
Table of Contents
- A Better, Faster, and Stronger Object Detector (YOLOv2)
- Configuring Your Development Environment
- Having Problems Configuring Your Development Environment?
- Introduction to YOLOv2
- Better
- Batch Normalization
- High-Resolution Classifier
- Convolution with Anchor Boxes
- Dimension Clusters
- Direct Location Prediction
- Fine-Grained Features
- Multi-Scale Training
- Faster
- Stronger
- Joint Classification and Detection
- Configuring the Darknet Framework and Running Inference with the Pretrained YOLOv2 Model
- Summary
A Better, Faster, and Stronger Object Detector (YOLOv2)
Detection frameworks have become increasingly fast and accurate, as seen in our last post on YOLOv1; however, most detection methods are still constrained to a small set of objects like 20 classes in PASCAL VOC and 80 classes in Microsoft COCO.

The image classification datasets have many object labels and are far easier and more inexpensive to annotate than detection. But the hope is to scale detection to the level of object classification.
And that’s partly the motivation of Redmon and Farhadi (2017) behind publishing this paper.
The other primary motivation was to fix YOLOv1’s issues:
- Detecting small objects in groups
- The localization error
- The use of anchor boxes (priors)
- Introducing accurate and efficient novel Darknet-19 architecture
In this tutorial, you will learn all about the YOLOv2 Object Detection Model and why it is called Better, Faster, Stronger. Then, we will discuss all the essential concepts mentioned in the paper in detail. Finally, run the pretrained YOLOv2 model on images and video and see it perform better than its predecessor, YOLOv1.
If you haven’t read our previous blog post on YOLOv1, we highly recommend you read that first, as understanding this post will become easier and enhance your learning experience.
This lesson is the third in our 7-part series on YOLO:
- Introduction to the YOLO Family
- Understanding a Real-Time Object Detection Network: You Only Look Once (YOLOv1)
- A Better, Faster, and Stronger Object Detector (YOLOv2) (this tutorial)
- Mean Average Precision (mAP) Using the COCO Evaluator
- An Incremental Improvement with Darknet-53 and Multi-Scale Predictions (YOLOv3)
- Achieving Optimal Speed and Accuracy in Object Detection (YOLOv4)
- Training the YOLOv5 Object Detector on a Custom Dataset
Today’s post will discuss YOLO9000, more commonly known as YOLOv2, which detects objects much faster than the already fast YOLOv1 and achieves a 13-16% gain in mAP.
To learn the theoretical concepts of the YOLOv2 object detector and see a demo of detecting objects in real-time, just keep reading.
A Better, Faster, and Stronger Object Detector (YOLOv2)
In this third part of the YOLO series, we will start with an introduction to YOLOv2.
We will discuss the Better part of YOLOv2:
- High-resolution classifier
- Batch Normalization
- Use of anchor boxes
- Dimension clusters
- Direct location prediction
- Fine-grained features
- Multi-scale resolution training
- Quantitative benchmarks, comparing YOLOv2 with YOLOv1, Faster R-CNN, and SSD
From there, we’ll discuss the Faster aspect of YOLOv2:
- Darknet-19 network architecture
- Training for Detection
- Training for Classification
We will also discuss the Stronger aspect that formed the basis for YOLO9000:
- Hierarchical Training
- Combining ImageNet and MS COCO with word tree
- Joint Training for classification and detection
Finally, we will wrap up this tutorial by installing the darknet framework on the Tesla V100 GPU and running inference on images and video with the YOLOv2 pretrained model.
Configuring Your Development Environment
To follow this guide, you need to have the Darknet Framework compiled and installed on your system. We will use AlexeyAB’s Darknet Repository for this tutorial.
We cover the step-by-step instructions on how to install the darknet framework on Google Colab. However, if you would like to configure your development environment now, consider heading to the Configuring the Darknet Framework and Running Inference with the Pretrained YOLOv2 Model section.
Having Problems Configuring Your Development Environment?

All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code right now on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides that are pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Introduction to YOLOv2
In 2017, Joseph Redmon (a Graduate Student at the University of Washington) and Ali Farhadi (a PRIOR team lead at the Allen Institute for AI) published the YOLO9000: Better, Faster, Stronger paper at the CVPR conference. The authors proposed two state-of-the-art YOLO variants in this paper: YOLOv2 and YOLO9000; both were identical but differed in training strategy.
YOLOv2 was trained on standard detection datasets like PASCAL VOC and MS COCO. At the same time, the YOLO9000 was designed to predict more than 9000 different object categories by jointly training it on the MS COCO and ImageNet datasets.
Figure 2 shows the output of the YOLO9000 model that can detect more than 9000 object classes in real-time. The output below shows that the model has learned to detect objects not in the MS COCO dataset.

YOLOv2 is the second version in the YOLO family, significantly improving accuracy and making it even faster.
The improved YOLOv2 model used various novel techniques to outperform state-of-the-art methods like Faster-RCNN and SSD in both speed and accuracy. One such technique was multi-scale training that allowed the network to predict at varying input sizes, thus allowing a trade-off between speed and accuracy.
At  input resolution, YOLOv2 achieved 76.8 mAP on VOC 2007 dataset and 67 FPS on Titan X GPU. On the same dataset with
input resolution, YOLOv2 achieved 76.8 mAP on VOC 2007 dataset and 67 FPS on Titan X GPU. On the same dataset with  input, YOLOv2 attained 78.6 mAP and 40 FPS.
input, YOLOv2 attained 78.6 mAP and 40 FPS.
They also proposed the YOLO9000 model trained on the COCO detection dataset with the ImageNet classification dataset. The idea behind this type of training was to detect object classes that did not have ground truth for object detection but use supervision from object classes with ground truth. The domain for such training is referred to as weakly supervised learning. This approach helped them achieve 16 mAP on 156 classes that did not have detection ground truth. Isn’t that great!
Better
In our previous post, we learned that YOLOv1 has a few limitations. However, it primarily suffers from localization errors that result in low recall compared to two-stage object detectors. We also observed in the inference section that the model detected the objects with not very high confidence scores.
The goal of YOLOv2 was to reduce the localization errors, thereby increasing the recall while maintaining and outperforming classification accuracy. Redmon and Farhadi’s idea was to develop an object detector that was more accurate than its predecessors and faster than them. Hence, building larger, deeper networks like ResNet or ensembling various networks did not fit the bill. Instead, with a simplified network architecture approach, they focussed on pooling many ideas from past work combined with their novel techniques. As a result, they improved YOLO’s performance in terms of both speed and accuracy.
Let’s now look at the components that made YOLO perform Better:
Batch Normalization
- Adding a batch normalization layer in all of the convolutional layers in YOLO improved the mAP by 2%.
- It helped improve the network training convergence and eliminated the need for other regularization techniques like dropout without the network getting overfitted on the training data.
High-Resolution Classifier
- In YOLOv1, an image classification task was performed as a pretraining step on the ImageNet dataset at input resolution
 , later upscaled to for object detection. Because of this, the network had to simultaneously switch to learning object detection and adjust to the new input resolution. That could have been a problem for the network weights to adapt to this new resolution while learning the detection task.
, later upscaled to for object detection. Because of this, the network had to simultaneously switch to learning object detection and adjust to the new input resolution. That could have been a problem for the network weights to adapt to this new resolution while learning the detection task. - In YOLOv2, Redmon and Farhadi perform the pretraining classification step with . Still, they fine-tune the classification network at the upscaled resolution for ten epochs on the same ImageNet data. By doing this, the network got time. It adapted its filters to work better on the upscaled resolution since it had already seen that resolution in the fine-tuning classification step (Figure 3).

- Finally, we fine-tuned the network for the detection task, and the high-resolution classifier approach increased the mAP by close to 4%. And trust me, a gain of 4% in mAP is a considerable boost.
Convolution with Anchor Boxes
- YOLOv1 was an anchor-free model that predicted the coordinates of B-boxes directly using fully connected layers in each grid cell.
- Inspired by Faster-RCNN that predicts B-boxes using hand-picked priors known as anchor boxes, YOLOv2 also works on the same principle.
- YOLOv2 removes the fully connected layers and uses anchor boxes to predict bounding boxes. Hence, making it fully convolutional.
- But what are Anchor Boxes? Anchor boxes are a set of predefined boxes with a specific height and width; they act as a guess or prior for the objects in the dataset that help optimize the network fast. They are multiple bounding boxes (priors) with different aspect ratios and sizes centered on each pixel. The goal of an object detection network is to predict a bounding box and its class label. Bounding boxes are usually represented in a normalized xmin, ymin, xmax, ymax format.
For example, 0.5 xmin and 0.5 ymin mean the top-left corner of the box is in the middle of the image. So, intuitively, we are dealing with a regression problem to get a numeric value like 0.5.
We may have the network predict four values and use Mean Square Error to compare the ground truth. However, due to the significant variance of scale and aspect ratio of boxes, researchers found that it’s tough for the network to converge if we use this “brute force” way to get a bounding box. Hence, in the Faster-RCNN paper, the idea of an anchor box was proposed.
- In YOLOv1, the output feature map was size
 and downsampled the image by 32. In YOLOv2, Redmon and Farhadi choose
and downsampled the image by 32. In YOLOv2, Redmon and Farhadi choose  as the output. There are mainly two reasons for this output size:
as the output. There are mainly two reasons for this output size: - allowing more objects to get detected per image
- an odd number of locations will have only a single center cell that will help capture large objects that tend to occupy the center of the image
 and downsampled the image by 32. In YOLOv2,
and downsampled the image by 32. In YOLOv2, - To achieve an output size of , the input resolution is changed to from , and one max-pooling layer is eliminated to produce a higher resolution output feature map.
- Unlike YOLOv1, wherein each grid cell, the model predicted one set of class probabilities per grid cell, ignoring the number of boxes B, YOLOv2 predicted class and objectness for every anchor box.
- Anchor boxes slightly decrease mAP, from 69.5mAP to 69.2mAP but increase the recall from 81% to 88%, meaning that the model has more room to improve.
- YOLOv1 predicted 98 boxes per image, but YOLOv2 with anchor boxes can predict 845 boxes (
 ) per image and even more than a thousand based on the grid size.
) per image and even more than a thousand based on the grid size.
 ) per image and even more than a thousand based on the grid size.
) per image and even more than a thousand based on the grid size. Dimension Clusters
- Unlike Faster-RCNN, which used hand-picked anchor boxes, YOLOv2 used a smart technique to find anchor boxes for the PASCAL VOC and MS COCO datasets.
- Redmon and Farhadi thought that instead of using hand-picked anchor boxes, we pick better priors that reflect the data more closely. It would be a great starting point for the network, and it would become much easier for the network to predict the detections and optimize faster.
- Using
 -means clustering on the training set bounding boxes to find good anchor boxes or priors.
-means clustering on the training set bounding boxes to find good anchor boxes or priors. - A standard -means clustering technique uses Euclidean distance as a distance metric to find cluster centers. However, in object detection, larger boxes could generate more errors compared to smaller boxes (a similar issue that YOLOv1 loss discussed) and the ultimate goal in detection is to maximize the IOU scores, independent of the size of the box. Hence, the authors changed the distance metric to:
 = 1 - \text{IOU}(\text{box}, \text{centroid})") .
. - Figure 4 shows
 was chosen as a good tradeoff between model complexity and high recall. The model complexity would increase with an increase in the number of anchors. The figure also shows the anchor boxes (in blue) with various aspect ratios, and the scale fits well in the ground-truth boxes.
was chosen as a good tradeoff between model complexity and high recall. The model complexity would increase with an increase in the number of anchors. The figure also shows the anchor boxes (in blue) with various aspect ratios, and the scale fits well in the ground-truth boxes.
 = 1 - \text{IOU}(\text{box}, \text{centroid})") .
. was chosen as a good tradeoff between model complexity and high recall. The model complexity would increase with an increase in the number of anchors. The figure also shows the anchor boxes (in blue) with various aspect ratios, and the scale fits well in the ground-truth boxes.
was chosen as a good tradeoff between model complexity and high recall. The model complexity would increase with an increase in the number of anchors. The figure also shows the anchor boxes (in blue) with various aspect ratios, and the scale fits well in the ground-truth boxes.
- The authors observed that the cluster centroids or anchors were significantly different compared to hand-picked ones. This new approach had more tall and thin boxes.
- Table 1 represents three types of prior generation strategy: Cluster Sum-Squared, Cluster IOU, Anchor Boxes (Hand-Picked Priors). We can see that the Cluster IOU with 5 anchors does a good job with an average IOU of 61.0 and performs similarly to hand-picked anchors. Further, if we increase the priors, we see a jump in the average IOU. This study concluded that using -means to generate the bounding box starts the model with a better representation and makes the network’s job easier.

Direct Location Prediction
In YOLOv1, we directly predicted the center ") locations for the bounding box, which caused model instability, especially during the early iterations. Furthermore, since in YOLOv1, there was no concept of priors, directly predicting box locations led to a more significant loss as the model had no idea about the objects in the dataset.
locations for the bounding box, which caused model instability, especially during the early iterations. Furthermore, since in YOLOv1, there was no concept of priors, directly predicting box locations led to a more significant loss as the model had no idea about the objects in the dataset.
However, in YOLOv2, with the concept of anchors, we still follow the approach of YOLOv1 and predict location coordinates relative to the location of the grid cell, but the model outputs the offsets. These offsets tell how far the priors are from the ground-truth bounding boxes. This formulation allows the model to not diverge from the center location too much. Thus, instead of predicting the direct coordinates ![[\text{xmin}, \text{ymin}, \text{xmax}, \text{ymax}]](https://b2633864.smushcdn.com/2633864/wp-content/latex/ce3/ce36888cd3a7e155434ff56e7da116e3-ffffff-000000-0.png?size=177x18&lossy=2&strip=1&webp=1 "[\text{xmin}, \text{ymin}, \text{xmax}, \text{ymax}]") , we predict offsets to these bounding boxes during the training. This works because our ground-truth box should look like the anchor box we pick with
, we predict offsets to these bounding boxes during the training. This works because our ground-truth box should look like the anchor box we pick with  -means clustering, and only subtle adjustment is needed, which gives us a good head start in training.
-means clustering, and only subtle adjustment is needed, which gives us a good head start in training.
Since they constrain the prediction coordinates relative to the grid cell location, this bounds the ground truth to fall between 0 and 1. They use a logistic (sigmoid) activation function to constrain the network’s prediction to fall in [0, 1] to match the ground-truth range.
Figure 5 shows the predicted bounding box (in blue) and the anchor box (in dotted black lines). The cell/grid responsible for predicting this blue box is the cell in the second row since the center of the bounding box falls in this particular cell.

The model predicts five bounding boxes in the output feature map at each cell (five anchors per cell). For each bounding box, the network predicts five values (shown in Figure 6): the offset, and the scale ") and the confidence score
and the confidence score  .
.
The corresponding predicted bounding box  has center
has center ") and width and height
and width and height ") . At each grid cell, the anchor/prior box has size
. At each grid cell, the anchor/prior box has size ") with its top-left corner at
with its top-left corner at ") . The confidence score is the sigmoid of the predicted output .
. The confidence score is the sigmoid of the predicted output .

More specifically,  and
and  are the
are the  -coordinate and
-coordinate and  -coordinate of the centroid relative to the top-left corner of that cell. are the width and height of the anchor box,
-coordinate of the centroid relative to the top-left corner of that cell. are the width and height of the anchor box,  and
and  are the offsets for anchor adjustment predicted by the network.
are the offsets for anchor adjustment predicted by the network.
Taking the exponent of and helps make them positive if the network predicts them as negative since width and height cannot be negative. To get the real width and height of the bounding box, we multiply the offsets with the anchor box width  and height
and height  .
.
Like in YOLOv1, here, too, the box confidence score should be equal to the IOU between the predicted box and the ground-truth box.
By constraining the location prediction, the network’s learning becomes easy, making the network more stable.
Combining dimension clusters with directly predicting the bounding box center location improves YOLOv2 by ~5% over the version with anchor boxes.
Fine-Grained Features
- YOLOv2 predicts detections over a feature map, which works well for large objects, but detecting smaller objects can benefit from fine-grained features. Fine-grained features refer to feature maps from the earlier layers of the network.
- While both Faster R-CNN and SSD (Single-Shot Detector) run the region proposal network at various layers (feature maps) in the network for multiple resolutions, YOLOv2 adds a passthrough layer.
- The passthrough layer was partly inspired by the U-Net paper in which skip-connections were used to concatenate features between the encoder and decoder layers.
- Similarly, YOLOv2 concatenates the high-resolution features with the low-resolution ones by stacking adjacent features into different channels (Figure 7). This could also be thought of as identity mappings in ResNet architecture.

- Since the higher resolution feature map spatial dimensions mismatch with the low-resolution feature map, the high-resolution map
 is turned into a
is turned into a  , which is then concatenated with the original features.
, which is then concatenated with the original features. - This concatenation expanded the feature map space to
 , providing access to fine-grained features.
, providing access to fine-grained features. - The use of fine-grained features helped improve the YOLOv2 model by 1%.
 is turned into a
is turned into a  , which is then concatenated with the original
, which is then concatenated with the original  , providing access to fine-grained features.
, providing access to fine-grained features.Multi-Scale Training
- The YOLOv1 model was trained with an input resolution of and used fully connected layers to predict bounding boxes and class labels. However, in YOLOv2, with the addition of anchor boxes, the resolution changed to ; moreover, the network had no fully connected layers. It was a fully convolutional network with just convolutional and pooling layers. Hence, the input to the network could be resized on the fly while training the model.
- The network input is varied every few iterations. After every ten batches, the network randomly chooses a new input resolution. Recall in convolution with anchor boxes we discussed the network downsamples the image by a factor of 32, so it chooses from following resolutions:
 .
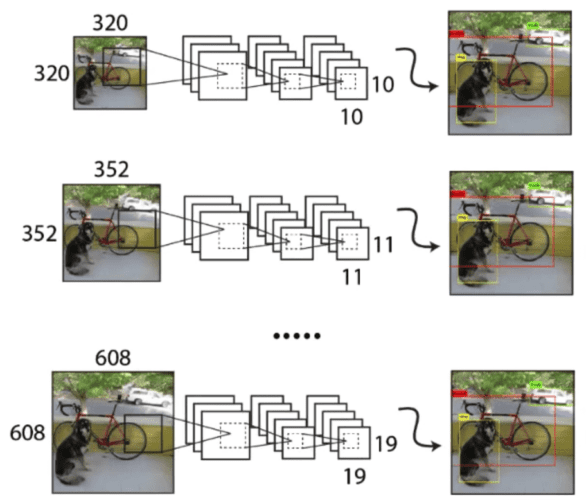
. - This type of training allows the network to predict at different image resolutions. The network predicts much faster at smaller size input offering a tradeoff between speed and accuracy. The larger size input predicts relatively slower compared to the smallest but achieves the maximum accuracy. Figure 8 shows how the end-to-end workflow looks as we vary the input to the network — the smaller the input, the lesser the number of grids at the detection head.
 .
.
- Multi-scale training also helps avoid overfitting because we force the model to be trained with different modalities.
- At test time, we can resize the images to many different sizes without modifying the trained weights.
- At low resolution
 , YOLOv2 runs at more than 90 FPS with an mAP of 69.0, close to Fast R-CNN. Of course, there’s no comparison in terms of FPS. You could use a low-resolution variant on GPU with fewer CUDA cores or older architectures and even deploy the optimized version on embedded devices like Jetson Nano, Xavier NX, Intel Neural Compute Stick.
, YOLOv2 runs at more than 90 FPS with an mAP of 69.0, close to Fast R-CNN. Of course, there’s no comparison in terms of FPS. You could use a low-resolution variant on GPU with fewer CUDA cores or older architectures and even deploy the optimized version on embedded devices like Jetson Nano, Xavier NX, Intel Neural Compute Stick. - High resolution (i.e.,
 ) outperforms all the other detection frameworks becoming the state-of-the-art detector with 78.6 mAP while still achieving more than real-time speed.
) outperforms all the other detection frameworks becoming the state-of-the-art detector with 78.6 mAP while still achieving more than real-time speed. - The multi-scale training approach produced a 1.5% boost in mAP.
- Table 2 shows the comprehensive benchmarks of YOLOv2 on various resolutions on a Titan X GPU along with other detection architectures like Faster R-CNN, YOLOv1, SSD. We can observe that almost all the YOLOv2 variants perform better in speed or accuracy than the other detection frameworks. A graphical representation of the detection benchmark on PASCAL VOC is shown in Figure 9.
 , YOLOv2 runs at more than 90 FPS with an mAP of 69.0, close to Fast R-CNN. Of course, there’s no comparison in terms of FPS. You could use a low-resolution variant on GPU with fewer CUDA cores or older architectures and even deploy the optimized version on embedded devices like Jetson Nano, Xavier NX, Intel Neural Compute Stick.
, YOLOv2 runs at more than 90 FPS with an mAP of 69.0, close to Fast R-CNN. Of course, there’s no comparison in terms of FPS. You could use a low-resolution variant on GPU with fewer CUDA cores or older architectures and even deploy the optimized version on embedded devices like Jetson Nano, Xavier NX, Intel Neural Compute Stick.

Faster
Till now, we discussed how YOLOv2 makes object detection accurate by using various techniques like anchor boxes, batch normalization, high-resolution classifiers, dimension clusters, etc. But what about the speed? That’s what we will discuss in this section of the post.
Many applications that involve object detection like autonomous driving, robotics, video surveillance require real-time performance and rely on low latency predictions. To maximize the speed, YOLOv2 was designed to be fast from the ground level.
Redmon and Farhadi do a detailed comparative study between Darknet-19 (used by YOLOv2) and other classification architectures in terms of speed, accuracy, and FLOPs (floating-point operations) shown in Table 3 and show their architecture does the best in terms of both speed and accuracy.

VGG-16 has been the go-to feature extractor for most detection frameworks; it is a robust and accurate image classification network but requires a massive amount of floating-point operations (30.95 billion FLOPs) for a single forward pass at  image resolution. The YOLOv1 architecture used a custom architecture inspired by the GoogLeNet network. As we can see from Table 3, the YOLOv1 extraction module is much faster and more accurate than VGG-16 and only uses 8.52 billion operations for a single pass.
image resolution. The YOLOv1 architecture used a custom architecture inspired by the GoogLeNet network. As we can see from Table 3, the YOLOv1 extraction module is much faster and more accurate than VGG-16 and only uses 8.52 billion operations for a single pass.
ResNet-50 is the slowest among all but achieves the best Top-1 and Top-5 accuracy; people love the family of ResNets. One important point to note is that ResNet uses less than one-third of the FLOPs compared to VGG-16 but still achieves lower FPS which means FLOPs are not directly proportional to FPS. Moreover, ResNet-50 has much more layers than VGG-16, it has fewer filters per layer, not saturating the GPU, and you end up doing a lot more work in transferring data between layers that adds to the time making ResNet slower. Hence, speed is not just FLOPs.
Darknet-19
Darknet-19 is a new classification architecture proposed as the base of object detection, the summary of which is shown in Figure 10.

- It was inspired mainly by the prior work; similar to VGG-16, it used
 filters and doubled the number of channels after every pooling step utilizing a total of 5 pooling layers.
filters and doubled the number of channels after every pooling step utilizing a total of 5 pooling layers. - Instead of fully connected layers, they used global average pooling to make predictions and
 filters to compress the feature representation between convolutions.
filters to compress the feature representation between convolutions. - As discussed earlier, we used batch normalization to stabilize the training, regularize the model, and speed up the convergence.
- A fully convolutional model with 19 convolutional layers and five max-pooling layers was designed.
Training for Classification
As discussed previously, we trained the Darknet-19 network in a High-Resolution Classifier fashion. The network was initially trained on the ImageNet 1000 class dataset for 160 epochs at image resolution using stochastic gradient descent with a learning rate of 0.1. Then, various data augmentation techniques like random crops, exposure shifts, hue, and saturation were applied. As a result, the network achieved Top-1 accuracy of 72.9% and Top-5 accuracy of 91.2% with only 5.58 billion FLOPs.
The same network was fine-tuned at a larger resolution ( ) with the same parameters for only ten epochs with a learning rate of 0.001. Again, the model performed better than the 224 resolution achieving Top-1 accuracy of 76.5% and Top-5 accuracy of 93.3%.
) with the same parameters for only ten epochs with a learning rate of 0.001. Again, the model performed better than the 224 resolution achieving Top-1 accuracy of 76.5% and Top-5 accuracy of 93.3%.
Training for Detection
Redmon and Farhadi modified the Darknet-19 network for the object detection task. They removed the last convolutional layer along with average pooling and softmax and replaced the convolutional layer with three  convolutional layers with 1024 filters. Followed by a
convolutional layers with 1024 filters. Followed by a  convolutional layer to convert
convolutional layer to convert  (input resolution of downsampled to
(input resolution of downsampled to  ) with the number of outputs required for detection, that is,
) with the number of outputs required for detection, that is,  (five boxes predicted at each grid with each box having four box coordinates, one objectness score, and 20 conditional class probabilities per box so 125 filters).
(five boxes predicted at each grid with each box having four box coordinates, one objectness score, and 20 conditional class probabilities per box so 125 filters).
The network was trained for 160 epochs with a learning rate of 0.001. This decayed the learning rate by a factor of 10 at 60 and 90 epochs. The same training strategy is used for training on both MS COCO and PASCAL VOC datasets.
Figure 11 shows the object detection architecture with the base network shown in dotted lines, pretrained with imagenet weights. As learned before, we add a passthrough layer from block 5 of Darknet-19 to the second to last convolutional layer so that the model learns fine-grained features and performs well on smaller objects.

Congratulations on making it here! You learned all the significant contributions this paper made to build a state-of-the-art real-time object detector YOLOv2. The next and the final theoretical section is optional since it doesn’t discuss much object detection per se, so feel free to skip it and go directly to the inference section.
Stronger
The motivation of this final section comes from the fact that there are far more labels in the image classification datasets than object detection datasets since drawing boxes on images for object detection is a lot more expensive than labeling images for classification.
Figure 12 shows that the MS COCO object detection dataset has only 100K images with 80 classes, while the ImageNet dataset has 14 million images with over 22K classes. That’s a huge difference. And this is more than a reason to leverage the classification dataset to solve object detection problems.

The COCO dataset has common and general objects with coarse-grained labels like a cat, dog, car, bicycle, etc. On the other hand, the ImageNet dataset is vast and has fine-grained labels like a Persian cat, airbus, and American twinflower.
Hence, the paper proposed an approach to combine object detection and classification datasets and jointly learn a much larger spectrum of classes than just 80 (in MS COCO). Redmon and Farhadi called this model YOLO9000 because it was trained to detect over 9000 object categories. The idea was that the object detection labels would learn detection-specific features like bounding box coordinates, objectness score, and classifying common objects (in MS COCO). In contrast, the images with only class labels (from ImageNet) would help expand the number of categories it can detect.
Figure 13 shows the MS COCO and ImageNet class representation in a tree format where we usually apply a softmax function over all these classes to compute the final probability. The softmax function assumes that the datasets’ classes are mutually exclusive; for example, you cannot apply softmax to output probabilities for classes with both cat and a Persian cat since the Persian cat belongs to the parent class cat. A Persian cat image could also be classified as a cat.

Initially, the authors thought they could merge both the datasets (shown in Figure 14) and do joint training. When the network is fed images labeled for detection, it backpropagates with the complete YOLOv2 loss function. When it is fed images labeled for classification, only the loss from classification-specific parts is backpropagated.

However, Redmon and Farhadi believe that the above approach poses a few challenges: simply merging the two datasets would defy the purpose of using a softmax layer for classification as the classes would no longer remain mutually exclusive. For example, given an image of a bear, the network would be confused whether to assign the image a COCO label of “bear” or the ImageNet label of “American black bear.”
Hierarchical Classification
To solve the merging problem of ImageNet labels with MS COCO, Redmon and Farhadi leverage the hierarchical tree structure with reference to WordNet from which ImageNet labels were formed (Figure 15). For example, in WordNet, “Norfolk terrier” and “Yorkshire terrier” are both hyponyms of “terrier,” which is a type of “hunting dog,” which is a type of “dog,” which is a “canine,” etc.

WordNet is a database of semantic relations between words. It links words into semantic relations, including synonyms, hyponyms, and meronyms. Nouns, verbs, adjectives, and adverbs are grouped into synonyms, called synsets (also known as a set of synonyms), each expressing a distinct concept. A hyponym is a word or phrase whose semantic field is more specific than its hypernym. The semantic field of a hypernym, also known as a superordinate, is broader than that of a hyponym. For example, pigeons, crow, eagle, and seagull are all hyponyms of bird, their hypernym.
Most approaches to classification assume a flat structure to the labels; however, for combining datasets, the structure is precisely what we need. But WordNet is structured as a directed graph, not a tree, and graphs tend to be more connected and complex than trees. For example, a “dog” is both a type of “canine” and a type of “domestic animal.” So instead of using a complete graph structure, a simplified hierarchical tree is built from the concepts in ImageNet.
The WordNet was cleaned up and converted into a tree structure by considering the words for which images were present in the dataset, which resulted in a word tree that described physical objects.
More specifically, the following steps are performed to build the tree:
- Visual nouns in ImageNet are observed, and we follow their paths through the WordNet graph to the root node. Here the root node is the “physical object.”
- Synsets that just have one path through the graph are added first to the tree.
- Then we iteratively observe the concepts we are left with and add the paths that grow the tree by as minute as possible (if a concept has two paths to the root, one having five edges and the other having three edges, we’ll choose the latter).
This results in a WordTree, a hierarchical model of visual concepts. The classification is performed in the WordTree hierarchy. We predict conditional probabilities at every node of each hyponym given that synset. So, for example, at the “terrier” node, we predict:
Pr(Norfolk terrier | terrier)
Pr(Airedale terrier | terrier)
Pr(Sealyham terrier | terrier)
Pr(Lakeland terrier | terrier)
…
A Darknet-19 model is trained on WordTree built using the 1000 classes from ImageNet. The WordTree has 1000 leaf nodes corresponding to the original 1K labels plus 369 nodes for their parent classes.
The model predicts a vector of 1369 values and calculates the softmax over all synsets that are hyponyms of the same concept (see Figure 16). Most ImageNet models use one large softmax layer to predict a probability distribution over 1000 classes. However, in WordTree, multiple softmax operations are performed over co-hyponyms like head, hair, vein, mouth, so all the hyponyms of synset body are one softmax calculation.

Using the same Darknet-19 model with the same parameters but with hierarchical training, the model achieves 71.9% Top-1 accuracy and 90.4% Top-5 accuracy. Now the same idea is applied for object detection. The detector predicts the bounding box and tree of probabilities, using the highest confidence synset at every split until we reach a threshold and predict that node as an object class.
Figure 17 shows an example of using WordTree to combine the labels from ImageNet (specific concepts: lower nodes and leaves) and COCO (general concepts: higher nodes). WordNet is highly diverse, so we can use this technique with most datasets. Blue nodes are COCO labels, and red nodes are ImageNet labels.

Joint Classification and Detection
Now that we have combined both datasets (containing 9418 classes), we can jointly train the YOLO9000 model on classification and detection.
For the joint training, only 3 priors instead of 5 were considered to limit the output size. In addition, the ImageNet detection challenge dataset was added for evaluating the YOLO9000 model.
The training of YOLO9000 is performed in two ways:
- When the network sees the detection image, the complete YOLOv2 loss is backpropagated (i.e., bounding box coordinates, objectness score, classification error) (Figure 18).

- For classification images, the network backpropagates classification and objectness loss (Figure 19). The objectness loss is computed by assuming that the predicted bounding box overlaps with the ground-truth box by at least 0.3 IOU. To backpropagate the classification loss, the bounding box with the highest probability for that class is found, and the loss is computed on just its predicted tree.

Evaluating the YOLO9000
The model is evaluated on the ImageNet detection task. The evaluation dataset has 44 object categories in common with MS COCO, meaning it has seen very few object categories for detection since the majority of the test images are for image classification. Despite that, the YOLO9000 model achieves 19.7 mAP overall with 16.0 mAP on the 156 objects classes the network has never seen the labeled detection data for during the training.
Redmon and Farhadi found that the joint YOLO9000 model did well on the new species of animals but struggled with learning categories like clothing and equipment. And the reason is COCO has a lot of labeled data for animals compared to clothing and equipment; in fact, it does not have bounding box labels for any clothing category, so this performance drop is apparent.
Now that we have covered a lot of ground on YOLOv2 and YOLO9000, let’s move on to running the inference on the YOLOv2 model in the darknet framework pre-trained on the PASCAL VOC dataset.
Configuring the Darknet Framework and Running Inference with the Pretrained YOLOv2 Model
In our previous post on YOLOv1, we had learned to configure the darknet framework and ran inference with the pretrained YOLOv1 model; we would follow the same steps as before to configure the darknet framework. Then, finally, run the inference with the YOLOv2 pretrained model and see it perform better than YOLOv1.
Configuring the darknet framework and running the inference with YOLOv2 on images and video is divided into seven easy-to-follow steps. So, let’s get started!
Note: Please ensure you have the matching CUDA, CUDNN, and NVIDIA Driver Installed on your machine. For this experiment, we use CUDA-10.2, CUDNN-8.0.3. But if you plan to run this experiment on Google Colab, do not worry, as all these libraries come pre-installed with it.
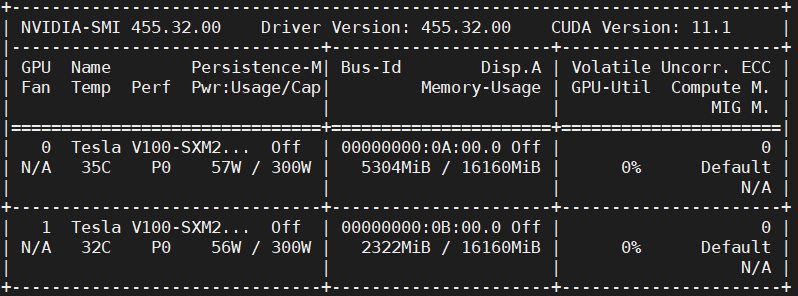
Step #1: We will use the GPU for this experiment, so make sure the GPU is up and running.
# Sanity check for GPU as runtime $ nvidia-smi
Figure 20 shows the GPUs available in the machine (i.e., V100) and the driver and CUDA versions.
Step #2: We will install a few libraries like OpenCV, FFmpeg, etc., that would be required before compiling and installing Darknet.
# Install OpenCV, ffmpeg modules $ apt install libopencv-dev python-opencv ffmpeg
Step #3: Next, we clone the modified version of the darknet framework from the AlexyAB repository. As learned earlier, Darknet is an open-source neural network written by Joseph Redmon. It is written in C and CUDA, supporting both CPU and GPU computation. The official implementation of the Darknet is available at: https://pjreddie.com/darknet/; we will download the YOLOv2 weights provided by the official website.
# Clone AlexeyAB darknet repository $ git clone https://github.com/AlexeyAB/darknet/ $ cd darknet/
Make sure to change the directory to darknet since, in the next step, we will configure the Makefile and compile it. Also, do a sanity check using !pwd; we should be in the /content/darknet directory.
Step #4: Using stream editor (sed), we will edit the make files and enable flags: GPU, CUDNN, OPENCV, and LIBSO.
Figure 21 shows a snippet of the Makefile contents, which are discussed later:

- We enable the
GPU=1andCUDNN=1to build darknet withCUDAto perform and accelerate the inference on theGPU. NoteCUDAshould be in/usr/local/cuda; otherwise, the compilation will result in an error, but don’t worry if you are compiling it on Google Colab. - If your
GPUhas Tensor Cores, enableCUDNN_HALF=1to gain up to3Xinference and2Xtraining speedup. Since we use a Tesla V100 GPU with tensor cores, we will enable this flag. - We enable
OPENCV=1to build darknet withOpenCV. This will allow us to detect video files, IP cameras, and other OpenCV off-the-shelf functionalities like reading, writing, and drawing bounding boxes over the frames. - Finally, we enable
LIBSO=1to build thedarknet.solibrary and binary runnable fileuselibthat uses this library. Enabling this flag would allow us to use Python scripts for inference on images and videos, and we will be able to importdarknetinside it.
Now let’s edit the Makefile and compile it.
# Enable the OpenCV, CUDA, CUDNN, CUDNN_HALF & LIBSO Flags and Compile Darknet $ sed -i 's/OPENCV=0/OPENCV=1/g' Makefile $ sed -i 's/GPU=0/GPU=1/g' Makefile $ sed -i 's/CUDNN=0/CUDNN=1/g' Makefile $ sed -i 's/CUDNN_HALF=0/CUDNN_HALF=1/g' Makefile $ sed -i 's/LIBSO=0/LIBSO=1/g' Makefile $ make
The make command will take around 90 seconds to finish the execution. Now that the compilation is complete, we are all set to download the YOLOv2 weights and run the inference.
Aren’t you excited?
Step #4: We will now download the YOLOv2-VOC weights from the official YOLOv2 documentation.
# Download YOLOv2 Weights $ wget https://pjreddie.com/media/files/yolov2-voc.weights
Step #5: Now, we will run the darknet_images.py script to infer the images.
# Run the darknet image inference script $ python3 darknet_images.py --input data --weights \ yolov2-voc.weights --config_file cfg/yolov2-voc.cfg \ --data_file cfg/voc.data --dont_show
Let’s put some light on the command line arguments we pass to darknet_images.py:
--input: Path to the images directory or text file with the path to the images or a single image name. Supportsjpg,jpeg, andpngimage formats. In this case, we pass the path to the image folder calleddata.--weights: YOLOv2 weights path.--config_file: Configuration file path of YOLOv2. On an abstract level, this file stores the neural network model architecture and a few other parameters likebatch_size,classes,input_size, etc. We recommend you give a quick read of this file by opening it in a text editor.--data_file: Here, we pass the PASCAL VOC labels file.--dont_show: This will disable OpenCV from displaying the inference results, and we use this since we are working with Google Colab.
After running YOLOv2 PASCAL VOC pretrained model on the below images, we learn that the model detects objects with much higher confidence and has almost close to zero false negatives compared to YOLOv1. However, you would see a couple of false positives.
We can see from Figure 22, the model detects a dog, bicycle, and car with a very high confidence score.

In Figure 23, the model detects all three objects correctly (i.e., a dog, person, and a horse); however, it detects the horse as a sheep but with a much lower confidence score. Recall in YOLOv1, the network made the same mistake of predicting the horse as a sheep, but at least YOLOv2 predicts it as a horse too! And since the confidence score for the sheep is less, you can filter that detection by increasing the --thresh argument!

In Figure 24, the model does a good job detecting all the horses. However, it also predicts one horse on the right as a cow. But unlike YOLOv1, it does not miss detecting the object.

Figure 25 is an image of an Eagle, similar to the YOLOv1 model that predicted a bird with 75%. However, YOLOv2 also detects a bird with a much higher confidence score of 95%.

Step #6: Now, we will run the pretrained YOLOv2 model on a video from the movie Skyfall; it is the same video that the Authors had used in one of their experiments.
Before running the darknet_video.py demo script, we will first download the video from YouTube using the Pytube library and crop the video with the moviepy library. So let’s quickly install these modules and download the video.
# Install pytube and moviepy for downloading and cropping the video $ pip install git+https://github.com/rishabh3354/pytube@master $ pip install moviepy
# Import the necessary packages
$ from pytube import YouTube
$ from moviepy.video.io.ffmpeg_tools import ffmpeg_extract_subclip
# Download the video in 720p and Extract a subclip
$ YouTube('https://www.youtube.com/watch?v=tHRLX8jRjq8'). \ streams.filter(res="720p").first().download()
$ ffmpeg_extract_subclip("/content/darknet/Skyfall.mp4", \
0, 30, targetname="/content/darknet/Skyfall-Sample.mp4")
Step #7: Finally, we will run the darknet_video.py script to generate predictions for the Skyfall video. We print the FPS information over each frame of the output video.
Be sure to change the video codec in the set_saved_video function from MJPG to mp4v at Line 57 in darknet_video.py if using an mp4 video file; otherwise, you will get a decoding error while playing the inference video.
# Change the VideoWriter Codec fourcc = cv2.VideoWriter_fourcc(*"mp4v")
Now that all the necessary installations and modifications are complete, we will run the darknet_video.py script:
# Run the darknet video inference script $ python darknet_video.py --input \ /content/darknet/Skyfall-Sample.mp4 \ --weights yolov2-voc.weights --config_file \ cfg/yolov2-voc.cfg --data_file ./cfg/voc.data \ --dont_show --out_filename pred-skyfall.mp4
Let’s look at the command line arguments we pass to darknet_video.py:
--input: Path to the video file or0if using a webcam--weights: YOLOv2 weights path--config_file: The configuration file path--data_file: Here, we pass the PASCAL VOC labels file--dont_show: This will disable OpenCV from displaying the inference results--out_filename: Inference results output video name, if empty output video not saved
Below are the inference results on the Skyfall Action Scene Video, and the predictions seem to be a lot better than YOLOv1. The YOLOv2 network achieves an average of 84 FPS on the Tesla V100 GPU with mixed precision.
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: May 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
Congratulations on making it this far! It was a lot to grasp as we discussed almost everything in detail about YOLOv2 along with YOLO9000, so let’s quickly summarize:
- You were introduced to the second version of YOLO, where we discussed Redmon and Farhadi’s (2017) essential contributions to creating a state-of-the-art object detector. We also briefly touched upon the speed and accuracy benchmarks of YOLOv2 and YOLO9000.
- We then looked at various technical components that made YOLOv2 perform Better like batch normalization, high-resolution classifier, convolution with anchor boxes, dimension clusters, etc., each progressively improving the object detector.
- You then learned the improvements made to run both training and testing of YOLOv2 Faster than before, especially the use of Darknet-19 architecture that consumed fewer FLOPs.
- We then also discussed the Stronger aspect of YOLO called YOLO9000. We covered the hierarchical training approach, merging the MS COCO and ImageNet dataset, and jointly training for classification and detection.
- Finally, we ran the Inference with the pretrained YOLOv2-VOC model on images and video on a Tesla V100 and compared the detection results with YOLOv1.
With learning YOLOv2, you have come one more step closer to mastering the YOLO series, as the initial posts act as a foundation for later YOLO versions. Keep that momentum going as we bring you more exciting posts on YOLO in the coming weeks.
Citation Information
Sharma, A. “A Better, Faster, and Stronger Object Detector (YOLOv2),” PyImageSearch, D. Chakraborty, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, R. Raha, and A. Thanki, eds., 2022, https://pyimg.co/ehaox
@incollection{Sharma_2022_YOLOv2,
author = {Aditya Sharma},
title = {A Better, Faster, and Stronger Object Detector ({YOLO}v2)},
booktitle = {PyImageSearch},
editor = {Devjyoti Chakraborty and Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Abhishek Thanki},
year = {2022},
note = {https://pyimg.co/ehaox},
}

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.