In this tutorial, you will learn how to implement a simple scene boundary/shot transition detector with OpenCV.
Two weeks ago I flew out to San Diego, CA for a vacation with my Dad.
We were on the first flight out of Philadelphia and landed in San Diego at 10:30 AM, but unfortunately, our hotel rooms weren’t ready yet so we couldn’t check-in.
Both of us were a bit tired from waking up early, and not to mention, the six-hour flight, so we decided to hang out in the hotel lounge and relax until our rooms were ready.
I settled into a cozy hotel lounge chair, opened my iPhone, and started scrolling through notifications I missed while flying. A text message from my buddy Justin caught my eye:
Dude, I picked up issue #7 of The Batman Who Laughs last night. It’s SO GOOD. You’re going to love it. Let me know when you’ve read it so we can talk about it.
I’m a bit of a comic book nerd and the DC’s latest series, The Batman Who Laughs, is hands down my favorite series of the year — and according to Justin, the final issue in the story arc had just been released!
I opened Google Maps to see if there was a local comic book shop where I could pick up a copy.
No dice.
The closest store was two miles away — I wasn’t going to trek that far and leave my Dad at the hotel.
I’m not the biggest fan of reading comics on a screen, but in this case, I decided to make an exception.
I opened up the comiXology app on my iPhone (an app that lets you purchase and download digital comics), found the latest issue of The Batman Who Laughs, paid my $5, and downloaded it to my iPhone.
Now, you might be thinking that it would be a terribly painful experience to read a comic on a digital screen, especially a screen as small as an iPhone.
How in the world would you handle pinching, zooming, and scrolling on such a small screen? Wouldn’t that be a dreadful user experience, one that would potentially ruin reading a comic?
Trust me, it used to be.
But comic book publishers have wised up.
Instead of forcing you to use the equivalent of a mobile PDF viewer to read digital comics, publishers such as DC, Marvel, comiXology, etc. have locked up some poor intern in a dark dingy basement (hopefully kidding), and forced them to annotate the location of each panel in a comic.
Now, instead of having to manually scroll to the next panel in a comic, all you need to do is tap either the left or ride side of your phone screen and then the app automatically scrolls/zooms for you!
It’s a pretty neat feature, and while I will always prefer having the physical comic in my hands, the automatic scroll and zoom is a real game-changer for reading digital comics.
After I finished reading The Batman Who Laughs #7 (which was absolutely AWESOME, by the way), I got to thinking…
…what if I could use computer vision to automatically extract each panel from a digital comic?
The general algorithm would work like this:
- Record my iPhone screen as I’m reading the comic in the comiXology app.
- Post-process the video by using OpenCV to detect when the comic app is finished zooming, scrolling, etc.
- Save the current comic book panel to disk.
- Repeat for the entire length of the video.
The end result would be a directory containing each individual panel of the comic book!
You might think that such an algorithm would be challenging and tedious to implement — but it’s actually quite easy once you realize that it’s just an application of scene boundary detection!
Today I’ll be showing you how to implement the exact algorithm detailed above (and in only 100 lines of code).
To learn how to perform scene boundary detection with OpenCV, just keep reading!
Simple Scene Boundary/Shot Transition Detection with OpenCV
In the first part of this tutorial, we’ll discuss scene boundary and shot transition detection, including how computer vision algorithms can be be used to automatically segment clips from video files.
From there, we’ll look at how scene boundary detection can be applied to digital comic books, essentially creating an algorithm that can automatically extract comic book panels from a video.
Finally, we’ll implement the actual algorithm and review the results.
What are “scene boundaries” and “shot transitions”?
A “scene boundary” or a “shot transition” in a movie, TV show, or video is a natural way for the producers and editors to indicate that the current scene is complete and the next scene is starting. Shot transitions, when done correctly, are nonintrusive to the person watching the video — we intuitively process that the current “chapter” of the story is over and the next chapter is starting.
The most common type of scene boundary is a “fade to black”.
Just as the name suggests, this is when a scene ends and the video fades to black, then fades back in, indicating that the next scene is starting.
Using computer vision, we seek to automatically find these scene boundaries, enabling us to create a “smart video segmentation” system.
Such a video segmentation system could be used to automatically:
- Extract scenes from a movie/TV show, saving each scene/clip in a separate video file.
- Segment commercials from a given TV station for advertising research.
- Summarize slower moving sports games, such as baseball, golf, and American football.
Scene boundary detection is an active area of research and one that has existed for years.
I encourage you to use Google Scholar to search for the phrase “scene boundary detection” if you are interested in reading some of the publications.
Applying the scene boundary detection algorithm to digital comic books
In the context of this tutorial, we’ll be applying scene boundary detection through a real-world application — automatically extracting frames/panels from a digital comic book.
You might be thinking:
But Adrian, digital comic books are images, not video! How are you going to apply scene boundary detection to an image?
You’re right, comics are images — but part of being a computer vision practitioner is learning how to look at problems differently.
Using my iPhone, I can:
- Start recording my screen
- Open up the comiXology app
- Open a specific comic in the app
- Start reading the comic
- Tap my screen when I want to advance to the next panel
- Stop the video recording when I’m done reading the comic
Using this technique you can turn a digital comic book into a video file.
The trick to extracting comic book panels from this video is to detect when the moving stops.
To accomplish this task, all we need is a basic scene boundary detection algorithm.
Project structure
Let’s review our project structure:
$ tree --dirsfirst . ├── output │ ├── 0.png │ ├── 1.png │ ├── ... │ ├── 15.png ├── batman_who_laughs_7.mp4 └── detect_scene.py 1 directory, 18 files
Our project is quite simple.
We have a single Python script, detect_scene.py, which reads an input video (such as batman_who_laughs_7.mp4 or one of your own videos). The script then runs our boundary scene detection method to extract frames from the video. Each of the frames are exported to the output/ directory.
Implementing our scene boundary detector with OpenCV
Let’s go ahead and implement our basic scene boundary detector which we’ll later use to extract panels from comic books.
This algorithm is based on background subtraction/motion detection — if our “scene” in the video does not have any motion for a given amount of time, then we know the comic book app has finished scrolling/zooming us to the panel, in which case we can capture the current panel and save it to disk.
Are you ready to implement our scene boundary detector?
Open up the detect_scene.py file and insert the following code:
# import the necessary packages
import argparse
import imutils
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-v", "--video", required=True, type=str,
help="path to input video file")
ap.add_argument("-o", "--output", required=True, type=str,
help="path to output directory to store frames")
ap.add_argument("-p", "--min-percent", type=float, default=1.0,
help="lower boundary of percentage of motion")
ap.add_argument("-m", "--max-percent", type=float, default=10.0,
help="upper boundary of percentage of motion")
ap.add_argument("-w", "--warmup", type=int, default=200,
help="# of frames to use to build a reasonable background model")
args = vars(ap.parse_args())
Lines 2-5 import necessary packages. You need OpenCV and imutils installed for this project. I recommend that you install OpenCV in a virtual environment using pip.
From there, Lines 8-19 parse our command line arguments:
--video: The path to the input video file.--output: The path to the output directory to store comic book panel images.--min-percent: Default lower boundary of percentage of frame motion.--max-percent: Default upper boundary of percentage of frame motion.--warmup: Default number of frames to build our background model.
Let’s go ahead and initialize our background subtractor along with other important variables:
# initialize the background subtractor fgbg = cv2.bgsegm.createBackgroundSubtractorGMG() # initialize a boolean used to represent whether or not a given frame # has been captured along with two integer counters -- one to count # the total number of frames that have been captured and another to # count the total number of frames processed captured = False total = 0 frames = 0 # open a pointer to the video file initialize the width and height of # the frame vs = cv2.VideoCapture(args["video"]) (W, H) = (None, None)
Line 22 initializes our background subtractor model. We will apply it to every frame in our while loop in the next code block.
Lines 28-30 then initialize three housekeeping variables. The captured boolean indicates whether a frame has been captured. Two counters are initialized to 0 :
totalindicates how many frames we have capturedframesindicates how many frames from our video we have processed
Line 34 initializes our video stream using the input video file specified via command line argument in your terminal. The frame dimensions are set to None for now.
Let’s begin looping over video frames:
# loop over the frames of the video while True: # grab a frame from the video (grabbed, frame) = vs.read() # if the frame is None, then we have reached the end of the # video file if frame is None: break # clone the original frame (so we can save it later), resize the # frame, and then apply the background subtractor orig = frame.copy() frame = imutils.resize(frame, width=600) mask = fgbg.apply(frame) # apply a series of erosions and dilations to eliminate noise mask = cv2.erode(mask, None, iterations=2) mask = cv2.dilate(mask, None, iterations=2) # if the width and height are empty, grab the spatial dimensions if W is None or H is None: (H, W) = mask.shape[:2] # compute the percentage of the mask that is "foreground" p = (cv2.countNonZero(mask) / float(W * H)) * 100
Line 40 grabs the next frame from the video file.
Subsequently, Line 49 makes a copy (so we can save the original frame to disk later) and Line 50 resizes it. The smaller the frame is, the faster our algorithm will run.
Line 51 applies background subtraction, yielding our mask . White pixels in the mask are our foreground while the black pixels represent the background.
Liens 54 and 55 apply a series of morphological operations to eliminate noise.
Line 62 computes the percentage of the mask that is “foreground” versus “background”. Next, we’ll analyze the percentage, p , to determine if motion has stopped:
# if there is less than N% of the frame as "foreground" then we
# know that the motion has stopped and thus we should grab the
# frame
if p < args["min_percent"] and not captured and frames > args["warmup"]:
# show the captured frame and update the captured bookkeeping
# variable
cv2.imshow("Captured", frame)
captured = True
# construct the path to the output frame and increment the
# total frame counter
filename = "{}.png".format(total)
path = os.path.sep.join([args["output"], filename])
total += 1
# save the *original, high resolution* frame to disk
print("[INFO] saving {}".format(path))
cv2.imwrite(path, orig)
# otherwise, either the scene is changing or we're still in warmup
# mode so let's wait until the scene has settled or we're finished
# building the background model
elif captured and p >= args["max_percent"]:
captured = False
Line 67 compares the foreground pixel percentage, p , to the "min_percent" constant. If (1) p indicates that less than N% of the frame has motion, (2) we have not captured this frame, and (3) we are done warming up, then we’ll save this comic scene to disk!
Assuming we are saving this frame, we:
- Display the
framein the"Captured"window (Line 70) and mark it ascaptured(Line 71). - Build our
filenameand path (Lines 75-76). - Increment the
totalnumber of panels written to disk (Line 77). - Write the
origframe to disk (Line 81).
Otherwise, we mark captured as False (Lines 86 and 87), indicating that the above if statement did not pass and the frame was not written to disk.
To wrap up, we’ll display the frame and mask until we are done processing all frames :
# display the frame and detect if there is a key press
cv2.imshow("Frame", frame)
cv2.imshow("Mask", mask)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# increment the frames counter
frames += 1
# do a bit of cleanup
vs.release()
The frame and mask are displayed until either the q key is pressed or there are no more frames left in the video process.
In the next section, we’ll analyze our results.
Scene boundary detection results
Now that we’ve implemented our scene boundary detector, let’s give it a try.
Make sure you’ve used the “Downloads” section of this tutorial to download the source code and example video for this guide.
From there, open up a terminal and execute the following command:
$ python detect_scene.py --video batman_who_laughs_7.mp4 --output output [INFO] saving 0.png [INFO] saving 1.png [INFO] saving 2.png [INFO] saving 3.png [INFO] saving 4.png [INFO] saving 5.png [INFO] saving 6.png [INFO] saving 7.png [INFO] saving 8.png [INFO] saving 9.png [INFO] saving 10.png [INFO] saving 11.png [INFO] saving 12.png [INFO] saving 13.png [INFO] saving 14.png [INFO] saving 15.png

Our algorithm is able to detect when the app is automatically “moving” the page of the comic by zooming, scrolling, etc. — when this movement stops, we consider it the scene boundary. In the context of our end goal, this scene boundary marks when we have arrived at the next panel of the comic.
We then save this panel to disk and then continue to monitor the video file for when the next movement occurs, indicating that we’re moving to the next panel in the comic.
If you check the contents of the output/ directory after processing the video you’ll see that we’ve successfully extracted each panel from the comic:
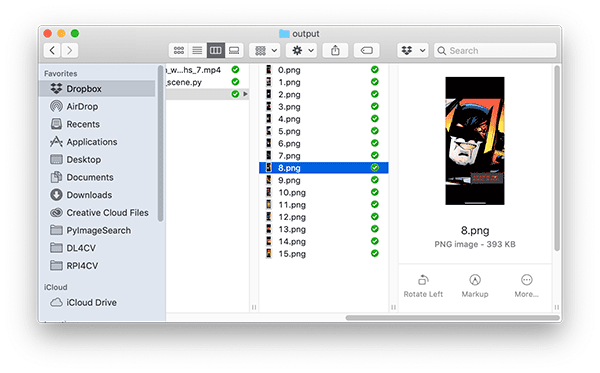
I’ve included a full video of the demo, including my commentary, below:
As I mentioned earlier in this post, being a successful computer vision practitioner often involves looking at problems differently — sometimes you can repurpose video processing algorithms and apply them to images, simply by figuring out how to take images and capture them as a video instead.
In this post, we were able to apply scene boundary detection to extract panels from a comic book, simply by recording ourselves reading a comic via the comiXology app!
Sometimes all you need is a slightly different viewpoint to solve a potentially challenging problem.
Credits
- Music: “Sci-Fi” — Benjamin Tissot
- Comic: The Batman Who Laughs #7 — DC Comics (Written by: Scott Snyder, Art by: Jock)
- Note: I have only used the first few frames of the comic in the example video. I have not included the entire comic as that would be quite the severe copyright violation! Again, this demo is for educational purposes only.
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: June 2025
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this tutorial, you learned how to implement a simple scene boundary detection algorithm using OpenCV.
We specifically applied this algorithm to digital comic books, enabling us to automatically extract each individual panel of a comic book.
You can take this algorithm and apply it to your own video files as well.
If you are interested in learning more about scene boundary detection algorithms, use the comment form at the bottom of this post to let me know — I may decide to cover these algorithms in more detail in the future!
I hope you enjoyed the tutorial!
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), just enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

