Table of Contents
- Build a Network Intrusion Detection System with Variational Autoencoders
- Understanding Network Intrusion and the Role of Anomaly Detection
- Autoencoders for Anomaly Detection
- What Are Autoencoders?
- Autoencoders as Anomaly Detection Algorithms
- Why Choose Variational Autoencoders (VAEs)?
- Building a Network Intrusion Detection System Using VAEs
- Project Setup
- Data Visualization
- Data Preprocessing
- Implementing and Training a VAE
- Evaluating the IDS on Test Data
- Summary
Build a Network Intrusion Detection System with Variational Autoencoders
In this tutorial, you will learn how to use variational autoencoders to build a network intrusion detection system.

In the realm of cybersecurity, the ability to detect and respond to network intrusions is crucial. Intrusion detection systems (IDS) serve as the first line of defense against unauthorized access and malicious activities. At the heart of effective intrusion detection lies anomaly detection, a technique that identifies deviations from normal network behavior. By focusing on these anomalies, organizations can uncover potential threats that traditional signature-based methods might miss.
In this blog post, we will explore how to build a Network Intrusion Detection System using machine learning methods (e.g., autoencoders). Autoencoders prove to be a great tool for building intrusion detection systems as they learn the normal patterns of network traffic during the training phase and then flag any significant deviations during real-time monitoring.
In this tutorial, we will develop a comprehensive understanding of how to leverage autoencoders — specifically VAEs to enhance network security, ensuring the systems are better protected against potential intrusions.
This lesson is the 3rd of a 4-part series on Anomaly Detection:
- Credit Card Fraud Detection Using Spectral Clustering
- Predictive Maintenance Using Isolation Forest
- Build a Network Intrusion Detection System with Variational Autoencoders (this tutorial)
- Outlier Detection Using the Grubbs Test
To learn how to build a network intrusion detection system with variational autoencoders, just keep reading.
Understanding Network Intrusion and the Role of Anomaly Detection
Imagine a scenario where a large financial institution suddenly notices an unusual spike in network traffic late at night. This spike is not typical for their usual operations and raises a red flag. Upon closer inspection, it is discovered that an unauthorized entity is attempting to access sensitive customer data. This is a classic example of a network intrusion, where an external attacker exploits vulnerabilities to gain access to the network and potentially steal valuable information.
What Is Network Intrusion?
Network Intrusion (Figure 1) refers to any unauthorized access or activity within a computer network. This can include a wide range of malicious actions (e.g., hacking, data theft, and the introduction of malware). Intrusions can be carried out by external attackers or even insiders with malicious intent.
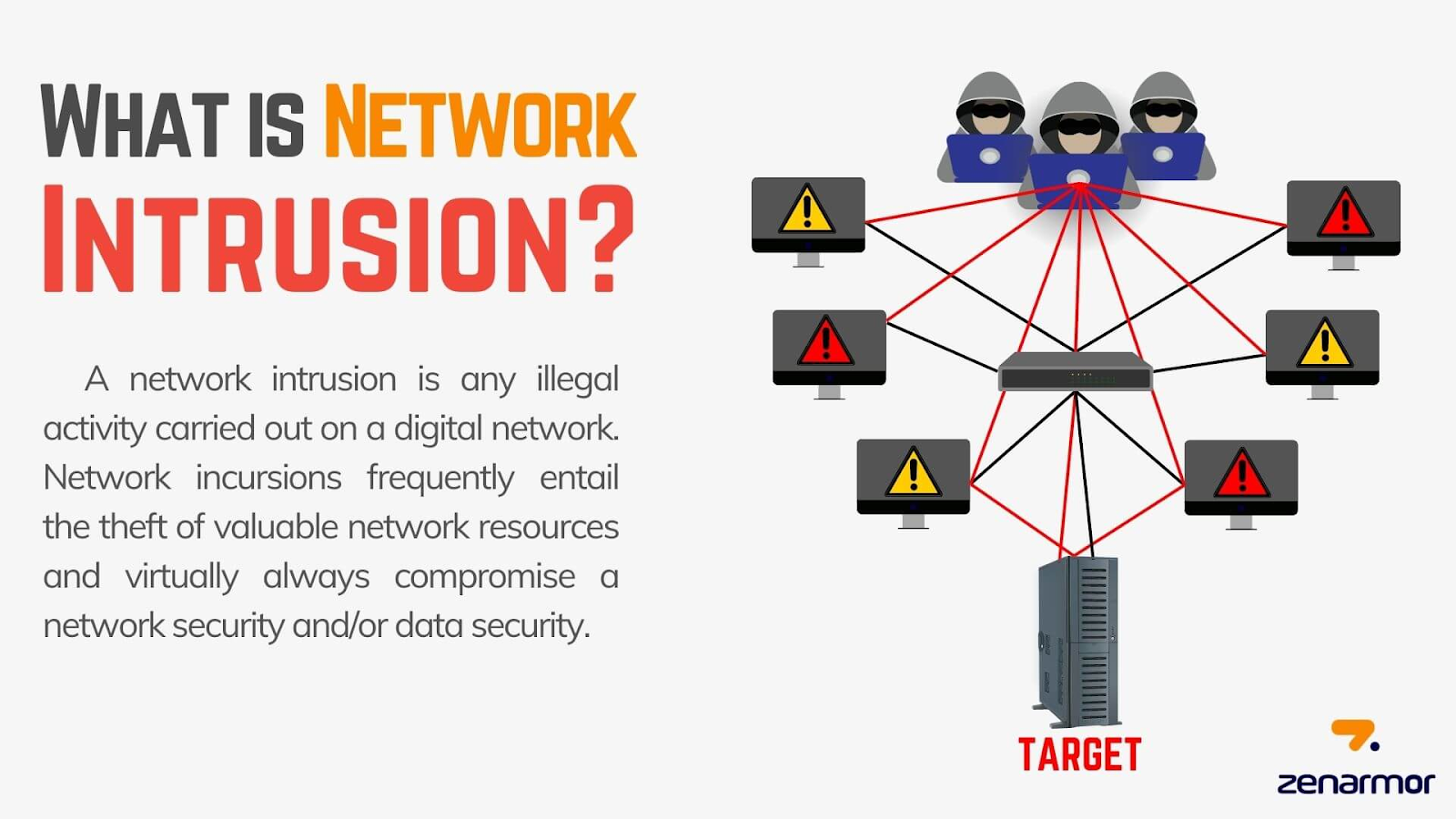
A successful network intrusion can lead to significant financial losses, reputational damage, and legal consequences. For instance, a data breach at a financial institution could result in the theft of customers’ personal and financial information, leading to identity theft and financial fraud.
The primary goal of these intrusions is often to gain access to sensitive information, disrupt services, or cause damage to the network infrastructure. For example, a hacker might exploit a vulnerability in a company’s firewall to gain access to its internal network and steal confidential data.
Importance and Necessity for Advanced IDS
The importance of detecting network intrusions cannot be overstated. In today’s digital age, organizations rely heavily on their network infrastructure to conduct business operations, store sensitive data, and communicate with clients and partners.
With the increase in the sophistication and frequency of cyber-attacks, traditional security measures (e.g., firewalls and antivirus software) are no longer sufficient to protect against advanced threats. Intrusion detection systems (IDS) (Figure 2) are essential for monitoring network traffic in real-time, identifying suspicious activities, and responding to potential threats before they can cause harm.
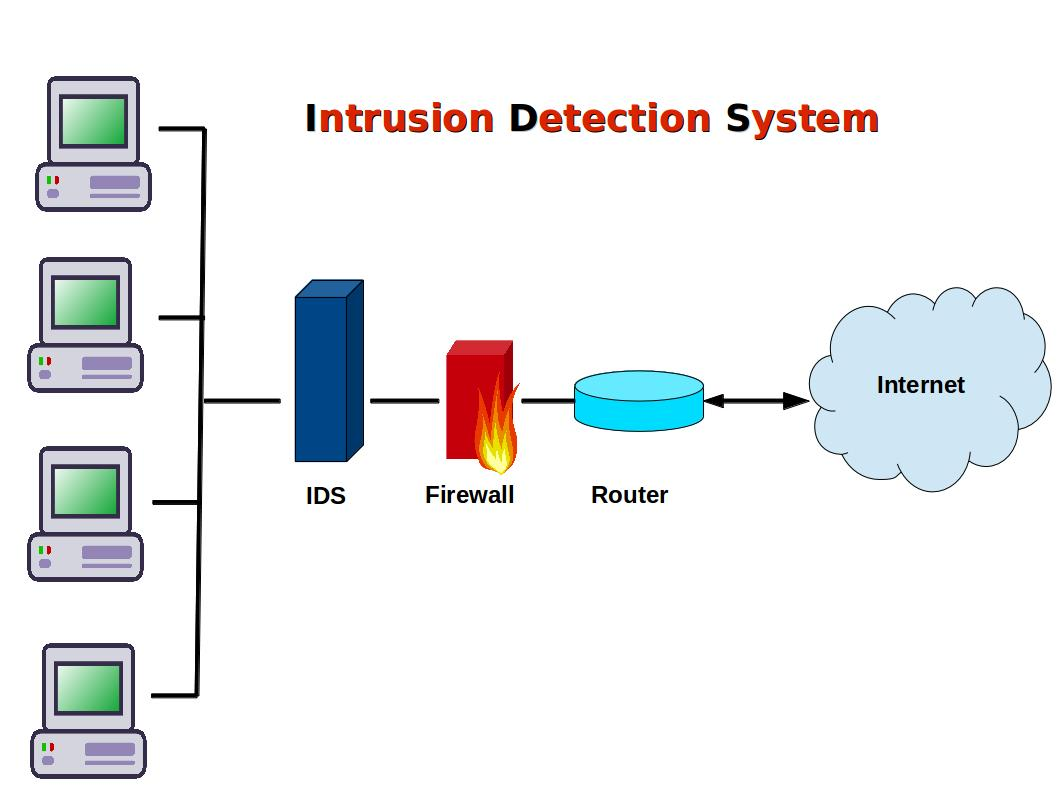
For example, an IDS can detect an unusual spike in network traffic that might indicate a Distributed Denial of Service (DDoS) attack, allowing administrators to take immediate action to mitigate the threat.
For example, one notable example is the WannaCry ransomware attack, which spread rapidly across networks worldwide, encrypting data and demanding ransom payments. An effective IDS could have detected the unusual network behavior associated with the ransomware’s propagation, allowing organizations to isolate affected systems and prevent further spread.
Autoencoders for Anomaly Detection
What Are Autoencoders?
Autoencoders (Figure 3) are a type of neural network used for unsupervised learning, particularly well-suited for anomaly detection. They work by compressing input data into a lower-dimensional representation and then reconstructing it back to its original form.
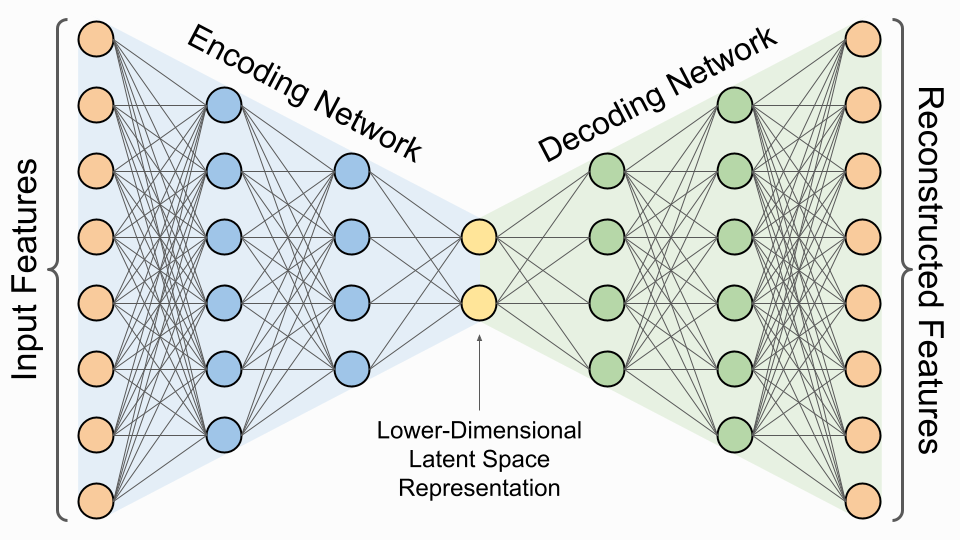
They consist of two main parts: an encoder and a decoder.
- Encoder: The encoder
") is usually a neural network (fully connected or deep neural network) that compresses the input data
is usually a neural network (fully connected or deep neural network) that compresses the input data  (
( is the input dimension) into a lower-dimensional representation
is the input dimension) into a lower-dimensional representation  . This process can be represented as:
. This process can be represented as: ")
- Latent Space: The latent space
 is the compressed representation of the input data. It serves as a compact summary of the input, capturing its most important features. The size of the latent space is typically much smaller than the original input, which forces the autoencoder to learn efficient representations.
is the compressed representation of the input data. It serves as a compact summary of the input, capturing its most important features. The size of the latent space is typically much smaller than the original input, which forces the autoencoder to learn efficient representations. - Decoder: The decoder is again a neural network (fully connected or deep neural network) that takes the compressed representation and reconstructs it back to the original input data
 . The decoding process can be represented as:
. The decoding process can be represented as:")
") is usually a neural network (fully connected or deep neural network) that compresses the input data
is usually a neural network (fully connected or deep neural network) that compresses the input data  (
( is the input dimension) into a lower-dimensional representation
is the input dimension) into a lower-dimensional representation  . This process can be represented as:
. This process can be represented as: ")
 is the compressed representation of the input data. It serves as a compact summary of the input, capturing its most important features. The size of the latent space is typically much smaller than the original input, which forces the autoencoder to learn efficient representations.
is the compressed representation of the input data. It serves as a compact summary of the input, capturing its most important features. The size of the latent space is typically much smaller than the original input, which forces the autoencoder to learn efficient representations. . The decoding process can be represented as:
. The decoding process can be represented as:")
The training process of an autoencoder involves minimizing the reconstruction error (Figure 4), which is the difference between the original input  and the reconstructed output
and the reconstructed output  . This can be expressed as:
. This can be expressed as:
 = \Vert \mathbf{x} - \mathbf{\hat{x}}\Vert^2")
Autoencoders as Anomaly Detection Algorithms
The key idea is that the autoencoder learns to capture the most important features of the data during this process.
Here’s a detailed explanation of how autoencoders can be used for anomaly detection:
- Training Phase: During the training phase, the autoencoder is fed with normal (non-anomalous) data (Figure 5). The network learns to encode this data into a compressed form (latent space) and then decode it back to the original data.
The goal is to minimize the reconstruction error, which is the difference between the input data and the reconstructed data. This process helps the autoencoder to learn the underlying patterns and features of the normal data.

- Detection Phase: Once the autoencoder is trained, it can be used to detect anomalies. When new data is fed into the trained autoencoder, it attempts to reconstruct the data. If the new data is similar to the normal data it was trained on, the reconstruction error will be low.
However, if the new data is anomalous, the reconstruction error will be high (Figure 6) because the autoencoder has not learned to represent these anomalies. By setting a threshold for the reconstruction error, we can classify data points as normal or anomalous.
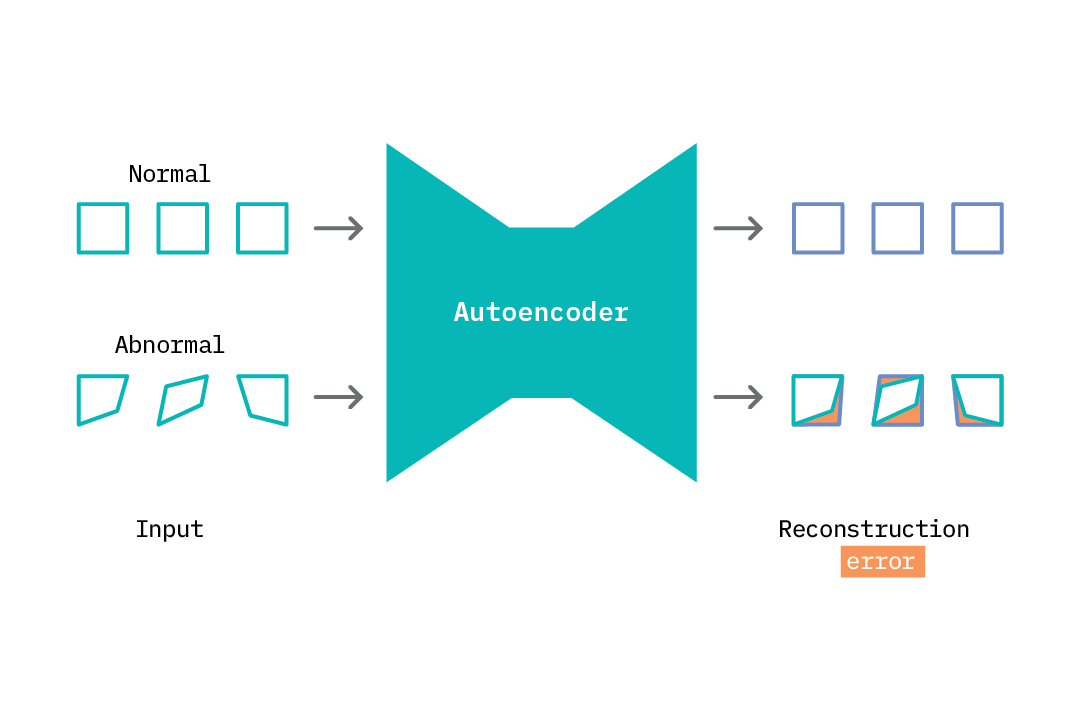
- Advantages of Autoencoders: Autoencoders are particularly effective for anomaly detection because they do not require labeled data. They can learn the normal behavior of the system from the available data and identify deviations from this behavior. This makes them suitable for applications where anomalies are rare and difficult to label (e.g., fraud detection, network intrusion detection, and predictive maintenance).
Why Choose Variational Autoencoders (VAEs)?
Variational autoencoders (Figure 7) are a specific type of autoencoder that introduces a probabilistic approach to the encoding process. Unlike traditional autoencoders, which map input data to a single point in the latent space, VAEs map input data to a distribution in the latent space. This has several advantages for anomaly detection:
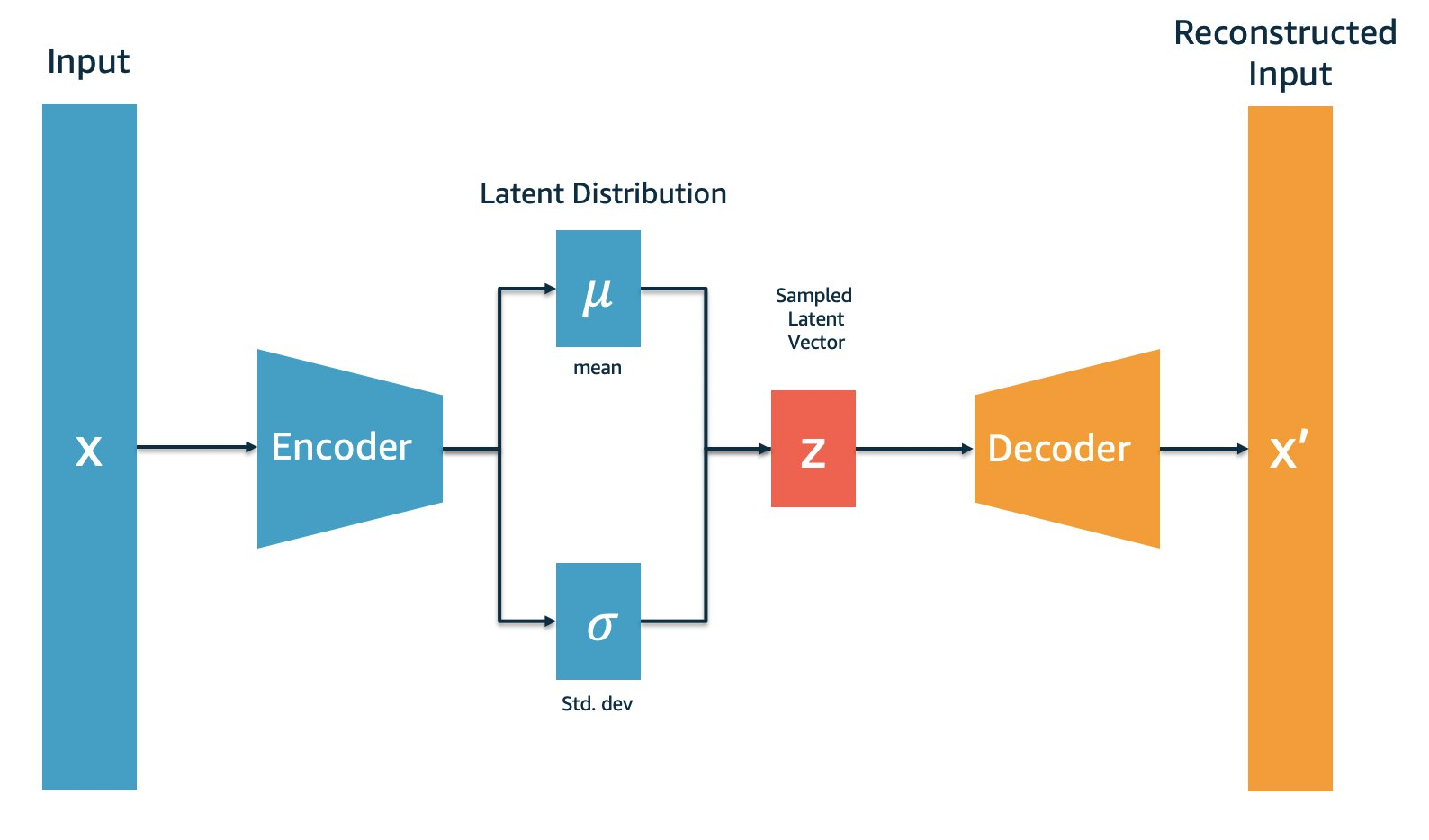
- Latent Space Representation: In VAEs, the encoder outputs parameters of a probability distribution (typically a Gaussian distribution) – mean
 and deviation
and deviation  rather than a single point. The latent variables are then sampled from this distribution:
rather than a single point. The latent variables are then sampled from this distribution: ")
where and are the mean and standard deviation vectors produced by the encoder.  represents the Gaussian distribution.
represents the Gaussian distribution. - Loss Function: The loss function in VAEs includes two components: the reconstruction loss (same as vanilla autoencoders) and the Kullback-Leibler (KL) divergence. The reconstruction loss ensures that the output is similar to the input, while the KL divergence regularizes the latent space to follow a standard normal distribution:
 = \Vert \mathbf{x} - \mathbf{\hat{x}}\Vert^2 - \text{KL}(q(\mathbf{z}|\mathbf{x}) \| p(\mathbf{z}))")
where") is the approximate posterior distribution and
is the approximate posterior distribution and ") is the prior distribution.
is the prior distribution.
For a Gaussian latent space, the KL divergence can be simplified as: - 1 \right)")
where and
and  are the mean and standard deviation of the latent variable
are the mean and standard deviation of the latent variable  , and
, and  is the dimensionality of the latent space.
is the dimensionality of the latent space. - Robustness to Noise: VAEs are more robust to noise and variations in the data because they learn a distribution rather than a single point. This makes them better suited for real-world applications where data can be noisy and imperfect.
- Generative Capabilities: VAEs can generate new data samples that are similar to the training data. This generative capability can be useful for understanding the underlying structure of the data and for creating synthetic data for testing and validation purposes.
- Better Representation of Uncertainty: By learning a distribution, VAEs provide a better representation of the uncertainty in the data. This can be particularly useful for anomaly detection, as it allows the model to quantify the confidence in its predictions and identify anomalies with greater accuracy (Figure 8).
 and deviation
and deviation  rather than a single point. The latent variables
rather than a single point. The latent variables ")
 represents the Gaussian distribution.
represents the Gaussian distribution. = \Vert \mathbf{x} - \mathbf{\hat{x}}\Vert^2 - \text{KL}(q(\mathbf{z}|\mathbf{x}) \| p(\mathbf{z}))")
") is the approximate posterior distribution and
is the approximate posterior distribution and ") is the prior distribution.
is the prior distribution.  - 1 \right)")
 and
and  are the mean and standard deviation of the latent variable
are the mean and standard deviation of the latent variable  , and
, and  is the dimensionality of the latent space.
is the dimensionality of the latent space.
- Flexibility and Adaptability: VAEs can adapt to new and evolving patterns in the data, making them more flexible and effective in dynamic environments where the nature of anomalies can change over time.
Building a Network Intrusion Detection System Using VAEs
In this section, we will see how we can use VAEs for building a network intrusion detection system.
We will start by setting up libraries and data preparation.
Project Setup
For this purpose, we will use the KDD Cup 1999 dataset which is a benchmark dataset widely used for evaluating network intrusion detection systems. The primary task was to build a predictive model capable of distinguishing between “bad” connections (e.g., intrusions or attacks) and “good” normal connections.
The dataset was derived from the 1998 DARPA Intrusion Detection Evaluation Program managed by MIT Lincoln Labs. This program simulated a military network environment and collected 9 weeks of raw TCP dump data from a local area network (LAN) that mimicked a typical U.S. Air Force LAN. The dataset includes approximately 5 million connection records for training and 2 million for testing. Each connection is labeled as either normal or as an attack, with exactly one specific attack type.
To start, we will first download and unzip our dataset files in the system. The KDD Cup 1999 dataset includes several files, each serving a specific purpose for training and evaluating network intrusion detection systems.
kddcup.names: This file contains the list of features used in the dataset. Each feature represents a specific attribute of the network connection records (e.g., duration, protocol type, and number of bytes transferred). This file is essential for understanding the structure of the data and for preprocessing steps.kddcup.data.gz: This is the full training dataset, compressed to save space. It contains approximately 4.9 million connection records, each labeled as either normal or as one of the various types of attacks. This file is used to train the intrusion detection models.corrected.gz: This file contains the test data with corrected labels. It is used to validate the performance of the models by comparing the predicted labels with the actual labels. This file is crucial for assessing the accuracy and effectiveness of the intrusion detection models.
# Downloading the KDD99 dataset $ wget http://kdd.ics.uci.edu/databases/kddcup99/kddcup.data.gz $ wget http://kdd.ics.uci.edu/databases/kddcup99/corrected.gz $ wget http://kdd.ics.uci.edu/databases/kddcup99/kddcup.names # unzipping the files $ gzip -d /content/kddcup.data.gz $ gzip -d /content/corrected.gz
Next, we will install the following packages.
torch: for implementing, training, and evaluating VAEspandas: to load our dataset filesmatplotlib: to plot and visualize the dataset and anomaliesscikit-learn: for computing precision and recall of the systemnumpy: for numerical computation
$ pip install torch pandas matplotlib scikit-learn numpy
Data Visualization
After downloading the dataset, we will load our KDD99 dataset, preprocess various features, and then visualize them via Matplotlib plots. We start by loading the training set in the memory.
import pandas as pd
# reading the training data file
df = pd.read_csv("/content/kddcup.data", header=None)
# reading the file containing feature names
with open("/content/kddcup.names", 'r') as txt_file:
col_names = txt_file.readlines()
col_names_cleaned = [i.split(':')[0] for i in col_names[1:]]
# adding an extra column for the indicator
col_names_cleaned.extend(['result'])
df.columns = col_names_cleaned
df.head()
On Line 1, we import the pandas library as pd, which is essential for data manipulation and analysis. On Line 4, we read the training data file kddcup.data into a DataFrame df without headers using pd.read_csv(). On Lines 7 and 8, we read the feature names from the kddcup.names file into a list col_names.
On Line 10, we clean the feature names by splitting each line at the colon and taking the first part, effectively removing the data type information. On Line 13, we add an extra column named 'result' to the list of column names to account for the target variable. Finally, on Line 14, we assign these cleaned column names to the DataFrame df, and on Line 15, we display the first few rows of the DataFrame using df.head().
As we can see, the dataset has in total 42 features, including the result column, which indicates whether the data point is normal or an anomaly. Let’s visualize the distribution of the result column to see how many normal and anomalous data points we have in our training dataset.
import matplotlib.pyplot as plt
df['result'].value_counts().plot(kind='bar', figsize=(6, 3))
plt.suptitle('Distribution of Result Column - Complete data ')
plt.show()
Figure 9 shows the distribution plot of the result column on the entire dataset.
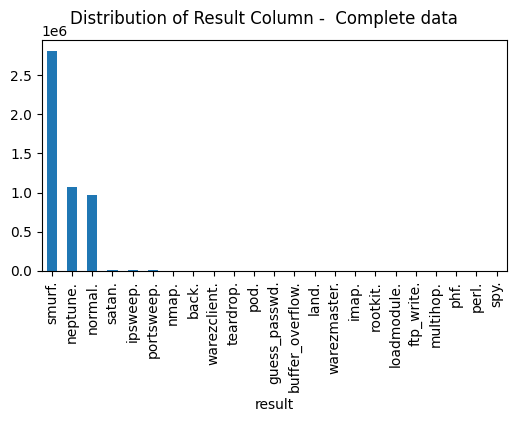
result column on the entire dataset (source: image by the author).From the figure, we can see that the dataset has more anomalies than normal data. So, we consider only a particular service (e.g., 'http' service) where the anomalies are significantly lower.
As there are many types of services in the dataset, and each service has a different signature and characteristics, we fixate on data that has only 'http' as the service. Let’s visualize the distribution plot of the result column again, but only for the 'http' service.
df_http = df[df.service == 'http']
df_http['result'].value_counts().plot(kind='bar', figsize=(6, 3))
plt.suptitle('Distribution of Result Column - "Service: HTTP')
plt.show()
Figure 10 shows the distribution plot of the result column where the service type is 'http'.
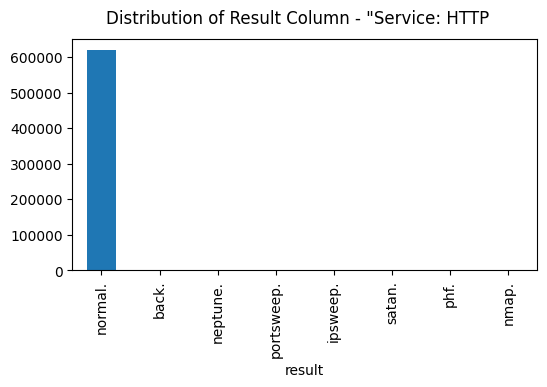
result column on the entire dataset where the service type is 'http' (source: image by the author).From the figure, we can see that, in examples where the service type is 'http', anomalies are rare, making it a realistic assumption.
Data Preprocessing
Moving forward, we will only consider examples where the service type is 'http'. In other words, we will build an intrusion detection system to identify only 'http' anomalies. We will now remove certain feature columns where either the standard deviation is 0 (i.e., their value is the same across the dataset) or the nature is categorical (not very relevant in our case).
from sklearn.preprocessing import StandardScaler from torch.utils.data import TensorDataset, DataLoader import torch df_http_normal = df_http[df_http.result == "normal."] # dropping categorical columns df_http_normal.drop(['protocol_type', 'service', 'flag', 'land', 'logged_in', 'is_host_login', 'is_guest_login', 'result'], axis=1, inplace=True) # dropping columns with no std deviation df_http_normal.drop(['wrong_fragment', 'urgent', 'num_failed_logins', 'su_attempted', 'num_file_creations', 'num_outbound_cmds'], axis=1, inplace=True) df_http_normal.head()
On Lines 25-27, we import the necessary libraries: StandardScaler from sklearn.preprocessing, TensorDataset, and DataLoader from torch.utils.data, and torch. On Line 29, we filter the DataFrame df_http to include only rows where the result column is "normal." and store it in df_http_normal.
On Line 32, we drop categorical columns (e.g., protocol_type, service, flag, and others), as well as the result column, from df_http_normal. On Line 34, we further drop columns with no standard deviation (e.g., wrong_fragment, urgent, and others) to remove features that do not provide useful information. Finally, on Line 36, we display the first few rows of the cleaned DataFrame using df_http_normal.head().
After removing the unnecessary feature columns, we can see that the dataset now has only 28 features (as shown in Figure 11).
We will preprocess these features to standard normal distribution before converting them into PyTorch tensors.
# Step 1: transforming data to zero mean, std dev as one scaler = StandardScaler() X = df_http_normal.to_numpy() X_scaled = scaler.fit_transform(X) print(X_scaled.shape) # Step 2: Convert the NumPy array to a PyTorch tensor X_scaled = torch.tensor(X_scaled, dtype=torch.float32) # Step 3: Create a TensorDataset dataset = TensorDataset(X_scaled, X_scaled) # For autoencoder, input and target are the same # Step 4: Create a DataLoader batch_size = 128 dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
On Line 38, we initialize a StandardScaler to normalize the data. On Line 40, we convert the DataFrame to a NumPy array X, and on Lines 42 and 43, we scale it. On Line 46, we convert the scaled array to a PyTorch tensor. On Line 49, we create a TensorDataset with the same input and target. Finally, on Lines 52 and 53, we create a DataLoader with a batch size of 128 for efficient data loading and shuffling.
Implementing and Training a VAE
Next, we will implement our variational autoencoder and its loss functions. The final feature vector is 28-dimensional, which means that our VAE will encode and decode a 28-dimensional input vector.
import torch.nn as nn
import torch.optim as optim
# Define the VAE model
class VAE(nn.Module):
def __init__(self):
super(VAE, self).__init__()
# Encoder
self.encoder = nn.Sequential(
nn.Linear(28, 14),
nn.ReLU(),
nn.Linear(14, 7)
)
self.mu_layer = nn.Linear(7, 2) # Mean layer
self.logvar_layer = nn.Linear(7, 2) # Log-variance layer
# Decoder
self.decoder = nn.Sequential(
nn.Linear(2, 7),
nn.ReLU(),
nn.Linear(7, 14),
nn.ReLU(),
nn.Linear(14, 28)
)
def encode(self, x):
h = self.encoder(x)
mu = self.mu_layer(h)
logvar = self.logvar_layer(h)
return mu, logvar
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
return self.decoder(z)
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparameterize(mu, logvar)
return self.decode(z), mu, logvar
# Loss function
def loss_function(recon_x, x, mu, logvar):
MSE = nn.functional.mse_loss(recon_x, x)
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return MSE + KLD
This code defines a Variational Autoencoder (VAE) model using PyTorch. On Lines 54 and 55, we import the necessary modules from PyTorch. On Lines 58-77, we define the VAE class, which includes an encoder and a decoder. The encoder reduces the input dimensions from 28 to 7 through a series of linear layers and ReLU activations, and then splits into two layers for the mean (mu_layer) and log-variance (logvar_layer).
On Lines 79-83, we define the encode method to pass input data through the encoder and obtain mu and logvar. On Lines 85-88, the reparameterize method generates a latent variable z using the reparameterization trick. On Lines 90 and 91, the decode method reconstructs the input from z (Lines 95) using the decoder.
On Lines 93-96, the forward method combines the encoding, reparameterization, and decoding steps to produce the reconstructed output, mu, and logvar. On Lines 99-102, we define the loss_function, which calculates the reconstruction loss (MSE) and the Kullback-Leibler divergence (KLD) to ensure the latent space follows a normal distribution. The total loss is the sum of MSE and KLD.
Now, it is time to train our VAE on the normal "http" traffic data.
device = "cuda" if torch.cuda.is_available() else "cpu"
# Initialize the model, loss function, and optimizer
model_vae = VAE()
model_vae.to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam(model_vae.parameters(), lr=0.001)
# Training loop
num_epochs = 5
for epoch in range(num_epochs):
for index, (inputs, labels) in enumerate(dataloader):
inputs, labels = inputs.to(device), labels.to(device)
recon, mu, logvar = model_vae(inputs)
loss = loss_function(recon, inputs, mu, logvar)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if index%1000 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Iteration {index}, Loss: {loss.item():.4f}')
print("Training complete!")
On Line 103, we set the device to "cuda" if a GPU is available, otherwise "cpu". On Lines 106 and 107, we initialize the VAE model and move it to the selected device. On Lines 109 and 110, we define the loss function (MSELoss) and the optimizer (Adam) with a learning rate of 0.001.
On Lines 113 and 114, we run the training loop for 5 epochs. For each batch, on Lines 115 and 116, we move the inputs and labels to the selected device. On Line 117, we pass the inputs through the model to get the reconstructed output, mean (mu), and log-variance (logvar). On Lines 118-122, we compute the loss using the custom loss_function, then backpropagate and update the model parameters. On Lines 124 and 125, we print the loss every 1000 iterations. Finally, on Line 127, we print "Training complete!" to indicate the end of the training process.
Evaluating the IDS on Test Data
After training our VAE, it is time to use it for intrusion detection and evaluation of the test dataset. We start by loading and pre-processing the test set just like our training set.
# loading the test dataframe
test_df = pd.read_csv("/content/corrected", header=None, names=col_names_cleaned)
test_df_http = test_df[test_df.service == "http"]
test_df_http["target"] = test_df_http["result"].apply(lambda x: 1 if x!="normal." else 0)
target = test_df_http["target"].to_numpy()
print(test_df_http["target"].value_counts())
# dropping categorical columns
test_df_http.drop(['protocol_type', 'service', 'flag', 'land', 'logged_in', 'is_host_login', 'is_guest_login', 'result', 'target'], axis=1, inplace=True)
# dropping columns with no std deviation
test_df_http.drop(['wrong_fragment', 'urgent', 'num_failed_logins', 'su_attempted', 'num_file_creations', 'num_outbound_cmds'], axis=1, inplace=True)
X_test = test_df_http.to_numpy()
X_scaled_test = scaler.transform(X_test)
# Step 1: Convert the NumPy array to a PyTorch tensor
X_scaled_test = torch.tensor(X_scaled_test, dtype=torch.float32)
print(X_scaled_test.shape)
On Lines 129 and 130, we load and filter the test data for the "http" service. On Lines 132-134, we create a target column to label anomalies and convert it to a NumPy array, printing the counts.
On Line 137, we drop categorical and target columns, and on Line 139, we drop columns with no standard deviation. On Lines 141 and 142, we convert the DataFrame to a NumPy array and scale it. On Lines 145 and 146, we convert the scaled array to a PyTorch tensor and print its shape.
Next, we will perform the reconstruction on the test set and compute the reconstruction losses. Then, we select a threshold value for the reconstruction loss above which we will classify the data point as an anomaly.
from sklearn.metrics import precision_score, recall_score
import numpy as np
with torch.no_grad():
X_scaled_test_recon, _, _ = model_vae(X_scaled_test.to(device))
loss_test = torch.nn.functional.mse_loss(X_scaled_test_recon.to(device), X_scaled_test.to(device), reduction='none').sum(1).cpu().numpy()
# normalize reconstruction loss in zero to one
loss_test = loss_test - loss_test.min()
loss_test = loss_test/(loss_test.max())
# select a threshold for predictions
predictions = (loss_test > 0.005).astype(np.int64)
# Calculate precision and recall
precision = precision_score(target, predictions )
recall = recall_score(target, predictions )
print("Total anomalies : ", target.sum())
print("Detected anomalies : ", predictions.sum())
print("Correct anomalies : ", (predictions*target).sum())
print("Missed anomalies : ", ((1-predictions)*target).sum())
print(f'Precision: {precision:.2f}, Recall: {recall:.2f}, F1: {(2*precision*recall)/(precision + recall):.2f}')
Output
Total anomalies : 1990 Detected anomalies : 2003 Correct anomalies : 1912 Missed anomalies : 78 Precision: 0.95, Recall: 0.96, F1: 0.96
On Lines 147 and 148, we import the precision_score and recall_score utilities for evaluating model performance. Additionally, we import numpy for numerical operations. On Line 150, inside a torch.no_grad() context, we reconstruct the test data using a trained Variational Autoencoder (VAE) model (model_vae). The VAE generates X_scaled_test_recon, which represents the reconstructed data.
On Lines 153-157, we compute the reconstruction loss for each test instance using mean squared error (MSE) between the original input (X_scaled_test) and the reconstructed output (X_scaled_test_recon). The loss is normalized to the range [0, 1].
On Line 160, we apply a threshold of 0.005 to classify instances as anomalies or normal. The resulting predictions are stored in the predictions array.
On Lines 163-171, we calculate precision and recall based on ground truth target labels (target). We also print relevant information (e.g., total anomalies, detected anomalies, correct detections (true positives), and missed anomalies (false negatives)). Finally, we compute the F1 score (harmonic mean of precision and recall) and display it.
From the code output, we can see that the system performed well in identifying anomalies, with high precision (95%) and recall (96%).
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In our blog post, “Build a Network Intrusion Detection System with Variational Autoencoders,” we delve into the critical role of anomaly detection in safeguarding network security. We start by explaining what network intrusion is and why advanced Intrusion Detection Systems (IDS) are essential in today’s digital landscape. Understanding the nature of network intrusions helps us appreciate the necessity for sophisticated IDS that can detect and mitigate potential threats effectively.
We then explore the concept of autoencoders and their application in anomaly detection. Autoencoders, a type of neural network, are particularly effective in identifying unusual patterns within data. We discuss why Variational Autoencoders (VAEs) are a preferred choice for this task, highlighting their ability to model complex data distributions and detect anomalies with higher accuracy.
Finally, we guide you through the process of building a Network Intrusion Detection System using VAEs. This includes setting up the project, visualizing and preprocessing the data, and implementing and training the VAE model. We also cover how to evaluate the IDS on test data to ensure its effectiveness. By the end of the post, you’ll have a comprehensive understanding of how to leverage VAEs for robust network security.
Citation Information
Mangla, P. “Build a Network Intrusion Detection System with Variational Autoencoders,” PyImageSearch, P. Chugh, S. Huot, and P. Thakur, eds., 2024, https://pyimg.co/b8jfw
@incollection{Mangla_2024_build-network-ids-vae,
author = {Puneet Mangla},
title = {Build a Network Intrusion Detection System with Variational Autoencoders},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Piyush Thakur},
year = {2024},
url = {https://pyimg.co/b8jfw},
}
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.