Table of Contents
- Setting Up GitHub Actions CI for FastAPI: Intro to Taskfile and Pre-Jobs
- Brief Overview of What We’ve Covered So Far
- The Importance of CI in Modern Software Development
- What Readers Will Learn in This Post
- Configuring Your Development Environment
- Project Directory Structure for Following Lessons
- Taskfile for Automation
- Setting Up the CI Pipeline
- Summary
Setting Up GitHub Actions CI for FastAPI: Intro to Taskfile and Pre-Jobs
In this guide, you’ll discover how to configure a GitHub Actions CI pipeline for a Python FastAPI application, emphasizing Taskfile automation and the strategic use of pre-jobs. We’ll walk you through setting up your project environment, automating routine tasks, managing dependencies effectively, and optimizing the CI workflow for better performance.

Gain valuable insights into leveraging Taskfile and pre-job configurations in GitHub Actions, along with practical advice to refine your CI pipeline and improve workflow productivity.
In the ever-evolving landscape of software development, ensuring the quality, reliability, and speed of your applications is paramount. This is where Continuous Integration (CI) becomes indispensable. CI is not just a buzzword; it’s a critical practice that enables teams to catch bugs early, streamline development workflows, and maintain high standards of code quality. Especially when working with modern frameworks like FastAPI, a robust CI pipeline can be the difference between smooth, rapid development and a chaotic, error-prone process.
This lesson is the 2nd in a 4-part series on GitHub Actions:
- Introduction to GitHub Actions for Python Projects
- Setting Up GitHub Actions CI for FastAPI: Intro to Taskfile and Pre-Jobs (this tutorial)
- Lesson 3
- Lesson 4
To learn how to set up a CI pipeline for Python FastAPI applications with GitHub Actions, leveraging Taskfile automation and pre-jobs, just keep reading.
Brief Overview of What We’ve Covered So Far
In our series so far, we’ve laid a strong foundation for understanding CI/CD pipelines. The journey began with an introduction to GitHub Actions for Python Projects, where we delved into the concepts of Continuous Integration, Continuous Delivery, and Continuous Deployment. We discussed why these practices are essential for maintaining high-quality software, and we provided a high-level overview of what a typical CI/CD pipeline looks like, using sample Python projects as practical examples.
Before diving into CI/CD, we also published a detailed guide on deploying a Vision Transformer (ViT) model using FastAPI. This post served as a practical precursor to our current series, showcasing how to build and deploy a machine learning model API with FastAPI. The deployment of the ViT model demonstrated the complexities involved in managing and deploying a FastAPI application, highlighting the need for automation through CI. This experience laid the groundwork for integrating a CI pipeline, which we’ll explore in detail in this post.
The Importance of CI in Modern Software Development
Continuous Integration has become a cornerstone of modern software development practices. By integrating code changes frequently and running automated tests on each change, CI ensures that new code integrates seamlessly with the existing codebase. This practice is especially crucial in today’s fast-paced development environments, where multiple developers might be contributing to the same project simultaneously. CI helps in identifying issues early, reducing the time spent on debugging, and ensuring that the codebase remains stable throughout the development process.
For FastAPI applications, which are often used to build APIs and microservices, the importance of CI cannot be overstated. Given that these applications may need to handle numerous requests simultaneously, ensuring that they are robust, efficient, and free of bugs is critical. A well-designed CI pipeline helps maintain these standards, allowing developers to focus on writing new features rather than worrying about breaking existing functionality.
What Readers Will Learn in This Post
In this post, we will lay the groundwork for building a robust CI pipeline specifically tailored for a Python FastAPI application using GitHub Actions. Here’s what you’ll learn:
- Setting Up GitHub Actions for FastAPI: How to create a Continuous Integration (CI) workflow using GitHub Actions, including configuring triggers for when the pipeline should run.
- Introduction to Taskfile Automation: How to use Taskfile to automate repetitive tasks such as installing dependencies, running linters, and executing tests, making your CI pipeline more efficient and easier to maintain.
- Understanding and Implementing Pre-Jobs: An in-depth look at pre-jobs in GitHub Actions to optimize your CI pipeline by skipping redundant workflows and ensuring only relevant tasks trigger a full run.
The focus here is on setting up the foundational elements of a CI pipeline using Taskfile and GitHub Actions pre-jobs. At the same time, subsequent blog posts will cover building, testing, and publishing steps in more detail.
By the end of this tutorial, you’ll learn how to incorporate Taskfile automation and pre-jobs to enhance your CI workflow. This knowledge will help you automate routine tasks, optimize CI runs, and maintain a clean, efficient, and manageable codebase, setting the stage for more advanced CI/CD practices in future posts.
Configuring Your Development Environment
Since this is a CI/CD-focused lesson, you might expect to configure and install the necessary libraries for running code locally. However, in this case, libraries (e.g., FastAPI, Pillow, Gunicorn, PyTest, and Flake8), although required, are only needed within the CI pipeline itself. These dependencies will be installed automatically when the pipeline runs in GitHub Actions, meaning there’s no need to configure them on your local development environment unless you’re testing locally.
To clarify: in this guide, the requirements.txt file in your repository ensures that GitHub Actions installs all required packages for you during the pipeline execution. Therefore, you can skip installing these dependencies locally unless you’re developing or testing outside the CI pipeline.
Can You Test a CI Pipeline Locally?
Yes, while GitHub Actions primarily runs your pipeline in the cloud, there are ways to simulate or test your CI pipeline locally. One option is to use tools like act (a tool that lets you run GitHub Actions locally), which mimics the GitHub Actions environment and allows you to catch issues before pushing code. Another approach is to locally run individual scripts or steps (e.g., your PyTest, linting, and build tasks) using your terminal to ensure there are no issues before triggering the pipeline on GitHub.
This allows for faster feedback and testing of changes without waiting for the entire CI pipeline to run in GitHub.
Fortunately, all these packages are easily installable via pip. You can use the following commands to set up your environment:
$ pip install -q fastapi[all]==0.98.0 $ pip install -q Pillow==9.5.0 $ pip install -q gunicorn==20.1.0 $ pip install -q pytest==8.2.2 $ pip install -q pytest-cov==5.0.0 $ pip install -q flake8==7.1.0
Need Help Configuring Your Development Environment?

All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code immediately on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Project Directory Structure for Following Lessons
We first need to review our project directory structure.
Start by accessing the “Downloads” section of this tutorial to retrieve the source code and example images.
From there, take a look at the directory structure:
.
├── .github
│ └── workflows
│ ├── cd.yml
│ └── ci.yml
├── deployment
│ ├── Taskfile.yml
│ ├── docker
│ │ └── Dockerfile
│ └── scripts
│ └── clean_ghcr_docker_images.py
├── main.py
├── model.script.pt
├── pyimagesearch
│ ├── __init__.py
│ └── utils.py
├── requirements.txt
├── setup.py
└── tests
├── test_image.png
├── test_main.py
└── test_utils.py
7 directories, 14 files
In the .github/workflows/ directory, we have:
ci.yml: This GitHub Actions workflow defines the Continuous Integration (CI) process. It specifies the steps to build, test, and package the application whenever there’s a change in the codebase. This includes tasks like running unit tests, linting the code, and creating a release if a new version is tagged.cd.yml: The workflow that will handle Continuous Deployment (CD), including building Docker images and pushing them to a container registry. We’ll explore this in detail in an upcoming lesson.
In the deployment/ directory, we have:
Taskfile.yml: This file defines various tasks that can be run during the CI process (e.g., installing dependencies, linting the code, and running tests). The use of aTaskfileallows us to automate these processes and ensure consistency across different environments.docker/: Contains theDockerfileused for containerizing the application. This will be covered in an upcoming lesson when we discuss Continuous Deployment (CD).scripts/: Includes utility scripts (e.g.,clean_ghcr_docker_images.py), which are used to clean up old Docker images in the GitHub Container Registry (GHCR). This will also be covered in the CD lesson.
In the pyimagesearch directory, we have:
__init__.py: Initializes the module, allowing for easier imports and organization within thepyimagesearchdirectory.utils.py: Contains utility functions for tasks such as loading the model, processing images, and performing inference. These utilities help keep the codebase modular and maintainable. This was covered in the FastAPI deployment blog post.
In the root directory, we have:
main.py: The main script that sets up the FastAPI application, defines API endpoints, and handles requests for inference and health checks. This was thoroughly discussed in the FastAPI deployment blog post.model.script.pt: The serialized PyTorch model that is used for inference within the application.requirements.txt: Lists all the dependencies needed to run the FastAPI application, including specific versions of libraries like Torch and FastAPI. This file is essential for ensuring that all dependencies are installed consistently across different environments. In our CI pipeline, this file is used to install the necessary packages before running tests and building the application.setup.py: This script is used for packaging the application, allowing it to be easily installed or distributed as a Python package. It defines the package details, dependencies, and entry points. In the CI process,setup.pyis used to build the wheel file, which is then published as part of the release process.
In the tests directory, we have:
test_image.png: A sample image used to verify that the model’s inference capabilities are functioning correctly.test_main.py: Unit tests for the main application, particularly focusing on the FastAPI endpoints. While these tests were covered in the FastAPI deployment blog post, in this tutorial, we’ll show how they are integrated into the CI pipeline to ensure continuous testing.test_utils.py: Unit tests for the utility functions inutils.py. These tests help verify that any changes to utility functions do not introduce bugs. Again, these tests were covered previously, but here, we’ll focus on how they are used within the CI pipeline.
This directory structure sets up the foundation for our CI/CD pipeline. While some components were discussed in previous posts (e.g., the FastAPI deployment tutorial), the focus of this blog post is on the CI pipeline, which ensures that the application is consistently tested and validated with each code change. The components related to Continuous Deployment (e.g., Dockerfile and cd.yml) will be explored in two upcoming lessons.
Taskfile for Automation
Automation is a cornerstone of any robust CI pipeline, and the Taskfile serves as a powerful tool to streamline and simplify repetitive tasks. A Taskfile is a YAML configuration file that allows you to define and execute tasks within your project. These tasks can range from installing dependencies to running tests, ensuring that your CI pipeline remains clean, organized, and efficient.

In this section, we’ll explore how the Taskfile is structured and how it helps automate various steps in your CI pipeline. We’ll cover the tasks that are crucial for setting up the FastAPI project (e.g., dependency installation, linting, and testing).
Overview of Taskfile.yml
Below is a simplified version of the Taskfile.yml used in this project. This Taskfile includes tasks that are essential for setting up and validating your FastAPI application within the CI pipeline. We’ll focus on the tasks (e.g., deps, lint, and test), which are directly relevant to the CI process. Tasks related to Docker and image scanning (e.g., scan, scan-report-json, bom-report-json, and clean-ghcr-repo) will be covered in an upcoming blog post as part of the Continuous Deployment (CD) setup.
version: '3'
tasks:
deps:
desc: Install dependencies
cmds:
- |
cd ..
python -m pip install --upgrade pip
pip install -r requirements.txt
pip install torch==2.3.1+cpu torchvision==0.18.1+cpu --extra-index-url https://download.pytorch.org/whl/cpu
lint:
desc: Lint the code
cmds:
- |
cd ..
flake8 . --count --select=E9,F63,F7,F82 --show-source --statistics
flake8 . --count --exit-zero --max-complexity=10 --max-line-length=127 --statistics
test:
desc: Run tests
cmds:
- |
cd ..
pytest --cov=pyimagesearch --junitxml=junit_result.xml --cov-report=xml --cov-report=html tests/
Tasks Breakdown
deps: Install Dependencies
The deps task is responsible for installing all necessary dependencies for the project. This includes upgrading pip, installing packages listed in requirements.txt, and specific versions of PyTorch and TorchVision for CPU processing.
This task ensures that the correct versions of all dependencies are installed, which is crucial for the consistency and reliability of your application during testing and deployment.
cmds:
- |
cd ..
python -m pip install --upgrade pip
pip install -r requirements.txt
pip install torch==2.3.1+cpu torchvision==0.18.1+cpu --extra-index-url https://download.pytorch.org/whl/cpu
This command navigates to the root directory, upgrades pip, and installs the required packages from requirements.txt, along with specific versions of torch and torchvision.
lint: Lint the Code
The lint task runs flake8, a tool for checking the style and quality of your Python code. It checks for syntax errors, adherence to coding standards, and other stylistic issues.
Linting is a critical step in maintaining code quality. It helps catch potential bugs and enforces coding standards before the code is tested or merged.
cmds:
- |
cd ..
flake8 . --count --select=E9,F63,F7,F82 --show-source --statistics
flake8 . --count --exit-zero --max-complexity=10 --max-line-length=127 --statistics
This command runs flake8 with specific options to check for errors and enforce complexity and line-length limits.
test: Run Tests
The test task executes the unit tests using pytest. It also generates test coverage reports in both XML and HTML formats, which can be uploaded as artifacts in the CI pipeline.
Running tests as part of the CI pipeline ensures that any new changes do not break existing functionality. It provides immediate feedback to developers and maintains the integrity of the codebase.
cmds:
- |
cd ..
pytest --cov=pyimagesearch --junitxml=junit_result.xml --cov-report=xml --cov-report=html tests/
This command runs pytest on the tests/ directory and generates coverage reports, which are crucial for understanding how much of your code is covered by tests.
To summarize, the Taskfile provides a structured and automated way to handle repetitive tasks within your CI pipeline. By defining tasks for dependency installation, linting, and testing, you ensure that each step of your CI process is executed consistently and efficiently. This not only saves time but also reduces the potential for human error, allowing you to focus on writing code and building features.
In the next section, we’ll discuss how these tasks are integrated into your CI pipeline through the .github/workflows/ci.yml file.
Setting Up the CI Pipeline
The CI pipeline begins with defining when the CI workflow should be triggered and what initial checks need to be performed to make the process efficient. In this section, we’ll cover two main aspects:
- Triggering the CI Workflow
- Pre-Job for Checking Duplicate Actions
Defining the CI Workflow
name: CI
on:
push:
tags:
- '**'
pull_request:
branches:
- main
name: CI: This defines the name of the workflow. In this case, it is named “CI” for Continuous Integration.on: This section specifies the events that will trigger the workflow. Here, the workflow is triggered by two main events:push: The workflow runs when a push occurs, particularly if a tag is pushed (as denoted bytags: '**'). This is useful for running the CI pipeline when you create or update a release tag.pull_request: The workflow also runs when a pull request is opened or updated on themainbranch. This ensures that the code changes are tested before being merged into the main branch.
This setup is crucial for ensuring that your codebase remains stable, as it automatically runs the CI pipeline whenever there are changes that could affect the application.
Understanding Jobs in GitHub Actions
In GitHub Actions, a job is a collection of steps that execute on the same runner (a virtual machine hosted by GitHub or your own server). Jobs are the building blocks of a CI pipeline and can run independently or depend on other jobs.
Key Concepts
- Job Dependency: Jobs can be made to depend on the outcome of other jobs. For example, a
publish-releasejob might depend on the success of abuild-and-testjob. - Parallel Execution: By default, jobs run in parallel unless specified otherwise. This can help speed up the CI pipeline by running independent tasks simultaneously.
In our CI pipeline, the jobs are structured as follows:
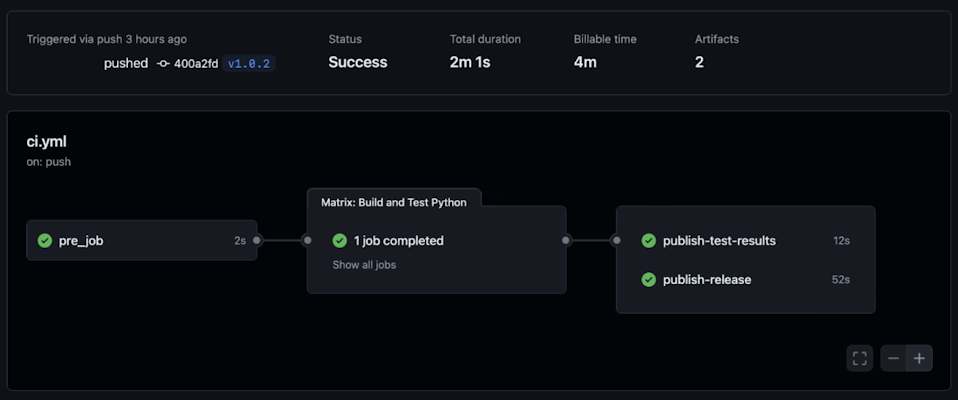
pre_job: This job is designed to optimize the workflow by determining if the CI pipeline can skip unnecessary runs. It checks if the changes made are relevant to the critical parts of the codebase (e.g., source files and important configurations).build-and-test: This job performs the core tasks of building and testing the application. It ensures that the code is functional and passes all the tests before moving on to the next steps.publish-test-results: This job handles the publication of test results, ensuring that the test outcomes are accessible for review.publish-release: Finally, this job deals with creating a release, packaging the application, and uploading it to the specified repository.
Deep Dive into job and pre_job
The jobs section in the GitHub Actions workflow YAML file is where you define different tasks (or jobs) that you want to execute as part of your Continuous Integration (CI) pipeline. Each job runs in its own virtual environment, can have multiple steps, and can depend on other jobs. The jobs are executed in parallel by default unless there are dependencies specified between them.
jobs:
pre_job:
runs-on: ubuntu-latest
outputs:
should_skip: ${{ steps.skip_check.outputs.should_skip }}
steps:
- id: skip_check
uses: fkirc/skip-duplicate-actions@v3.4.1
with:
concurrent_skipping: 'never'
paths_ignore: '["README.md"]'
paths: '["pyimagesearch/**", "docs/**", ".github/workflows/ci.yml", "setup.py"]'
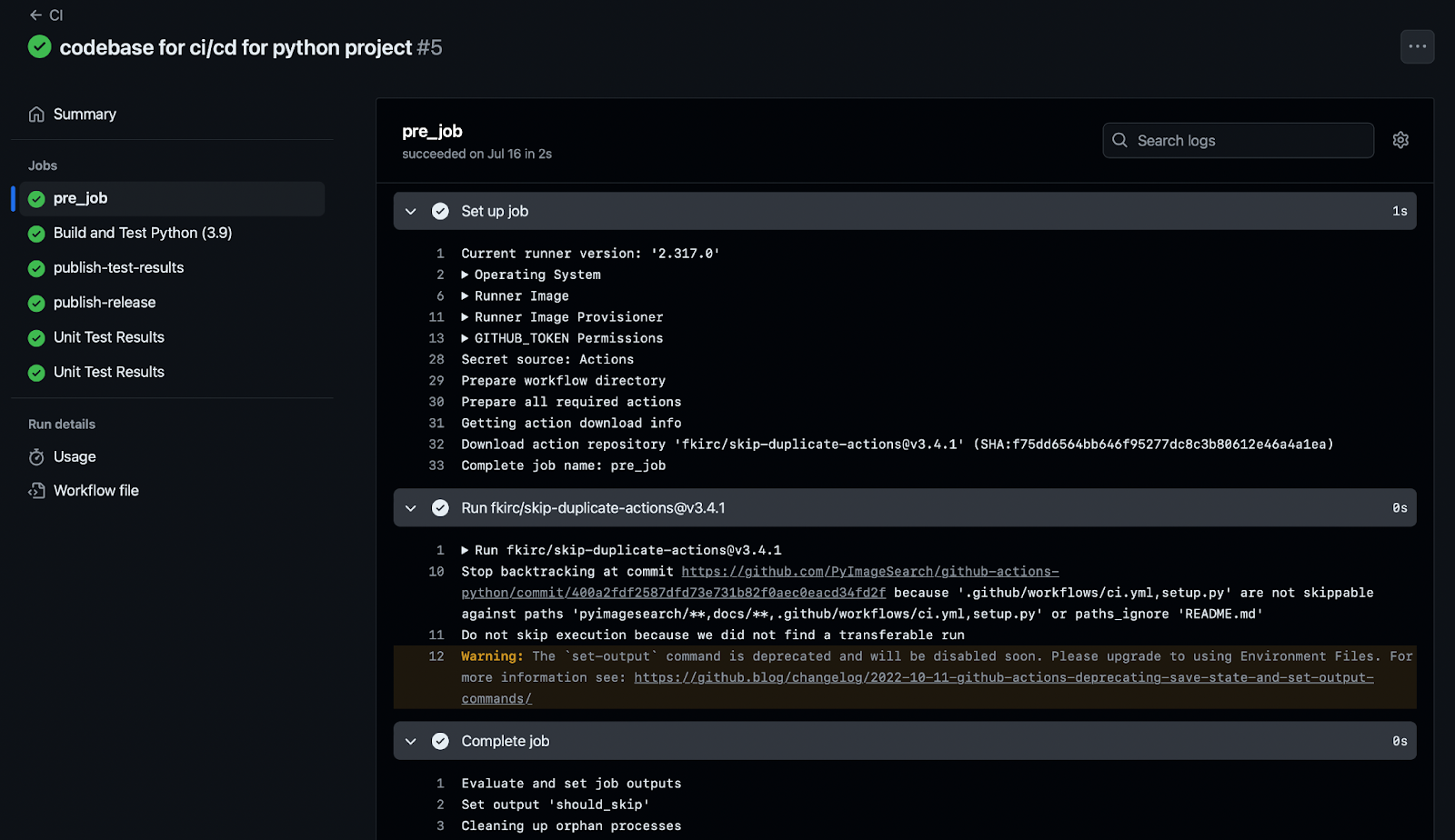
The pre_job is a preliminary job that checks whether the CI pipeline should be skipped based on the nature of the changes. For example, if the changes are only to documentation or non-essential files, it can skip running the entire CI workflow to save time and resources.
Environment: runs-on: ubuntu-latest — This specifies that the job will run in the latest available version of Ubuntu. Using a standardized environment ensures consistency and reduces issues that could arise from different setups.
The outputs section defines data that is produced by one job and can be used as input for another job. In our pre_job, the output is a flag called should_skip.
Output should_skip: This output is crucial because it informs subsequent jobs whether or not they should execute. If should_skip is set to true, it means that the CI pipeline should skip further actions.
The steps section within a job defines the individual tasks that the job will execute. Each step can run a script, an action, or a series of commands. The steps within this job include:
skip_check: This step uses thefkirc/skip-duplicate-actions@v3.4.1action to determine if the current changes warrant a full CI run. For instance, if only the documentation files were changed, the action could skip the rest of the CI process.
What Is the Importance of pre_job?
- Optimization: By using a pre-job like this, the CI pipeline is optimized to avoid redundant runs, saving time and computational resources. It ensures that only meaningful changes trigger the complete CI process.
- Job Memory: This job remembers previous successful runs and can skip re-running parts of the pipeline if nothing significant has changed since the last successful run.
Output Example
In the provided screenshot, you can see how the pre_job appears when executed:
- Set up job: The environment is configured, and the runner is prepared.
- Run skip-duplicate action: The
skip_checkaction evaluates whether the pipeline should proceed. - Complete job: The job finishes by setting the output, which subsequent jobs will check.
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: June 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this comprehensive blog post, we explore the essential steps to set up a GitHub Actions CI pipeline for a Python FastAPI application. The post begins with an overview of our previous discussions on CI/CD pipelines, emphasizing the importance of continuous integration in modern software development. It highlights how CI practices help detect bugs early, enhance development workflows, and maintain code quality.
We also touch on the preliminary work of deploying a Vision Transformer model using FastAPI, which illustrated the complexities of FastAPI applications and underscored the necessity for an automated CI pipeline.
This tutorial specifically focuses on leveraging Taskfile for automating routine tasks and efficiently managing dependencies, along with the strategic use of pre-jobs in GitHub Actions to optimize CI workflow. Through detailed guidance, readers will learn how to configure their development environment, understand their project directory structure, and break down the tasks in the Taskfile.
By the end of this guide, readers will gain practical insights into setting up and refining a CI pipeline, ultimately improving workflow productivity and ensuring the reliability and quality of their FastAPI applications.
Citation Information
Martinez, H. “Setting Up GitHub Actions CI for FastAPI: Intro to Taskfile and Pre-Jobs,” PyImageSearch, P. Chugh, S. Huot, K. Kidriavsteva, R. Raha, and A. Sharma, eds., 2024, https://pyimg.co/bh0gz
@incollection{Martinez_2024_Setting-Up-GitHub-Actions-CI-FastAPI-Intro-Taskfile-PreJobs,
author = {Hector Martinez},
title = {Setting Up GitHub Actions CI for FastAPI: Intro to Taskfile and Pre-Jobs},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha and Aditya Sharma},
year = {2024},
url = {https://pyimg.co/bh0gz},
}
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.