
My day-to-day life includes training many deep learning models. Sometimes I am blessed with an architecture that is small yet capable of providing extraordinary results. Other times, I have to tread the difficult path of training huge architectures to fetch good results.

With the ever-increasing size of the data-hungry deep learning models, we seldom talk about training a model with less than 10 million parameters. As a result, people with limited hardware access do not get a chance to train these models, and even if they do, the training time is so large, they cannot iterate over the process as quickly as they would want.
Fast Neural Network Training with Distributed Training and Google TPUs
In this article, I will provide some trade secrets that I have found especially useful to speed up my training process. We will talk about the different hardware used for Deep Learning and an efficient data pipeline that does not starve the hardware being used. This article will, in no time, make you and your training pipeline more efficient.
In the article, we will talk about:
- Different hardware used for Deep Learning
- Efficient data pipeline
- Distributing the training process
To learn how to perform distributed training with Google TPUs, just keep reading.
Configuring Your Development Environment
To follow this guide, you need to have the TensorFlow and TensorFlow Datasets libraries installed on your system.
Luckily, these packages are pip-installable:
$ pip install tensorflow $ pip install tensorflow-datasets
Having Problems Configuring Your Development Environment?

All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code right now on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides that are pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Project Structure
Before we continue, let’s first review our project directory structure. Start by accessing the “Downloads” section of this guide to retrieve the source code and Python scripts.
You’ll then be presented with the following directory structure:
$ tree . --dirsfirst . ├── outputs │ ├── cpu.png │ ├── gpu.png │ └── tpu.png ├── pyimagesearch │ ├── autoencoder.py │ ├── config.py │ ├── data.py │ └── loss.py ├── train_cpu.py ├── train_gpu.py └── train_tpu.py 2 directories, 10 files
Inside the pyimagesearch module, we have the following files:
autoencoder.py: Defines the autoencoder model that needs to be trainedconfig.py: Defines the configuration file that is needed for trainingdata.py: Defines the data pipeline for the model training steploss.py: Defines the losses that will be used for training
Finally, we have three Python scripts:
train_cpu.py: Trains the model on a CPUtrain_gpu.py: Trains the model on a GPUtrain_tpu.py: Trains the model on a TPU
The outputs directory consists of the inference images of the autoencoder trained on different hardware.
Hardware
In Deep Learning, the most fundamental operation is that of matrix multiplication. The faster we multiply, the more speed we achieve in training. There is a brilliant lecture dedicated to hardware in deep learning by Michigan University that I recommend watching to have an overview of how hardware has evolved over the years to suit Deep Learning. In this section, we will iterate over the types of hardware and try to figure out which one would serve our purpose better.
CPUs
The Central Processing Unit (CPU) is a processor based on the von Neumann architecture. The architecture proposes an electronic computer with the following components:
- A processing unit: This processes data that is being fed to it
- A control unit: This holds the instructions along with a program counter to control the entire workflow
- Memory: For storage
In the von Neumann architecture, the instructions and the data are present in the memory. The processor accesses instructions and processes the data accordingly. It also uses memory to store the intermediary calculations and later accesses it to complete any computation.
This architecture is extremely flexible. We can essentially provide any instruction and data, and the processor will do the rest of the work. However, the flexibility comes with a tradeoff — speed.
The architecture relies on memory access and also on the control instructions for the next step. Memory access becomes what is known as the von Neumann bottleneck. Even if we are doing matrix multiplication all day long, there is no way for the CPU to guess the future operations; hence it needs to keep accessing the data and instructions.
A snippet from the Google guide on TPUs sheds light on the aforementioned problem.
Each CPU’s Arithmetic Logic Units (ALUs), which are the components that hold and control multipliers and adders, can execute only one calculation at a time. Each time, the CPU has to access memory, which limits the total throughput and consumes significant energy.
Figure 2 shows a simplified version of matrix multiplication in a CPU. The operation takes place sequentially with memory access at each step.
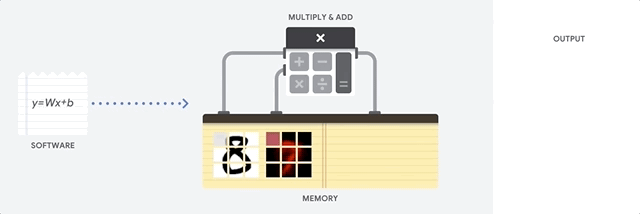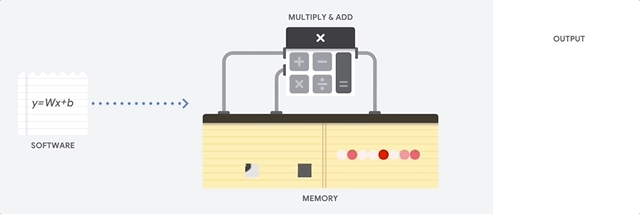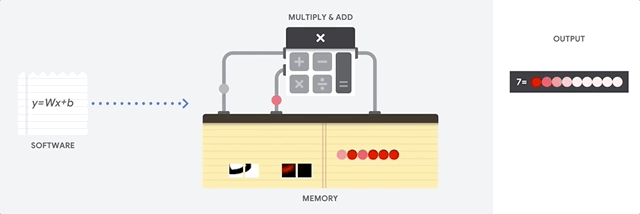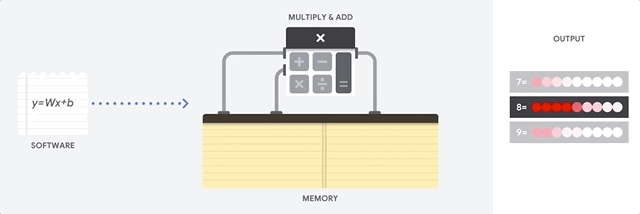
Let’s test the speed of our CPU performing matrix multiplication using TensorFlow. Open a Google Colab Notebook and paste the following code and see the results for yourself.
# import the necessary packages
import tensorflow as tf
import time
# initialize the operands
w = tf.random.normal((1024, 512, 16))
x = tf.random.normal((1024, 16, 512))
b = tf.random.normal((1024, 512, 512))
# start timer
start = time.time()
# perform matrix multiplication
output = tf.matmul(w, x) + b
# end timer
end = time.time()
# print the time taken to perform the operation
print(f"time taken: {(end-start):.2f} sec")
>>> time taken: 0.79 sec
Let’s do a little timing test with our CPUs using the code above. Here, we simulate the multiplication and addition operation, the most common operation found in Deep Learning. We see that the operation takes 0.79 sec to complete.
GPUs
Graphical Processing Units (GPUs) try to increase the throughput of CPUs by incorporating thousands of Arithmetic Logical Units (ALUs) on a single processor. This way, GPUs achieve parallelism in the operations.
Matrix multiplication is a parallel operation that makes Deep Learning calculations suit GPUs. GPUs are not specifically built for matrix multiplication, which means they still need to access memory and control instruction from the next step — the von Neumann bottleneck. Even with the bottleneck, GPUs provide a major step up in the training process due to their parallel operations.
Figure 3 shows a simplified version of matrix multiplication on a GPU. Note how the increase in ALUs helps in achieving parallelism and faster computation.

The code below is the same as done with CPUs. The change here is with the hardware that was used. We use GPUs here to run the code. As a result, the code took about ~99% less time than CPUs. This shows how powerful our GPUs are and how parallelism creates a huge difference. I highly recommend running the following code in a Google Colab Notebook with GPU runtime.
# import the necessary packages
import tensorflow as tf
import time
# initialize the operands
w = tf.random.normal((1024, 512, 16))
x = tf.random.normal((1024, 16, 512))
b = tf.random.normal((1024, 512, 512))
# start timer
start = time.time()
# perform matrix multiplication
output = tf.matmul(w, x) + b
# end timer
end = time.time()
# print the time taken to perform the operation
print(f"time taken: {(end-start):.6f} sec")
>>> time taken: 0.000436 sec
TPUs
We can already decipher what makes Tensor Processing Units (TPUs) great at Deep Learning.
Here’s a snippet from the guide:
Cloud TPU is the custom-designed machine learning ASIC (Application Specific Integrated Chip) that powers Google products like Translate, Photos, Search, Assistant, and Gmail…. One benefit TPUs have over other devices is a major reduction of the von Neumann bottleneck. Because the primary task for this processor is matrix processing, hardware designers of the TPU knew every calculation step to perform that operation. So they were able to place thousands of multipliers and adders and connect them directly to form a large physical matrix of those operators. This is called a systolic array architecture.
With the help of the systolic array architecture, the TPUs load the parameters first and then process the data on the fly. The architecture makes it possible for the data to be multiplied and added systematically with no requirement for memory access to fetch instructions or store the intermediate results.
Figure 4 displays a great resource on visualization of the TPU processing step:
With a little code change to use TPUs, we can hardly see any time decrease, but we have to keep in mind that we use a cluster of 8 TPUs here. This distribution of operations has a huge impact on the entire training pipeline. If we divide each replica, the training time decreases eightfold here. You can easily test the results and modify the calculation in a Google Colab Notebook with TPU runtime.
# import the necessary packages
import tensorflow as tf
import time
# initialize the cluster of TPU
tpu = tf.distribute.cluster_resolver.TPUClusterResolver()
tf.config.experimental_connect_to_cluster(tpu)
tf.tpu.experimental.initialize_tpu_system(tpu)
strategy = tf.distribute.TPUStrategy(tpu)
# initialize the operands
with strategy.scope():
w = tf.random.normal((1024, 512, 16))
x = tf.random.normal((1024, 16, 512))
b = tf.random.normal((1024, 512, 512))
# perform matrix multiplication
with strategy.scope():
start = time.time()
output = tf.matmul(w, x) + b
end = time.time()
print(f"time taken: {(end-start):.2f} sec")
>>> time taken: 0.06 sec
Distribute the Training
Before we start working on TPUs, another important concept for us to understand is distributed training. The idea is very simple: if we want to speed up, we delegate the process to multiple hardware that work in unison. This way, no one machine redundantly does the same task, and theoretically, the training time is divided by the number of machines to which we delegate the training process.
In this section, I will cover some basic strategies that I use to distribute my training. I highly recommend starting with this guide to distributed training to get a wider perspective of the topic.
Data
The most important thing to focus on when we want a performance upgrade is the data pipeline. It is quite obvious that an inefficient data pipeline will starve the hardware. Even with TPUs, if you provide data sequentially, the essence of data parallelism is defeated, and there will be no significant gains.
TensorFlow provides the tf.data API that makes data pipelines more efficient. You can refer to our series on tf.data to get a feel of the API. Using this API alone can provide a considerable boost to training time.
When we distribute training across multiple devices, the data pipeline becomes a huge concern. We now need to store the data efficiently so that it can be hosted at a very low cost, and we need to use a technique to transfer that data efficiently without much latency. The solution for this problem is to store the data in the TFRecords format.
The TFRecord format is a simple format for storing a sequence of binary records.
You can better understand the entire process of converting the data into TFRecords by going through the official TensorFlow guide on the same page.
Now that we have our data converted into TFRecords, we need to have it hosted somewhere so that we can access it (with low latency) for the distributed training. There are several solutions for hosting your data, Google Cloud Storage, Amazon Web Services, and more, but I recommend using public Kaggle Datasets. This way, people who cannot afford a paid subscription to hosting solutions can easily host their data as open access Kaggle Datasets and can use them.
With TPUs, it becomes a necessity to have the data in a GCS bucket. Kaggle Datasets provides hosting in a GCS bucket. That way, data stored as Kaggle Datasets can be used to work with TPUs too.
Understanding the “tf.distribute” Function
Now that we know how to store the data efficiently, we move to our next section, the core concept of distributed training on TensorFlow. The tf.distribute function provides an API that makes it very easy for us to distribute the code among multiple GPUs or TPUs.
Using this API, you can distribute your existing models and training code with minimal code changes.
I highly recommend starting with the official TensorFlow guide on distributed training for the curious mind. For an in-depth overview of distributed training, this tutorial beats all the resources out there (Figure 5).
I will dive straight into the two most used strategies for distributed training:
- MirroredStrategy: As the name suggests, each model parameter is mirrored among the cluster of devices that are used. We split the dataset so that each device gets its share of data. The forward propagation takes place simultaneously among all the devices. In this strategy, the gradients are accumulated and then used for the backpropagation step. This means that in each replica, the model is the same.
- TPUStrategy: This strategy is used specifically for TPUs. This is the same strategy as the MirroredStrategy.
Losses
While using distributed training, an important takeaway is to scale the losses properly. When we train on a single machine, the loss is averaged over the entire batch. This means that with multi-device training, we need to scale the losses according to the global batch size.
Suppose we incorporate 4 machines for our distributed setup. Each machine gets a batch of 16 images. The global batch size then becomes  . For example, losses need to be aggregated and averaged on 64 instead of 16.
. For example, losses need to be aggregated and averaged on 64 instead of 16.
We scale the losses because with a Mirrored or TPU strategy, the per-device loss is accumulated at the end of the forward propagation, and the gradients are computed on the accumulated loss. We need to keep this point in mind. Otherwise, you will notice a sharp increase in the losses.
Another important thing to notice here is the reduction of the losses to a scalar. Most of the tf.keras.losses use a default reduction of SUM_OVER_BATCH, which computes a reduced mean loss over all the dimensions of the batched loss tensor. When using the distribution strategy, we need to explicitly use the NONE or SUM type reduction, where SUM does a reduced sum over the batched loss on all the dimensions, and NONE computes a reduced mean on the last dimension of the batched loss only. This becomes a vital point to notice. With a NONE reduction, it becomes quite easy for us to miss that the losses are not scalars but remain tensors.
A Tale of Comparison
In this section, we will train an autoencoder on the MNIST dataset. The architecture involves a series of convolutions as the encoder and transpose convolutions as the decoder.
The autoencoder architecture is defined in the autoencoder.py file. Let’s take a look at the architecture in detail.
# import the necessary packages from tensorflow.keras import Model from tensorflow.keras import Sequential from tensorflow.keras.layers import InputLayer from tensorflow.keras.layers import Conv2D from tensorflow.keras.layers import Conv2DTranspose class AutoEncoder(Model): def __init__(self): super().__init__() # build the encoder self.encoder = Sequential([ InputLayer((28, 28, 1)), Conv2D(16, (3, 3), activation='relu', padding='same', strides=2), Conv2D(8, (3, 3), activation='relu', padding='same', strides=2)]) # build the decoder self.decoder = Sequential([ Conv2DTranspose(8, kernel_size=3, strides=2, activation='relu', padding='same'), Conv2DTranspose(16, kernel_size=3, strides=2, activation='relu', padding='same'), Conv2D(1, kernel_size=(3, 3), activation='sigmoid', padding='same')]) def call(self, x): # pass the input through the encoder and output of the encoder # through the decoder encoded = self.encoder(x) decoded = self.decoder(encoded) # return the output from the decoder return decoded
Lines 2-6 import the necessary packages. The model is created with TensorFlow’s Keras package.
Lines 12-17 define a sequential model with two convolutional layers. Both these layers stride twice, which decreases the spatial dimension of the input in half each time. This is our encoder. The encoder is supposed to squeeze the input representation into smaller dimensions.
Lines 20-26 define a sequential model with two convolutional transpose layers and a convolutional layer. The transpose layers scale the input tensors up spatially. This inherently inverted property helps us get our decoder. The work of the decoder is to decode the encoder representation and get an output similar to the input tensor.
Lines 28-35 define the way the model will be called. The data that is being used to call the model is first encoded by the encoder and then decoded by the decoder. The encoded representation is also known as the bottleneck.
We will train this model on different hardware and compare the training time as we go. The MNIST dataset used is part of the tensorflow_datasets API. With the tensorflow_datasets API, we can also use the try_gcs parameter that calls the data from a GCS bucket, if found. This helps with distributed training off the shelf.
CPU
Here, we take the dataset, compile the model with the optimizer and the losses required, and train the model.
$ python train_cpu.py Epoch 1/5 468/468 [==============================] - 65s 133ms/step - loss: 0.0380 - val_loss: 0.0036 Epoch 2/5 468/468 [==============================] - 57s 122ms/step - loss: 0.0028 - val_loss: 0.0022 Epoch 3/5 468/468 [==============================] - 56s 120ms/step - loss: 0.0020 - val_loss: 0.0018 Epoch 4/5 468/468 [==============================] - 57s 122ms/step - loss: 0.0017 - val_loss: 0.0016 Epoch 5/5 468/468 [==============================] - 57s 121ms/step - loss: 0.0015 - val_loss: 0.0014
We see that it takes a CPU ~57 secs to train for an epoch.
GPU
The only change that we need to do here is to train the model on a GPU. There is no change in the code at all. With the nvidia-smi command, we can look at the GPU that we have used for training.
We have used a Tesla T4 for the experiment.
$ python train_gpu.py Epoch 1/5 468/468 [==============================] - 24s 15ms/step - loss: 0.0378 - val_loss: 0.0036 Epoch 2/5 468/468 [==============================] - 4s 8ms/step - loss: 0.0028 - val_loss: 0.0022 Epoch 3/5 468/468 [==============================] - 4s 8ms/step - loss: 0.0020 - val_loss: 0.0018 Epoch 4/5 468/468 [==============================] - 4s 8ms/step - loss: 0.0017 - val_loss: 0.0016 Epoch 5/5 468/468 [==============================] - 4s 8ms/step - loss: 0.0015 - val_loss: 0.0015
Just by using GPUs and harnessing parallel computing, we see a drastic change in the training time. For a Tesla T4, it takes ~4 secs to train for an epoch.
TPU
The first thing here would be to harness the TPU and define the distribution strategy that we will use. Let’s take a look at train_tpu.py and dive deep into the training process.
# USAGE # python train_tpu.py # import tensorflow and fix the random seed for better reproducibility import tensorflow as tf tf.random.set_seed(42) # import the necessary packages from pyimagesearch import config from pyimagesearch.data import get_data from pyimagesearch.autoencoder import AutoEncoder from pyimagesearch.loss import MSELoss from tensorflow.distribute.cluster_resolver import TPUClusterResolver from tensorflow.config import experimental_connect_to_cluster from tensorflow.tpu.experimental import initialize_tpu_system from tensorflow.distribute import TPUStrategy from tensorflow.keras.preprocessing.image import array_to_img import matplotlib.pyplot as plt import os
On Line 5, we import tensorflow, and on Line 6, we set a seed for all the random operations in TensorFlow. All operations that are random (stochastic) in nature will lead to irreproducible results. When we set a random seed, every time the experiment is run from the beginning, the random operations will be the same, hence making the results reproducible.
# initialize the TPU and TPU strategy
tpu = TPUClusterResolver()
experimental_connect_to_cluster(tpu)
initialize_tpu_system(tpu)
strategy = TPUStrategy(tpu)
# get the number of accelerators
numAcc = strategy.num_replicas_in_sync
print(f"[INFO] Number of accelerators: {numAcc}")
# get the training dataset
print("[INFO] loading the training and validation datasets...")
trainDs = get_data(dataName=config.DATA_NAME,
split=config.TRAIN_FLAG, shuffleSize=config.SHUFFLE_SIZE,
batchSize=config.TPU_BATCH_SIZE)
# get the validation dataset
valDs = get_data(dataName=config.DATA_NAME,
split=config.VALIDATION_FLAG, batchSize=config.TPU_BATCH_SIZE)
Lines 22-25 define how you can define the distribution strategy to initialize a TPU cluster.
Lines 27-28 retrieve and show the number of TPU devices that are initialized and used in training.
Lines 32-39 initialize the training data and the validation data. Here, with the use of the get_data function, we retrieve the batched training and validation data.
# train the model in the scope
with strategy.scope():
# initialize the autoencoder model and compile it
print("[INFO] initializing the model...")
model = AutoEncoder()
mseLoss = MSELoss(scale=1)
model.compile(loss=mseLoss, optimizer=config.OPTIMIZER)
# train the model
print("[INFO] training the autoencoder...")
model.fit(trainDs, epochs=config.EPOCHS,
steps_per_epoch=config.TPU_STEPS_PER_EPOCH,
validation_data=valDs,
validation_steps=config.TPU_VALIDATION_STEPS)
Lines 42-54 define the training phase of the model. When we distribute the training under a defined Distribution Strategy, we need to initialize the model, optimizers, and the losses under the specified strategy. Here, on Line 42, we define the scope of the Distribution Strategy that we will use.
Line 45 initializes the autoencoder model that will be trained.
Line 46 initializes the mean square error loss function that we will use to train the model.
Line 47 compiles the model with the defined loss function and the specific optimizer.
Lines 51-54 use the model.fit() Keras API to train the model with the training dataset. In the fit function, we define the validation dataset as well to monitor the training process better. With the validation dataset, we will check whether the model overfits or underfits the training data.
# grab a batch of data from the test set and run inference
print("[INFO] evaluating the model...")
(testIm, _) = next(iter(valDs))
predIm = model.predict(testIm)
# create subplots
fig, axes = plt.subplots(nrows=8, ncols=2, figsize=(10, 40))
# iterate over the subplots and fill with test and predicted images
print("[INFO] displaying the predicted images...")
for ax, real, pred in zip(axes, testIm[:8], predIm[:8]):
# plot the input image
ax[0].imshow(array_to_img(real), cmap="gray")
ax[0].set_title("Input Image")
# plot the predicted image
ax[1].imshow(array_to_img(pred), cmap="gray")
ax[1].set_title("Predicted Image")
# check if the output image directory exists, if does not, then create
# it
if not os.path.exists(config.BASE_IMG_PATH):
os.makedirs(config.BASE_IMG_PATH)
# save the figure
print("[INFO] saving the predicted images...")
fig.savefig(config.TPU_IMG_PATH)
Lines 57-82 are dedicated to the inference phase. After our model is trained, we use the model to run inference on unseen data and visualize the output. Lines 58 and 59 grab a batch of the validation dataset and run inference on the same. Lines 62-73 create subplots and plot the input and predicted output. Lines 77-82 check for an existing inference image; if not found, save the inference image to the defined path.
Training a model on the CPU, GPU, and the TPU does not need too many changes. The only change we need to introduce here is to scale the loss and define the distribution strategy. Now that we know about the distribution strategy, let’s jump into the loss.py file to configure the loss functions.
# import the necessary packages from tensorflow.keras.losses import MeanSquaredError from tensorflow.keras.losses import Reduction from tensorflow import reduce_mean class MSELoss(): def __init__(self, scale): # accept the scalar by which the loss needs to be scaled self.scale = scale def __call__(self, real, pred): # initialize MeanSquaredError loss with no reduction MSE = MeanSquaredError(reduction=Reduction.NONE) # compute the loss loss = MSE(real, pred) # scale the loss loss = reduce_mean(loss) * (1. / self.scale) # return loss return loss
Lines 2-4 import the necessary packages.
Lines 6-22 define the loss function. We can notice how the loss function is built around a class. We want a structure like this to help us provide the class object with some properties during initialization and not think about it in the function calls later. For example, we would want the mean squared error loss function to notice the scale it needs to be reduced. We use the 1. / self.scale term to scale the loss according to the number of replicas we have.
$ python train_tpu.py Epoch 1/5 58/58 [==============================] - 8s 60ms/step - loss: 0.1608 - val_loss: 0.0773 Epoch 2/5 58/58 [==============================] - 2s 31ms/step - loss: 0.0555 - val_loss: 0.0384 Epoch 3/5 58/58 [==============================] - 2s 30ms/step - loss: 0.0249 - val_loss: 0.0151 Epoch 4/5 58/58 [==============================] - 2s 27ms/step - loss: 0.0124 - val_loss: 0.0099 Epoch 5/5 58/58 [==============================] - 2s 27ms/step - loss: 0.0087 - val_loss: 0.0072
We train the model with the distribution strategy that we want. Here, we see that it takes ~2 sec to train for an epoch.
In Table 1, we see the timing comparison of the various hardware used. A subtle difference that can go unnoticed is the batch size that is being used for different hardware. With CPUs and GPUs, the batch size was set to 128, while with TPUs, the batch size went up to 1024. This makes it quicker to train an epoch with TPUs.

A problem with large batch sizes and fewer steps per epoch is with the gradient update. The gradients are backpropagated fewer times with larger batch sizes, and the model takes many more iterations to train. This problem can be bypassed by using repeated datasets and fixed steps per epoch to constrain the model to backpropagate a fixed number of times in an epoch.
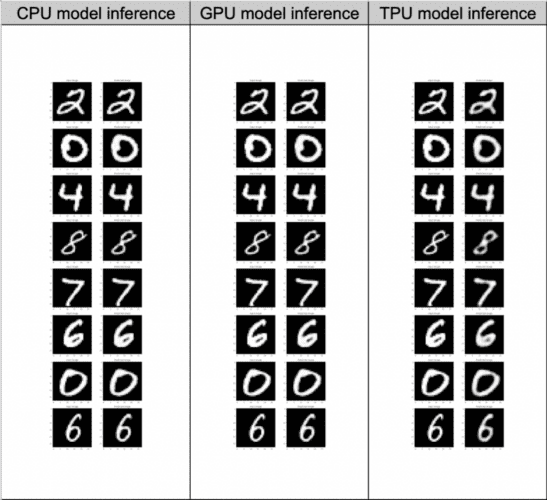
We can better understand the problem with the help of the predictions that we get while training the MNIST autoencoder.
In Figure 8, we notice the blurred prediction from the TPU model. This proves our point. We indeed fit more data in the TPU. However, due to fewer iterations in an epoch, the model learns worse than with a GPU or a CPU.
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: March 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
When you quickly iterate over a training process, you will eventually need GPUs and TPUs to train your model. The training time reported above should excite you to try porting some of your existing models to be compatible with TPUs or multiple GPUs. You can harness TPUs from Kaggle Notebooks or Google Colab Notebooks.
It would be great to see people coming in and posting their implementations with a multi-GPU or a TPU setup. Also, please remember to mention @pyimagesearch on Twitter, where you share your work with the world.

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.