
Table of Contents
Ideating the Solution and Planning Experiments
In the previous lesson in this series, we looked at strategies to narrow down our search for a research topic and efficiently stay updated with its pacing literature. The “Methodology” and “Experiments” sections are perhaps the most important sections in any research paper. Selling research becomes easy when the approach is novel and experiments are comprehensive. Reviewers tend to become picky when either of them is compromised.

Besides being the most important sections in a research paper, the ideation and experimentation phase also requires the most time. This can make things challenging when submission deadlines are close. Hence, it becomes crucial to plan and proceed in these phases, as we will learn in this lesson.
In this series, you will learn how to publish novel research.
This lesson is the 2nd of a 5-part series on How to Publish Novel Research:
- Choosing the Research Topic and Reading Its Literature
- Ideating the Solution and Planning Experiments (this tutorial)
- Planning and Writing a Research Paper
- Planning Next Steps When Things Don’t Work Out
- Ensuring Your Research Stays Visible and General Tips
To learn how to ideate the solution and plan experiments, just keep reading.
Ideating the Solution
Now that we realize how crucial the ideation phase is, let’s look at some of the best ways to plan it and proceed.
Go with Your Gut
After reading a sufficient number of papers, you will begin to form intuitions. All you need to do is proceed with them. Intuition is more powerful than intelligence and has a better chance of working out (Figure 1). It can be a thought, as simple as trying out a specific loss function or a breakthrough as trying out transformers in vision (now popularly known as vision transformers). Whatever it is, it’s worth pursuing. Since you had that intuition after reading a lot of papers, the chances are good that it’s novel.

Approaching Incrementally
Start adding novelty or complexity incrementally instead of going for a complete solution (with several components and modules) in the first place. Looking for a complete solution initially will consume much of your time with no guarantee of working. Even if it works, it will be difficult to analyze or understand which components or modules contribute more. Ideating incrementally, on the other hand, will help you understand which components work better and why — thus letting you focus on relevant parts.
Approach Fundamentally
Viewing the problem from an existing mathematical equation can help build fundamentally strong solutions. Observe and think about how the problem can be solved, starting from that equation. Can it be decomposed into smaller components? Can it be approximated using an upper or lower bound? For example,
- Zhang et al. (2019) decompose the prediction error for adversarial examples (robust error) as the sum of the natural (classification) error and boundary error and provide a differentiable upper bound. Inspired by the analysis, they propose a new defense method, TRADES, to trade adversarial robustness against accuracy.
- The conventional way of feeding conditional information in generative adversarial networks (GANs) is by concatenating the (embedded) conditional vector to the feature vectors. Miyato and Koyama (2018) propose a projection loss, an alternative to the conventional approach, by observing the form of the optimal solution (Goodfellow et al., 2014) for the standard adversarial loss function for which the discriminator can be decomposed into the sum of two log-likelihood ratios.
- Singh et al. (2020) study the problem of attributional robustness (i.e., models having robust explanations) by starting from the fundamental equation of attributional vulnerability and deriving an upper bound for it in terms of spatial correlation between the input image and its explanation map. Further, they propose a methodology, ART, that learns robust features by minimizing this upper bound using soft-margin triplet loss.
Combine Existing Thoughts
A relatively simpler way to think for a solution is to combine existing ideas or thoughts into one. Since these existing methods are empirically proven to work, the chances are high that combining a number of them will bring further improvements. For example,
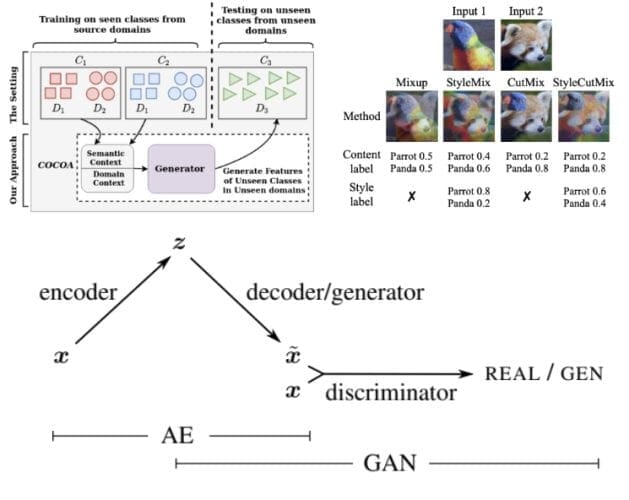
- Motivated by the success of generative modeling approaches in zero-shot learning and the usefulness of leveraging domain-specific information in domain generalization, Mangla et al. (2021) (Figure 2, top-left) propose a unified feature generative framework integrated with a COntext COnditional Adaptive (COCOA) Batch-Normalization layer to integrate class-level semantic and domain-specific information seamlessly.
- Mixup and Stylization are popular augmentation strategies to enhance the model’s generalization. Inspired by this, Hong et al. (2021) (Figure 2, top-right) propose StyleMix and StyleCutMix as the first mixup method that separately manipulates input image pairs’ content and style information. By carefully mixing up the content and style of images, they create more abundant and robust samples, eventually enhancing model training generalization.
- Larsen et al. (2016) (Figure 2, bottom) combine a variational autoencoder (VAE) with a generative adversarial network (GAN) by collapsing the VAE decoder and the GAN generator into one. This allows them to leverage learned feature representations in the GAN discriminator as the basis for the VAE reconstruction target.
Simple Yet Effective
Sometimes, a simple idea can significantly beat state-of-the-art methods (Figure 3). These ideas are intuitive, easier to understand and implement.

Here are some examples
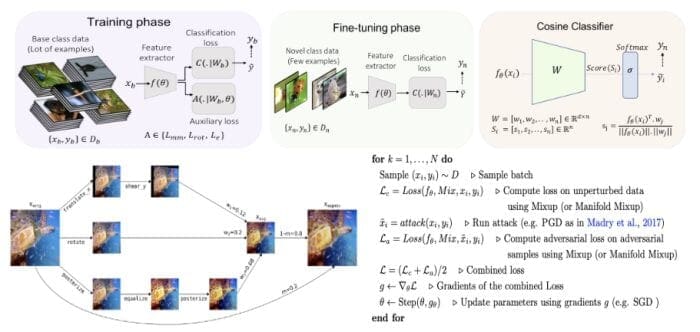
- S2M2 (Figure 4, top) works by adding self-supervision loss and manifold-mixup regularization to the transfer learning baselines, significantly beating state-of-the-art meta-learning approaches in few-shot classification.
- AugMix (Figure 4, bottom-left) is a simple augmentation strategy of mixing a diverse set of known augmentations (like random flip, color jitter, rotate, etc.) stochastically.
- Interpolated Adversarial Training (IAT) (Figure 4, bottom-right) simply integrates recently proposed interpolation-based training methods like mixup and manifold-mixup in the framework of adversarial training to reduce the tradeoff between standard and robust accuracy.
Is It Enough?
Another important step in developing a novel solution involves taking short pauses in between and evaluating whether the solution in its current state is strong enough. You need to converge to a solution at some point, and such a habit can help you identify if the approach is presentable in its current state or requires further thinking. But how to evaluate? Here are some parameters upon which you can assess the strength of your approach.
- Performance: Does the approach outperform state-of-the-art techniques? If yes, by what margin? Does it perform better across all benchmarks and architectures? Is it robust?
- Efficiency: Does the approach require fewer parameters? Does it converge faster? Is it easily adaptable to novel tasks? Can it solve multiple tasks at the same time? Does it require fewer samples for training?
- Insightfulness: Does the approach or analysis provide new insights? Any intriguing or interesting phenomenon? Does it provide a one-stop solution to many problems?
- Novelty: Does the idea look incremental? Is the idea differentiating with related work, or are there similar works?
- Complexity: Is the approach clean and straightforward, or are there too many moving parts in the pipeline? Is it difficult to understand which component works better? Are there too many hyper-parameters?
Act as a Reviewer
It’s important to criticize and question your approach from a reviewer’s lens. Be your reviewer and ask what the weaknesses and strengths of your approach are? What are major concerns? What more in terms of experimentation? How will you rate the idea? Doing so helps you address the concerns that an actual reviewer can point out beforehand, thus reducing the chances of reviewers being picky.
However, self-reviewing works only up to a certain extent. Since we are psychologically biased toward favoring our thoughts, we tend to miss or ignore things that can be important in a third person’s perspective. For this, you can ask your advisors, mentors, or friends to review the idea and share their thoughts and concerns with you. This allows you an opportunity to notice things you have missed and take inventory of what’s going well.
I always prefer presenting the idea to a larger and more diverse audience (e.g., in our research lab meetings) where everyone can share their thoughts and suggestions regardless of their expertise or experience. The best thing about being part of such interactions is that you often get new thoughts and directions to solving your problem and addressing your concerns. If you have access to such an audience (maybe your peer group, lab members, previous collaborators, etc.), this is probably the best way to get feedback for your work (Figure 5).
Planning Experiments
Next, let’s look at some of the best practices to follow while running experiments. Since you will be trying out several ideas, it is always better to follow standard protocols to evaluate and compare them with existing methods fairly.
Choose Your Baselines
Defining and reproducing baselines is the first place one should start. Comparing with a comprehensive set of baselines makes reviewers happy. It reduces the chances of them asking you to compare against another baseline out of the blue.
Try to have a comprehensive set of baselines that are either recent state-of-the-art techniques or anything that seems trivial. You can avoid comparing with unpublished papers, but that would be the cherry on the cake if you can. Ensure to reproduce a baseline using the same architectures and evaluation protocol described in its paper. If a baseline is not reproducible (maybe because the code base has some issues or is unavailable), use the actual numbers (ones mentioned in the paper) for comparison.
Perform Standard Experiments First
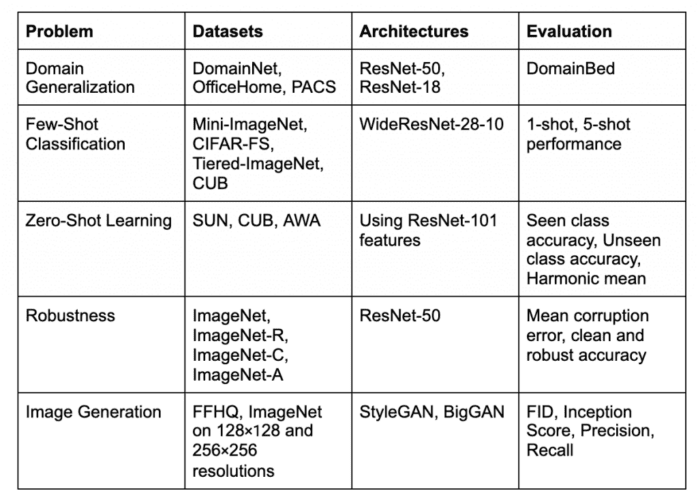
After defining and reproducing the baselines, start with the standard experiments in the literature. To make the comparisons fair, ensure that the architectures you are using are either the same as prior arts or have the same complexity (e.g., trainable parameters). Benchmarks and evaluation protocol should also be the same as prior arts. Table 1 mentions the standard benchmarks, architectures, and evaluation protocol for some popular areas.
Spend Time on Ablations and Analysis
By doing a thorough set of ablations and analysis, you can please the reviewers by helping them develop a complete understanding of your work. You can choose a small dataset to get results sooner as nobody expects you to show ablations on each dataset you used in the standard experiments. Here are some suggestions for starters:
- Component Analysis refers to analyzing the performance of your approach when certain components are removed or modified. This helps better understand the contribution of each of the components of your approach.
- A plot showing how performance varies with the choice of hyper-parameters helps understand whether the approach requires careful tuning. Ideally, performance should not vary significantly with the choice of hyper-parameters. But if it is the case, a hyper-parameter graph can help determine an ideal range for the choice of hyper-parameters.
- Visual results that can consist of T-SNE plots to show that the representations achieved by your approach are more organized than baseline methods: saliency maps or attention maps to explain if the model focuses on the right regions of the input while making a prediction.
Good Implementation Practices
Following good practices helps you organize your experiments and avoid a convoluted code base later. Here are several practices that one should follow while running experiments.
- Always do multiple runs: Don’t judge the performance of an experiment by a single run. Performance can vary significantly across several runs, which is generally not good. In my experience, this usually arises because of either training on small dataset sizes, having unstable training algorithms, or any explicit randomization in the code. Average out your results over multiple runs (ideally 5, 7, 10) and make a note on the standard deviation. A large standard deviation reflects that unstable runs need to be addressed.
- Leveraging validation set: If you have a validation set, you can leverage it for the automated tuning of your hyper-parameters, selecting good checkpoints for final testing, scheduling your learning rate, and deciding stopping criteria for your experiments.
- Build upon existing code base: Whenever implementing an idea, it’s good to start with and build upon an existing open-source code base (e.g., the official implementation by authors of prior arts) which already provides you with scripts to load datasets, train, evaluate, and visualize. This saves a lot of time now; you only need to modify at a few places to integrate and run your approach. Examples:
- Organize your code base: At the very start, the code is usually easier to manage because of fewer files, but as it grows to a point where several experiments and ideas need to be tried, it often gets convoluted and difficult to manage. Hence to remain productive, it is good to organize your code from the start. Here are a few things I have learned to achieve:
- Have proper structure to your project directory. Mineault (2021) explains how to create a proper python project.
- Use git for version control. Commit small changes to ensure everything is backed up and can be restored at any time.
- Rather than hardcoding, use command line arguments to specify details like architecture, hyper-parameters, and features (e.g., training, testing, or resuming).
- Log your losses and results properly. You can use online tools like Weights & Biases to achieve the same.
Notes on Submission Deadlines and Planning
If targeting the work for an upcoming conference, you might need to carefully plan your experiments. A good chunk of your time will go to paper writing. Don’t delay any major experiments until the end. If you fall short of time to run any particular experiment, keep it for the supplementary week. Its deadline is usually 7-14 days after the main submission deadline.
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: April 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
Ideation and experiments are the two most important phases in any research project that demands proper planning and execution. When ideating a solution, try those things that make sense to your gut as they have the most chance of working out. Always add novelty and complexity incrementally rather than thinking for a complete solution at once. Try approaching the problem like a fundamental mathematical equation by either decomposing or bounding it with simpler and solvable components.
Combining existing ideas in novel ways is another relatively simple direction. Don’t ideate thinking that the approach needs to be complex. Sometimes, even a simple idea can beat complex state-of-the-art methods. Regularly evaluate and criticize your approach regarding performance, insightfulness, novelty, complexity, and efficiency. This will help you understand if the solution in its current state is enough or needs further refinement. At last, present your idea to your advisor, mentors, peers, or a wider audience to get third-person perspective and feedback.
When starting with experiments, prioritize running and reproducing baselines first. Then proceed by running standard experiments in the literature. Choose your datasets, architectures, and evaluation protocols based on prior works in the literature. Spend time doing a thorough set of ablations to provide a holistic understanding of your work. Follow good practices of organizing your code properly, use version control, command line arguments, and logging. At last, plan your experiments keeping in mind where you want to target your work. If you are low in time, keep some of the experiments for the supplementary week.
I hope this lesson will assist you in planning and executing your ideas and experiments effectively. Stay tuned for the next lesson on planning and writing a research paper.
Citation Information
Mangla, P. “Ideating the Solution and Planning Experiments,” PyImageSearch, P. Chugh, R. Raha, K. Kudriavtseva, and S. Huot, eds., 2022, https://pyimg.co/h3joc
@incollection{Mangla_2022_Ideating,
author = {Puneet Mangla},
title = {Ideating the Solution and Planning Experiments},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Ritwik Raha and Kseniia Kudriavtseva and Susan Huot},
year = {2022},
note = {https://pyimg.co/h3joc},
}

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.