x)) is the same as the original input sample x. (x → G(x) → F(G(x))  x).
x).
Similarly, the second term ensures that when a sample in Domain B (say y) is passed through Generator F (that transforms from Domain B to A) and then through Generator G (when it transforms it back to Domain B), the output that is G(F(x)) is the same as the original input sample y. (y → F(y) → G(F(y)) y).
In other words, both terms together aim to learn functions F() and G() such that they are inverses of each other. Thus, the cyclic consistency loss ensures correspondence at the sample level between sample x from Domain A and sample y from Domain B.
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: March 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this tutorial, we learned about the task of image translation and how it can be achieved when paired input images in the two domains are unavailable.
Specifically, we discussed in detail the idea behind CycleGAN and understood the paradigm of cyclic consistency, which allows CycleGAN to perform image translation from unpaired data seamlessly.
In addition, we discussed the various losses that CycleGAN used during training and understood their mathematical formulation and the role they play in the task of unpaired image translation.
Finally, we discussed the end-to-end pipeline of CycleGAN to decode the process of image translation from unpaired data.
Citation Information
Chandhok, S. “CycleGAN: Unpaired Image-to-Image Translation (Part 1),” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, R. Raha, and A. Thanki, eds., 2022, https://pyimg.co/7vh0s
@incollection{Chandhok_2022_CycleGAN,
author = {Shivam Chandhok},
title = {{CycleGAN}: Unpaired Image-to-Image Translation (Part 1)},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/7vh0s},
}

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.