
A picture is worth a thousand words.
— English idiom
We’ve heard this adage countless times in our lives. It simply means that a complex idea can be conveyed in a single image. Whether examining the line chart of our stock portfolio investments, looking at the spread of an upcoming football game, or simply taking in the art and brush strokes of a painting master, we are constantly ingesting visual content, interpreting the meaning, and storing the knowledge for later use.
However, for computers, interpreting the contents of an image is less trivial — all our computer sees is a big matrix of numbers. It has no idea regarding the thoughts, knowledge, or meaning the image is trying to convey.
In order to understand the contents of an image, we must apply image classification, which is the task of using computer vision and machine learning algorithms to extract meaning from an image. This action could be as simple as assigning a label to what the image contains, or as advanced as interpreting the contents of an image and returning a human-readable sentence.
Image classification is a very large field of study, encompassing a wide variety of techniques — and with the popularity of deep learning, it is continuing to grow.
Now is the time to ride the deep learning and image classification wave — those who successfully do so will be handsomely rewarded.
Image classification and image understanding are currently (and will continue to be) the most popular sub-field of computer vision for the next ten years. In the future, we’ll see companies like Google, Microsoft, Baidu, and others quickly acquire successful image understanding startup companies. We’ll see more and more consumer applications on our smartphones that can understand and interpret the contents of an image. Even wars will likely be fought using unmanned aircrafts that are automatically guided using computer vision algorithms.
Inside this chapter, I’ll provide a high-level overview of what image classification is, along with the many challenges an image classification algorithm has to overcome. We’ll also review the three different types of learning associated with image classification and machine learning.
Finally, we’ll wrap up this chapter by discussing the four steps of training a deep learning network for image classification and how this four-step pipeline compares to the traditional, hand-engineered feature extraction pipeline.
What Is Image Classification?
Image classification, at its very core, is the task of assigning a label to an image from a predefined set of categories.
Practically, this means that our task is to analyze an input image and return a label that categorizes the image. The label is always from a predefined set of possible categories.
For example, let’s assume that our set of possible categories includes:
categories = {cat, dog, panda}
Then we present the following image (Figure 1) to our classification system:

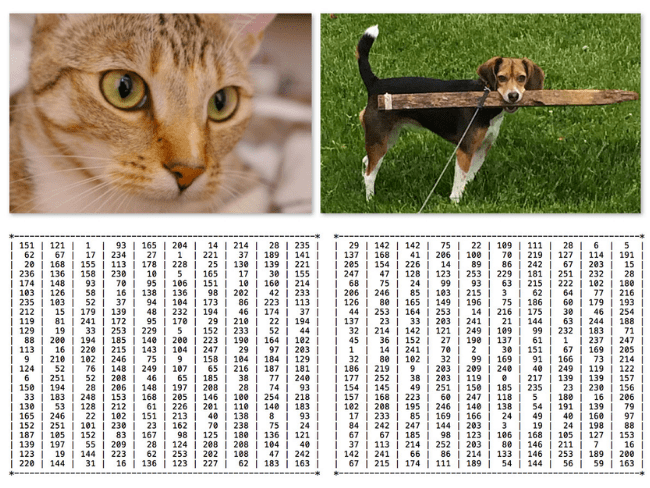
Our goal here is to take this input image and assign a label to it from our categories set — in this case, dog.
Our classification system could also assign multiple labels to the image via probabilities, such as dog: 95%; cat: 4%; panda: 1%.
More formally, given our input image of W×H pixels with three channels, Red, Green, and Blue, respectively, our goal is to take the W×H×3 = N pixel image and figure out how to correctly classify the contents of the image.
A Note on Terminology
When performing machine learning and deep learning, we have a dataset we are trying to extract knowledge from. Each example/item in the dataset (whether it be image data, text data, audio data, etc.) is a data point. A dataset is therefore a collection of data points (Figure 2).
Our goal is to apply machine learning and deep learning algorithms to discover underlying patterns in the dataset, enabling us to correctly classify data points that our algorithm has not encountered yet. Take the time now to familiarize yourself with this terminology:
- In the context of image classification, our dataset is a collection of images.
- Each image is, therefore, a data point.
I’ll be using the term image and data point interchangeably throughout the rest of this book, so keep this in mind now.
The Semantic Gap
Take a look at the two photos (top) in Figure 3. It should be fairly trivial for us to tell the difference between the two photos — there is clearly a cat on the left and a dog on the right. But all a computer sees is two big matrices of pixels (bottom).
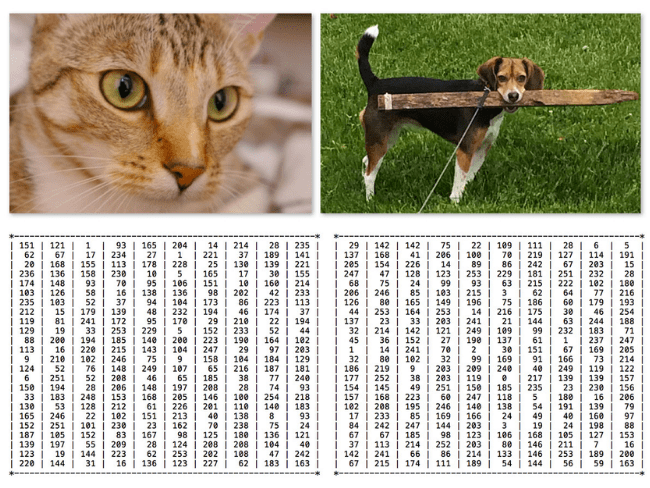
Given that all a computer sees is a big matrix of pixels, we arrive at the problem of the semantic gap. The semantic gap is the difference between how a human perceives the contents of an image versus how an image can be represented in a way a computer can understand the process.
Again, a quick visual examination of the two photos above can reveal the difference between the two species of an animal. But in reality, the computer has no idea there are animals in the image to begin with. To make this point clear, take a look at Figure 4, containing a photo of a tranquil beach.

We might describe the image as follows:
- Spatial: The sky is at the top of the image and the sand/ocean are at the bottom.
- Color: The sky is dark blue, the ocean water is a lighter blue than the sky, while the sand is tan.
- Texture: The sky has a relatively uniform pattern, while the sand is very coarse.
How do we go about encoding all this information in a way that a computer can understand it? The answer is to apply feature extraction to quantify the contents of an image. Feature extraction is the process of taking an input image, applying an algorithm, and obtaining a feature vector (i.e., a list of numbers) that quantifies our image.
To accomplish this process, we may consider applying hand-engineered features such as HOG, LBPs, or other “traditional” approaches to image quantifying. Another method, and the one taken by this book, is to apply deep learning to automatically learn a set of features that can be used to quantify and ultimately label the contents of the image itself.
However, it’s not that simple . . . because once we start examining images in the real world, we are faced with many, many challenges.
Challenges
If the semantic gap were not enough of a problem, we also have to handle factors of variation in how an image or object appears. Figure 5 displays a visualization of a number of these factors of variation.

To start, we have viewpoint variation, where an object can be oriented/rotated in multiple dimensions with respect to how the object is photographed and captured. No matter the angle in which we capture this Raspberry Pi, it’s still a Raspberry Pi.
We also have to account for scale variation as well. Have you ever ordered a tall, grande, or venti cup of coffee from Starbucks? Technically they are all the same thing — a cup of coffee. But they are all different sizes of a cup of coffee. Furthermore, that same venti coffee will look dramatically different when it is photographed up close versus when it is captured from farther away. Our image classification methods must be tolerable to these types of scale variations.
One of the hardest variations to account for is deformation. For those of you familiar with the television series Gumby, we can see the main character in the image above. As the name of the TV show suggests, this character is elastic, stretchable, and capable of contorting his body in many different poses. We can look at these images of Gumby as a type of object deformation — all images contain the Gumby character; however, they are all dramatically different from each other.
Our image classification should also be able to handle occlusions, where large parts of the object we want to classify are hidden from view in the image (Figure 5). On the left, we have to have a picture of a dog. And on the right, we have a photo of the same dog, but notice how the dog is resting underneath the covers, occluded from our view. The dog is still clearly in both images — she’s just more visible in one image than the other. Image classification algorithms should still be able to detect and label the presence of the dog in both images.
Just as challenging as the deformations and occlusions mentioned above, we also need to handle the changes in illumination. Take a look at the coffee cup captured in standard and low lighting (Figure 5). The image on the left was photographed with standard overhead lighting while the image on the right was captured with very little lighting. We are still examining the same cup — but based on the lighting conditions, the cup looks dramatically different (nice how the vertical cardboard seam of the cup is clearly visible in the low lighting conditions, but not the standard lighting).
Continuing on, we must also account for background clutter. Ever play a game of Where’s Waldo? (Or Where’s Wally? for our international readers.) If so, then you know the goal of the game is to find our favorite red-and-white, striped shirt friend. However, these puzzles are more than just an entertaining children’s game — they are also the perfect representation of background clutter. These images are incredibly “noisy” and have a lot going on in them. We are only interested in one particular object in the image; however, due to all the “noise,” it’s not easy to pick out Waldo/Wally. If it’s not easy for us to do, imagine how hard it is for a computer with no semantic understanding of the image!
Finally, we have intra-class variation. The canonical example of intra-class variation in computer vision is displaying the diversification of chairs. From comfy chairs that we use to curl up and read a book, to chairs that line our kitchen table for family gatherings, to ultra-modern art deco chairs found in prestigious homes, a chair is still a chair — and our image classification algorithms must be able to categorize all these variations correctly.
Are you starting to feel a bit overwhelmed with the complexity of building an image classifier? Unfortunately, it only gets worse — it’s not enough for our image classification system to be robust to these variations independently, but our system must also handle multiple variations combined together!
So how do we account for such an incredible number of variations in objects/images? In general, we try to frame the problem as best we can. We make assumptions regarding the contents of our images and to which variations we want to be tolerant. We also consider the scope of our project — what is the end goal? And what are we trying to build?
Successful computer vision, image classification, and deep learning systems deployed to the real-world make careful assumptions and considerations before a single line of code is ever written.
If you take too broad of an approach, such as “I want to classify and detect every single object in my kitchen,” (where there could be hundreds of possible objects) then your classification system is unlikely to perform well unless you have years of experience building image classifiers — and even then, there is no guarantee to the success of the project.
But if you frame your problem and make it narrow in scope, such as “I want to recognize just stoves and refrigerators,” then your system is much more likely to be accurate and functioning, especially if this is your first time working with image classification and deep learning.
The key takeaway here is to always consider the scope of your image classifier. While deep learning and Convolutional Neural Networks have demonstrated significant robustness and classification power under a variety of challenges, you still should keep the scope of your project as tight and well-defined as possible.
Keep in mind that ImageNet, the de facto standard benchmark dataset for image classification algorithms, consists of 1,000 objects that we encounter in our everyday lives — and this dataset is still actively used by researchers trying to push the state-of-the-art for deep learning forward.
Deep learning is not magic. Instead, deep learning is like a scroll saw in your garage — powerful and useful when wielded correctly, but hazardous if used without proper consideration. Throughout the rest of this book, I will guide you on your deep learning journey and help point out when you should reach for these power tools and when you should instead refer to a simpler approach (or mention if a problem isn’t reasonable for image classification to solve).
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: March 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Types of Learning
There are three types of learning that you are likely to encounter in your machine learning and deep learning career: supervised learning, unsupervised learning, and semi-supervised learning. This book focuses mostly on supervised learning in the context of deep learning. Nonetheless, descriptions of all three types of learning are presented below.
Supervised Learning
Imagine this: you’ve just graduated from college with your Bachelors of Science in Computer Science. You’re young. Broke. And looking for a job in the field — perhaps you even feel lost in your job search.
But before you know it, a Google recruiter finds you on LinkedIn and offers you a position working on their Gmail software. Are you going to take it? Most likely.
A few weeks later, you pull up to Google’s spectacular campus in Mountain View, California, overwhelmed by the breathtaking landscape, the fleet of Teslas in the parking lot, and the almost never-ending rows of gourmet food in the cafeteria.
You finally sit down at your desk in a wide-open workspace among hundreds of other employees . . . and then you find out your role in the company. You’ve been hired to create a piece of software to automatically classify email as spam or not-spam.
How are you going to accomplish this goal? Would a rule-based approach work? Could you write a series of if/else statements that look for certain words and then determine if an email is spam based on these rules? That might work . . . to a degree. But this approach would also be easily defeated and near impossible to maintain.
Instead, what you really need is machine learning. You need a training set consisting of the emails themselves along with their labels, in this case, spam or not-spam. Given this data, you can analyze the text (i.e., the distributions of words) in the email and utilize the spam/not-spam labels to teach a machine learning classifier what words occur in a spam email and which do not — all without having to manually create a long and complicated series of if/else statements.
This example of creating a spam filter system is an example of supervised learning. Supervised learning is arguably the most well-known and studied type of machine learning. Given our training data, a model (or “classifier”) is created through a training process where predictions are made on the input data and then corrected when the predictions are wrong. This training process continues until the model achieves some desired stopping criterion, such as a low error rate or a maximum number of training iterations.
Common supervised learning algorithms include Logistic Regression, Support Vector Machines (SVMs) (Cortes and Vapnik, 1995, Boser et al., 1992), Random Forests, and Artificial Neural Networks.
In the context of image classification, we assume our image dataset consists of the images themselves along with their corresponding class label that we can use to teach our machine learning classifier what each category “looks like.” If our classifier makes an incorrect prediction, we can then apply methods to correct its mistake.
The differences between supervised, unsupervised, and semi-supervised learning can best be understood by looking at the example in Table 1. The first column of our table is the label associated with a particular image. The remaining six columns correspond to our feature vector for each data point — here, we have chosen to quantify our image contents by computing the mean and standard deviation for each RGB color channel, respectively.
| Label | Rµ | Gµ | Bµ | Rσ | Gσ | Bσ |
|---|---|---|---|---|---|---|
| Cat | 57.61 | 41.36 | 123.44 | 158.33 | 149.86 | 93.33 |
| Cat | 120.23 | 121.59 | 181.43 | 145.58 | 69.13 | 116.91 |
| Cat | 124.15 | 193.35 | 65.77 | 23.63 | 193.74 | 162.70 |
| Dog | 100.28 | 163.82 | 104.81 | 19.62 | 117.07 | 21.11 |
| Dog | 177.43 | 22.31 | 149.49 | 197.41 | 18.99 | 187.78 |
| Dog | 149.73 | 87.17 | 187.97 | 50.27 | 87.15 | 36.65 |
Our supervised learning algorithm will make predictions on each of these feature vectors, and if it makes an incorrect prediction, we’ll attempt to correct it by telling it what the correct label actually is. This process will then continue until the desired stopping criterion has been met, such as accuracy, number of iterations of the learning process, or simply an arbitrary amount of wall time.
Remark: To explain the differences between supervised, unsupervised, and semi-supervised learning, I have chosen to use a feature-based approach (i.e., the mean and standard deviation of the RGB color channels) to quantify the content of an image. When we start working with Convolutional Neural Networks, we’ll actually skip the feature extraction step and use the raw pixel intensities themselves. Since images can be large MxN matrices (and therefore cannot fit nicely into this spreadsheet/table example), I have used the feature-extraction process to help visualize the differences between types of learning.
Unsupervised Learning
In contrast to supervised learning, unsupervised learning (sometimes called self-taught learning) has no labels associated with the input data and thus we cannot correct our model if it makes an incorrect prediction.
Going back to the spreadsheet example, converting a supervised learning problem to an unsupervised learning one is as simple as removing the “label” column (Table 2).
Unsupervised learning is sometimes considered the “holy grail” of machine learning and image classification. When we consider the number of images on Flickr or the number of videos on YouTube, we quickly realize there is a vast amount of unlabeled data available on the internet. If we could get our algorithm to learn patterns from unlabeled data, then we wouldn’t have to spend large amounts of time (and money) arduously labeling images for supervised tasks.
| Rµ | Gµ | Bµ | Rσ | Gσ | Bσ |
|---|---|---|---|---|---|
| 57.61 | 41.36 | 123.44 | 158.33 | 149.86 | 93.33 |
| 120.23 | 121.59 | 181.43 | 145.58 | 69.13 | 116.91 |
| 124.15 | 193.35 | 65.77 | 23.63 | 193.74 | 162.70 |
| 100.28 | 163.82 | 104.81 | 19.62 | 117.07 | 21.11 |
| 177.43 | 22.31 | 149.49 | 197.41 | 18.99 | 187.78 |
| 149.73 | 87.17 | 187.97 | 50.27 | 87.15 | 36.65 |
Most unsupervised learning algorithms are most successful when we can learn the underlying structure of a dataset and then, in turn, apply our learned features to a supervised learning problem where there is too little labeled data to be of use.
Classic machine learning algorithms for unsupervised learning include Principal Component Analysis (PCA) and k-means clustering. Specific to neural networks, we see Autoencoders, Self Organizing Maps (SOMs), and Adaptive Resonance Theory applied to unsupervised learning. Unsupervised learning is an extremely active area of research and one that has yet to be solved. We do not focus on unsupervised learning in this book.
Semi-supervised Learning
So, what happens if we only have some of the labels associated with our data and no labels for the other? Is there a way we can apply some hybrid of supervised and unsupervised learning and still be able to classify each of the data points? It turns out the answer is yes — we just need to apply semi-supervised learning.
Going back to our spreadsheet example, let’s say we only have labels for a small fraction of our input data (Table 3). Our semi-supervised learning algorithm would take the known pieces of data, analyze them, and try to label each of the unlabeled data points for use as additional training data. This process can repeat for many iterations as the semi-supervised algorithm learns the “structure” of the data to make more accurate predictions and generate more reliable training data.
| Label | Rµ | Gµ | Bµ | Rσ | Gσ | Bσ |
|---|---|---|---|---|---|---|
| Cat | 57.61 | 41.36 | 123.44 | 158.33 | 149.86 | 93.33 |
| ? | 120.23 | 121.59 | 181.43 | 145.58 | 69.13 | 116.91 |
| ? | 124.15 | 193.35 | 65.77 | 23.63 | 193.74 | 162.70 |
| Dog | 100.28 | 163.82 | 104.81 | 19.62 | 117.07 | 21.11 |
| ? | 177.43 | 22.31 | 149.49 | 197.41 | 18.99 | 187.78 |
| Dog | 149.73 | 87.17 | 187.97 | 50.27 | 87.15 | 36.65 |
Semi-supervised learning is especially useful in computer vision where it is often time-consuming, tedious, and expensive (at least in terms of man-hours) to label each and every single image in our training set. In cases where we simply do not have the time or resources to label each individual image, we can label only a tiny fraction of our data and utilize semi-supervised learning to label and classify the rest of the images.
Semi-supervised learning algorithms often trade smaller labeled input datasets for some tolerable reduction in classification accuracy. Normally, the more accurately labeled training a supervised learning algorithm has, the more accurate predictions it can make (this is especially true for deep learning algorithms).
As the amount of training data decreases, accuracy inevitably suffers. Semi-supervised learning takes this relationship between accuracy and amount of data into account and attempts to keep classification accuracy within tolerable limits while dramatically reducing the amount of training data required to build a model — the end result is an accurate classifier (but normally not as accurate as a supervised classifier) with less effort and training data. Popular choices for semi-supervised learning include label spreading, label propagation, ladder networks, and co-learning/co-training.
Again, we’ll primarily be focusing on supervised learning inside this book, as both unsupervised and semi-supervised learning in the context of deep learning for computer vision are still very active research topics without clear guidelines on which methods to use.

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.