A few weeks ago I introduced bat-country, my implementation of a lightweight, extendible, easy to use Python package for deep dreaming and inceptionism.
The reception of the library was very good, so I decided that it would be interesting to do a follow up post — but instead of generating some really trippy images like on the Twitter #deepdream stream, I thought it would be more captivating to instead visualize every layer of GoogLeNet using bat-country.
Visualizing every layer of GoogLeNet with Python
Below follows my Python script to load an image, loop over every layer of the network, and then write each output image to file:
# import the necessary packages
from __future__ import print_function
from batcountry import BatCountry
from PIL import Image
import numpy as np
import argparse
import warnings
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-b", "--base-model", required=True, help="base model path")
ap.add_argument("-i", "--image", help="path to image file")
ap.add_argument("-o", "--output", help="path to output directory")
args = ap.parse_args()
# filter warnings, initialize bat country, and grab the layer names of
# the CNN
warnings.filterwarnings("ignore")
bc = BatCountry(args.base_model)
layers = bc.layers()
# extract the filename and extension of the input image
filename = args.image[args.image.rfind("/") + 1:]
(filename, ext) = filename.split(".")
# loop over the layers
for (i, layer) in enumerate(layers):
# perform visualizing using the current layer
print("[INFO] processing layer `{}` {}/{}".format(layer, i + 1, len(layers)))
try:
# pass the image through the network
image = bc.dream(np.float32(Image.open(args.image)), end=layer,
verbose=False)
# draw the layer name on the image
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
cv2.putText(image, layer, (5, image.shape[0] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.95, (0, 255, 0), 2)
# construct the output path and write the image to file
p = "{}/{}_{}.{}".format(args.output, filename, str(i + 1).zfill(4), ext)
cv2.imwrite(p, image)
except KeyError, e:
# the current layer can not be used
print("[ERROR] cannot use layer `{}`".format(layer))
# perform housekeeping
bc.cleanup()
This script requires three command line arguments: the --base-model directory where our Caffe model lives, the path to our input --image , and finally the --output directory where our images will be stored after being passed through the network.
As you’ll also see, I am using a try/except block to catch any layers that cannot be used for visualization.
Below is the image that I inputted to the network:

I then executed the Python script using the following command:
$ python visualize_layers.py \ --base-model $CAFFE_ROOT/caffe/models/bvlc_googlenet \ --image images/jp.jpg --output output/jp
And the visualization process will kick off. I generated my results on an Amazon EC2 g2.2xlarge instance with GPU support enabled so the script finished up within 30 minutes.
You can see a .gif of all layer visualizations below:
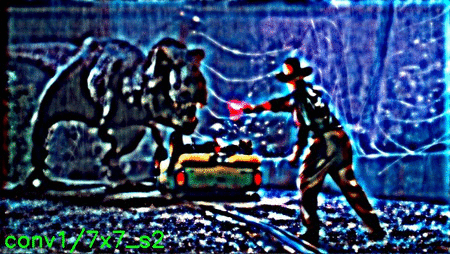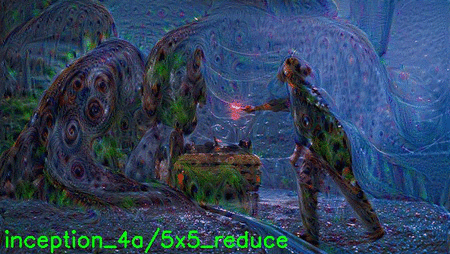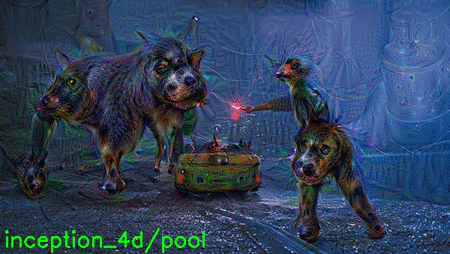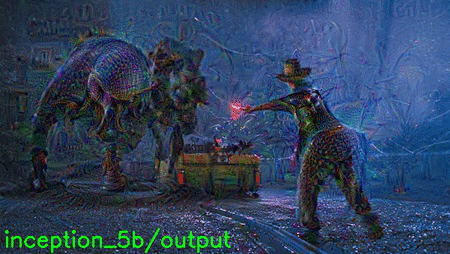
The .gif is pretty large at 9.6mb, so give it a few seconds to load, especially if you are on a slow connection.
In the meantime, here are some of my favorite layers:





What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
This blog post was a quick “just for fun” tutorial on visualizing every layer of a CNN using the bat-country library. It also served as a good demonstration on how to use the bat-country library.
If you haven’t had a chance to play around with deep dreaming or inceptionism, definitely give the original post on bat-country a read — I think you’ll find it amusing and enjoyable.
See you next week!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

