Table of Contents
NeRFs Explained: Goodbye Photogrammetry?
In this blog post, you will learn about 3D Reconstruction.

This lesson is the 2nd of a 3-part series on 3D Reconstruction:
- Photogrammetry Explained: From Multi-View Stereo to Structure from Motion
- NeRFs Explained: Goodbye Photogrammetry? (this tutorial)
- 3D Gaussian Splatting: The End Game of 3D Reconstruction?
To learn more about 3D Reconstruction, just keep reading.
NeRFs Explained: Goodbye Photogrammetry?
One day, I was looking for an email idea while writing my daily self-driving car newsletter, when I was suddenly caught by the news: Tesla had released a new FSD12 model based on End-to-End Learning.
“Interesting”, I said out loud. And it was because not only was the new model fully based on Deep Learning, but it also effectively removed 300,000 lines of code.
From a series of modular blocks, doing Perception of the surroundings, Localization of the car in the lane, Planning of the next trajectory, and Control of the steering wheel… they moved to a Deep Neural Network that took the images in and predicted the direction to take as output.
Neural Radiance Fields are somehow similar: they don’t remove 300,000 lines of code, but they remove many of the geometric concepts needed in 3D Reconstruction, and in particular in Photogrammetry.
And that is the topic of this blog post #2 on NeRFs. You can also read blog post #1 on Photogrammetry here, and our journey will later take us to blog post #3 on 3D Gaussian Splatting. Incidentally, you can also learn about Tesla’s new End-to-End algorithms here.
So, let’s begin with a simple question:
What is a “Radiance Field”?
The first time I tried to learn about neural radiance fields, I realized a problematic thing: I forgot what the radiance was. I mean, I had to go back to my optics classes to remotely remember the idea… And let me show it to you:
The radiance is defined as the amount of light at a particular point in a specified direction.
Basically, it’s an intensity. “How much light is there here?”
So now you can guess what a radiance “field” is about… It’s an array of radiances. What is the light here? Here? And here? We’re storing all of these. And the “neural” radiance field estimates it using Neural Networks.
So now we are ready.
How Do NeRFs Work?
NeRFs estimate the light, density, and color of every point in the… hum… air… and does so using 3 blocks: input, neural net, and rendering.

A Neural Radiance Field is made of 3 blocks representing the input, neural net, and rendering.
Let’s look at these blocks one by one…
Block #A: We Begin with a 5D Input

In NeRFs, we don’t take one image to a 3D model, we take multiples, just like in “multi” view stereo. You start by capturing the scene from multiple viewpoints, a good 20/30 pictures, if not more…

From there, we’re going to do what’s named “Ray Generation.” We’ll shoot a ray for every pixel in each image. It can look like this for a single ray:

Yes, if you have lots of high-resolution images, it can get consequent; we’ll get to this later. For now, let’s try to understand the “5D input” we have:
- X, Y, and Z represent the 3D position of a point along the ray. Not only are we creating a ray, but we’re also setting points along that ray. For every point in the 3D space, our goal will be to calculate its color and density.
- θ and ɸ represent the azimuthal and polar angle. It’s the viewing direction. Not only does every point matter, but an object can look differently from one viewpoint than from another. This is how you get nice reflections and reactions to light.
See here how the reflections are produced, this is because our very input includes the viewing direction.

Block #B: The Neural Network and Its Output
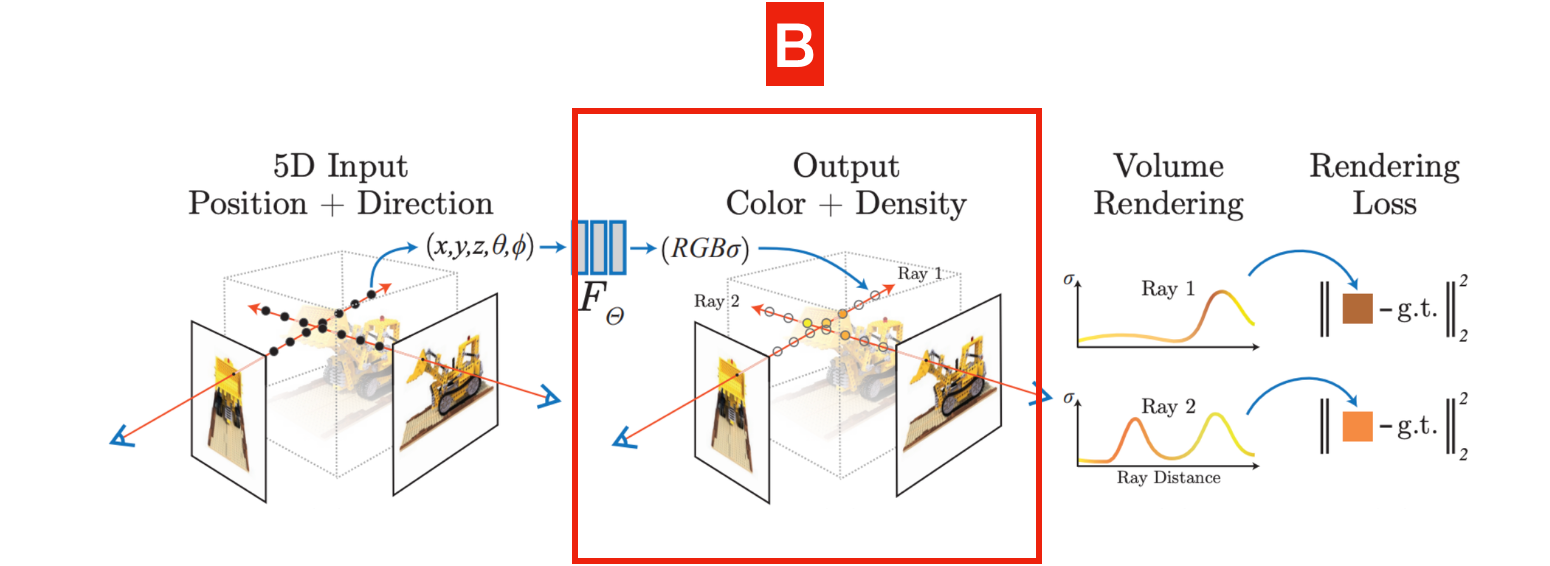
In our case, the Neural Network is a super simple multi-layer perceptron (MLP). Its goal is to regress the color and density of every point of every ray. For this, there’s a technique named “Ray Marching”, which consists of setting points along the ray, and then for every point, query the neural network and predict the radiance (color and density).

How it works:
- We create a ray.
- We split it into several points.
- For every point, we call a linear model.
In the end, we really predict 4 values: R, G, B, and sigma (density).
So, at this point, we have created rays for every pixel, and then selected points on the ray, and predicted a color and density for each of them. This prediction is explained in block C.
Block #C: Volumetric Rendering

To accurately render a 3D scene, we first have to remove points that belong to the “air”. For each point, we’ll wonder whether or not we’re actually hitting an object via the predicted density.
You can see a distribution function here, notice the steps, and how we’re implementing the “marching”, the density check, and then predicting the color:
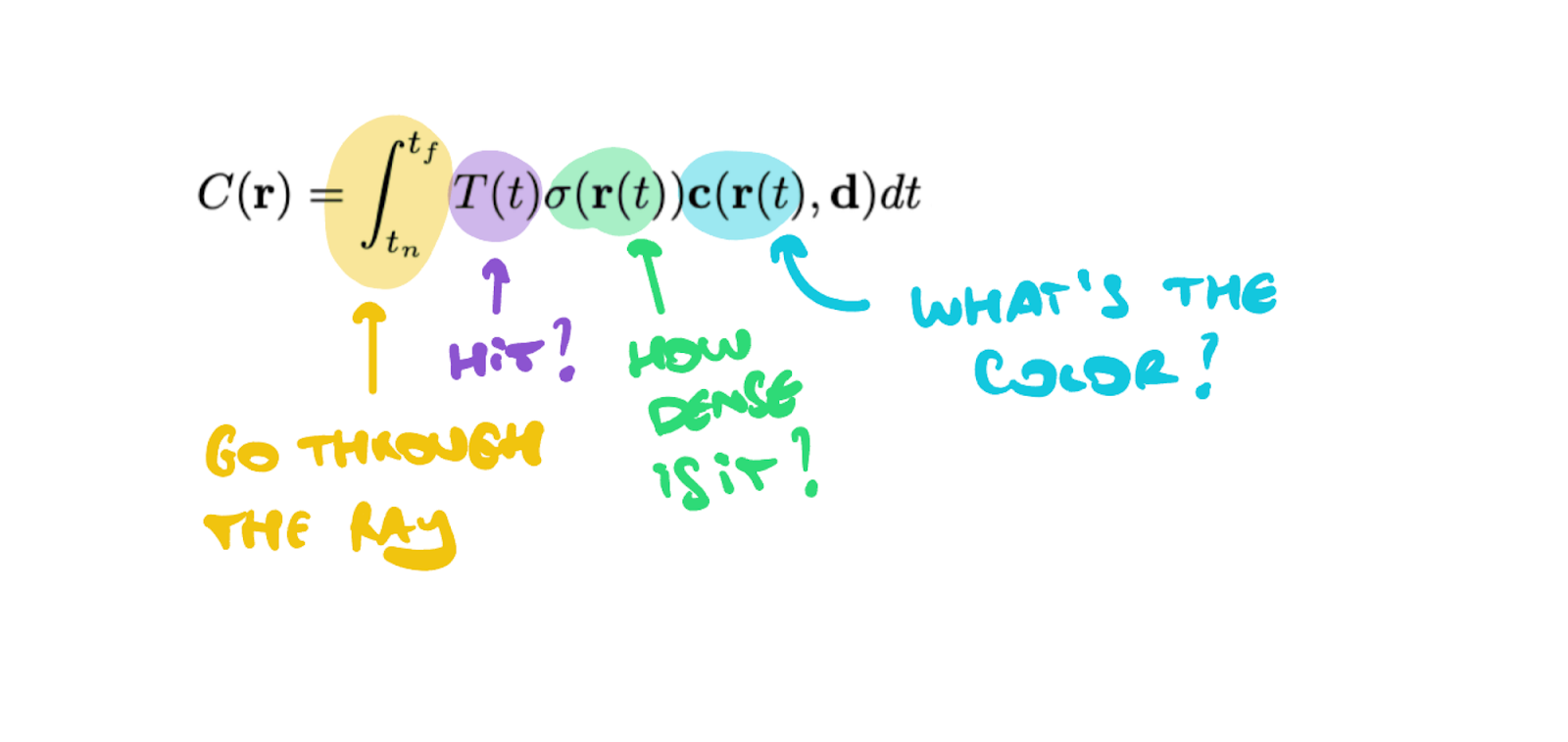
For every point of the ray, learn whether it hits an object, how dense it is, and what’s the color.
Now, this is one element of the rendering. There are others, including the use of Structure from Motion, training, sparse and coarse neural networks, and more… We can get into more details in future content, but for now, you get the gist.
So imagine if we were to code that, how would we do?
I have written a basic Keras sample, and here is what it looks like:
If we were to define it in Keras, it could look like this:
def init_model(D=8, W=256):
relu = tf.keras.layers.ReLU()
dense = lambda W=W, act=relu : tf.keras.layers.Dense(W, activation=act)
inputs = tf.keras.Input(shape=(3 + 3*2*L_embed))
outputs = inputs
for i in range(D):
outputs = dense()(outputs)
if i%4==0 and i>0:
outputs = tf.concat([outputs, inputs], -1)
outputs = dense(4, act=None)(outputs)
model = tf.keras.Model(inputs=inputs, outputs=outputs)
return model
Notice the simplicity: it’s just a few sets of linear layers! What it does is to simply generate rays (not shown here), and for each point along the ray, predict the color and density by calling a Multi-Layer Perceptron! In the end, we concatenate everything into a single output.
Awesome, so you have a high-level idea of how NeRFs work, but do you notice a problem?
The NeRF Problem and Evolutions
Let’s say you take 30 pictures of an object, all in 1980 × 720 resolution. How many rays do you get? If we do the math, we get 30 × 1980 × 720 = 42.5M rays.
Now, there’s also the ray marching, where we split a ray into equidistant points, let’s say 64, and for each point, we call a neural network. This means we have 64 times 42.5 million Neural Network queries… or nearly 3 billion!
That’s a lot of compute, which makes NeRFs slow to render. This is why it’s totally an “offline” approach for now, not used in real-time self-driving cars or anything other than taking pictures of an object, and spending 30+ minutes on the reconstruction.
This is why NeRF algorithms have evolved, from Tiny-NeRFs to NeRFs in the wild, to Pixel & KiloNeRFs… Right after its release in 2020, 2021 saw a massive set of evolutions to make NeRFs lighter, faster, and stronger.
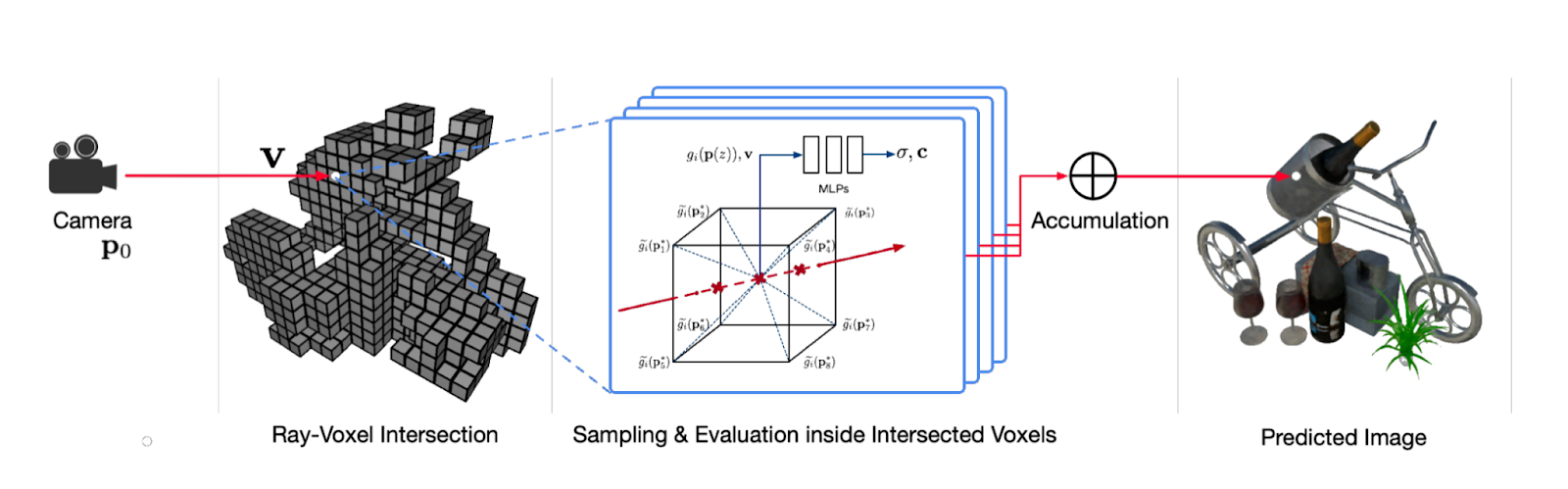
For example, Neural Sparse Voxel Fields (2020) uses voxel ray rendering instead of a regular light ray, and since we can estimate ‘empty’ voxels, it makes it 10x faster than NeRFs, as well as higher quality.
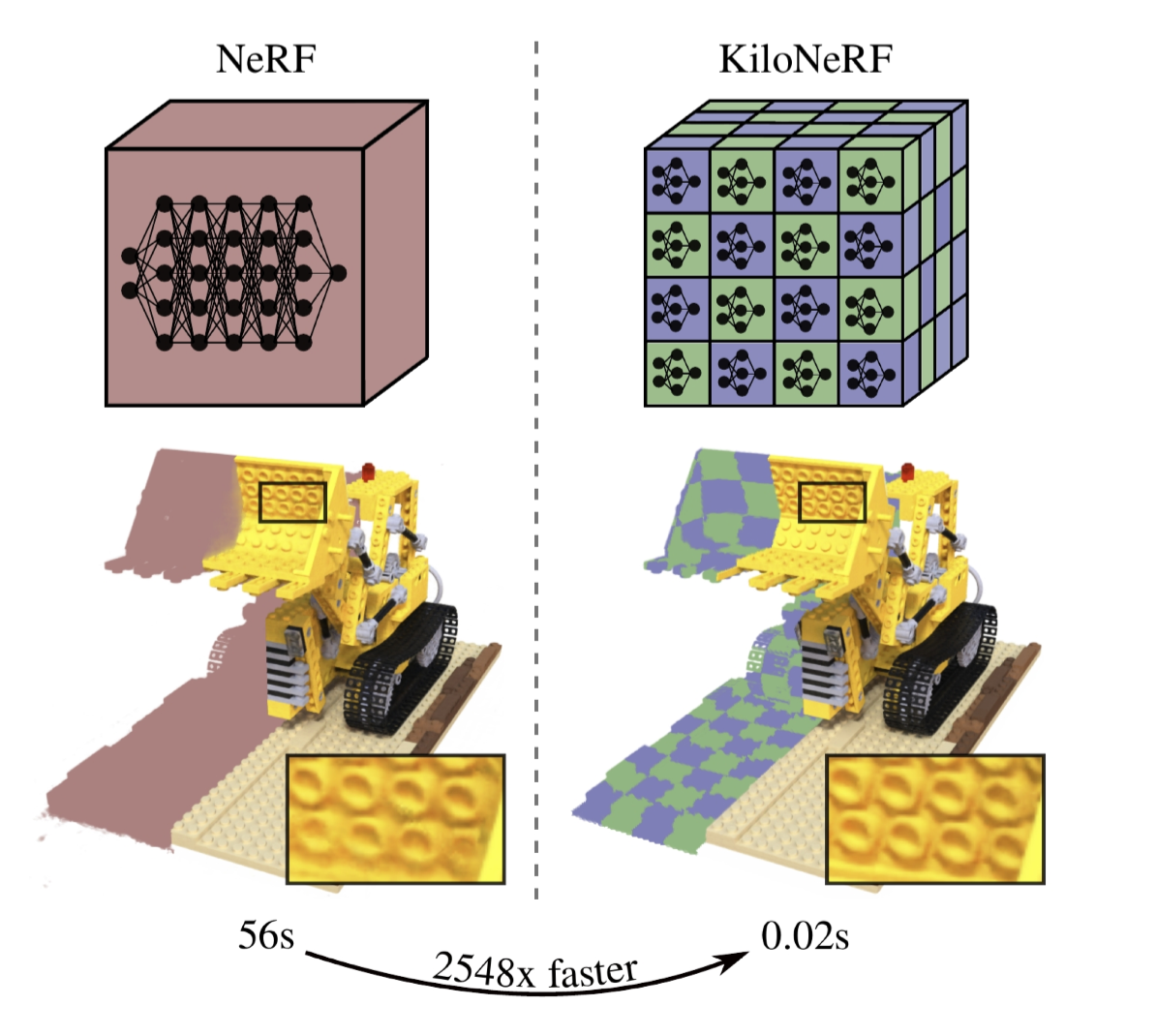
With the same objective, KiloNeRF (2021) uses thousands of mini-MLPs, rather than calling one MLP a million times. It’s a pure “divide and conquer” strategy that allows it to work on bigger scenes, uses parallelization, optimizes the memory, and makes it 2,500x faster, all while keeping the same resolution!
NeRFs are interesting, but you may notice they’re pretty “random.” We shoot rays all over the place and try to construct something out of it. Does it work? It does, but it’s not that efficient. Since 2023/2024, a new algorithm has made a lot of noise… Gaussian Splatting!
This will be the topic in an upcoming blog post of this series. In the meantime, let’s do a summary.
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary and Next Steps
- While Photogrammetry is all about geometric reconstruction, NeRFs is all about removing the geometric constraints and going all Deep Learning.
- As a basic principle, NeRFs work by shooting a ray for each pixel of an image, then splitting the ray into intervals, and predicting the radiance at every step.
- NeRFs work in 3 steps: capture a scene from many viewpoints, shoot rays, and then, for each ray, “march” on it and regress color and density at each point. If a point belongs to the ‘air’, we remove it.
- Since it was first introduced, there have been multiple versions of NeRFs, from tiny-NeRFs, to KiloNeRFs and others, making it faster and better resolution.
Next Steps
If you enjoyed this blog post, I invite you to read my other 3D Computer Vision posts:
- A 5-Step Guide to Build a Pseudo-LiDAR Using Stereo Vision: https://www.thinkautonomous.ai/blog/pseudo-lidar-stereo-vision-for-self-driving-cars/
- Computer Vision: From Stereo Vision to 3D Reconstruction: https://www.thinkautonomous.ai/blog/3d-computer-vision/
How to obtain an Intermediate/Advanced Computer Vision Level?
I have compiled a bundle of Advanced Computer Vision resources for PyImageSearch Engineers who wish to join the intermediate/advanced area. When joining, you’ll get access to the Computer Vision Roadmap I teach to my paid members, and on-demand content on advanced topics like 3D Computer Vision, Video Processing, Intermediate Deep Learning, and more from my paid courses — all free.
Instructions here: https://www.thinkautonomous.ai/py-cv
Citation Information
Cohen, J. “NeRFs Explained: Goodbye Photogrammetry?” PyImageSearch, P. Chugh, S. Huot, R. Raha, and P. Thakur, eds., 2024, https://pyimg.co/sbhu7
@incollection{Cohen_2024_NeRFs-Explained-Goodbye-Photogrammetry,
author = {Jeremy Cohen},
title = {NeRFs Explained: Goodbye Photogrammetry?},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Ritwik Raha and Piyush Thakur},
year = {2024},
url = {https://pyimg.co/sbhu7},
}

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.