Table of Contents
- Understanding Tasks in Diffusers: Part 2
- Configuring Your Development Environment
- What Is Inpainting?
- Setup and Imports
- Loading the Image and Masks
- An Inpainting Demo
- Blurring the Masked Area
- SDXL for Inpainting
- Preserving the Unmasked Area
- Pipeline Parameters
- Chained Inpainting (Text2Img to Inpainting)
- Chained Inpainting (Inpainting to Img2Img)
- Controlling Image Generation
- Summary
Inpaint Images: AI Photo Restoration
In this tutorial, you will learn how to do image inpainting with Diffusers.

This lesson is the 2nd in a 3-part series on Understanding Tasks in Diffusers:
- Understanding Tasks in Diffusers: Part 1
- Understanding Tasks in Diffusers: Part 2 (this tutorial)
- Understanding Tasks in Diffusers: Part 3
To learn how to perform image inpainting and control image generation, just keep reading.
Understanding Tasks in Diffusers Part 2
Welcome to Part 2 of the Understanding Tasks in Diffusers tutorial series.
This tutorial is inspired by the beautiful documentation at Hugging Face Diffusers.
Configuring Your Development Environment
To follow this guide, you need to have the diffusers and accelerate libraries installed on your system.
Luckily, diffusers is pip-installable:
$ pip install diffusers $ pip install accelerate
What Is Inpainting?
Image inpainting refers to the process of repairing the missing or damaged parts of images, as shown in Figure 1.

Traditionally, it has been widely used to restore aged or deteriorated photographs, effectively removing imperfections (e.g., cracks, scratches, dust spots, and red eyes), thus preserving the integrity of visual memories.
Diffusion models allow us to take a more creative approach. These models enable users to selectively mask regions within an image and then guide the restoration or alteration process through textual prompts. This technique represents a specialized application of the img2img (image-to-image) transformation, where only a designated portion of the image is modified in accordance with the directions provided by the prompt.
So effectively, image inpainting through diffusion:
- Fills specific areas in images
- Repairs defects and artifacts
- Replaces areas with entirely new content
- Uses a mask (white=fill, black=keep)
- Guided by a text prompt
Let us begin by importing the necessary libraries required for diffusers.
Setup and Imports
import torch
from diffusers import (
AutoPipelineForText2Image,
AutoPipelineForInpainting,
ControlNetModel,
StableDiffusionControlNetInpaintPipeline,
AutoPipelineForImage2Image,
)
from diffusers.utils import load_image, make_image_grid
Loading the Image and Masks
Next, we want to:
- Define the device type (please note that a gpu, preferably A100, is needed for running most of the examples).
- Define a generator (optional). This is to make the images reproducible.
- Load the image and masks. You can create your own masks from images from Hugging Face Spaces.
We display the image and the mask in Figure 2.
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
GENERATOR = torch.Generator(DEVICE).manual_seed(31)
IMAGE_SIZE = (1024, 1024)
initial_image = load_image("https://i.imgur.com/UjAIycp.png").resize(IMAGE_SIZE)
initial_mask_image = load_image("https://i.imgur.com/JMHtoZE.png").resize(IMAGE_SIZE)
make_image_grid([initial_image, initial_mask_image], rows=1, cols=2)

An Inpainting Demo
Now, let’s look at a demo of inpainting with the above mask and image.
The model we are using here is: runwayml/stable-diffusion-v1-5.
Stable Diffusion Inpainting, Stable Diffusion XL (SDXL) Inpainting, and Kandinsky 2.2 Inpainting are the most popular models for inpainting.
SDXL is capable of producing higher resolution images, but the init_image for SDXL must be 1024x1024.
What is Stable Diffusion Inpainting?
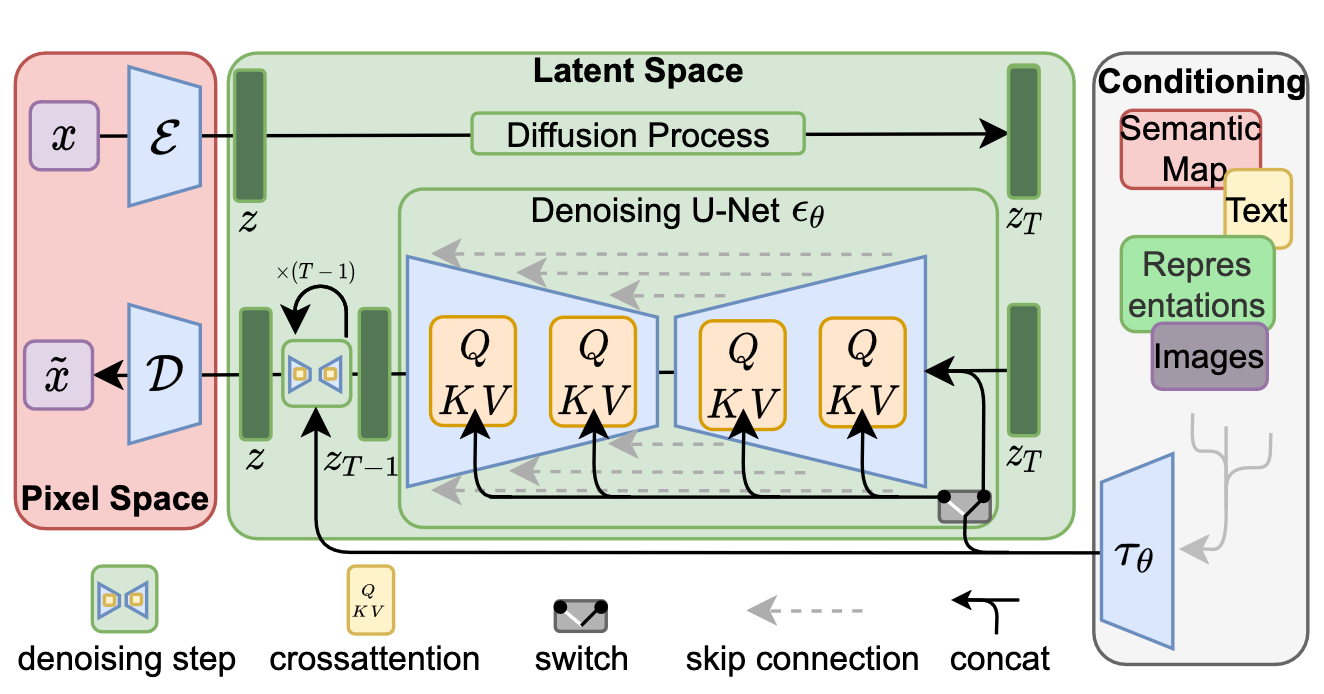
The short answer is that it’s a latent diffusion model fine-tuned on 512x512 images on inpainting. The architecture resembles a standard image-to-image diffusion pipeline, where the denoising is guided by both a text prompt and is limited to a particular region.
Do you want to learn more about Stable Diffusion and the Inpainting Architecture? Please complete the survey here.
We create the pipeline by fetching the required model using AutoPipelineForInpainting and supply it with a prompt, negative_prompt, original image, and mask image.
prompt = "ilustration of a banyan tree with lush green leafs, high resolution, disney, pixar, 8k"
negative_prompt = "bad anatomy, deformed, ugly, disfigured"
model_id = "runwayml/stable-diffusion-v1-5"
pipeline = AutoPipelineForInpainting.from_pretrained(
model_id,
low_cpu_mem_usage=True,
use_safetensors=True,
).to(DEVICE)
output = pipeline(
prompt=prompt,
negative_prompt=negative_prompt,
height=IMAGE_SIZE[0],
width=IMAGE_SIZE[0],
image=initial_image,
mask_image=initial_mask_image,
generator=GENERATOR,
).images[0]
Finally, the rendered image is shown using the make_image_grid functionality in Figure 4.
make_image_grid([initial_image, initial_mask_image, output], rows=1, cols=3)

Blurring the Masked Area
Sometimes, a very strict mask can be constricting to the inpainting model. A little rough/ blurred or dilated mask is often seen to give better outputs.
This functionality is provided by the VaeImageProcessor.blur method.
A higher blur_factor makes the edges more blurry, while a lower value retains the sharper edges.
Let’s see how we can use this:
blurred_mask = pipeline.mask_processor.blur(
initial_mask_image,
blur_factor=50,
)
Let us visualize the blurred mask. The blurred mask is shown in Figure 5.
make_image_grid([blurred_mask], rows=1, cols=1)

output_blurred = pipeline(
prompt=prompt,
negative_prompt=negative_prompt,
height=IMAGE_SIZE[0],
width=IMAGE_SIZE[0],
image=initial_image,
mask_image=blurred_mask,
generator=GENERATOR
).images[0]
And finally, look at the generated image (shown in Figure 6) with the blurred mask.
make_image_grid([initial_image, initial_mask_image, output, output_blurred], rows=2, cols=2)

SDXL for Inpainting
Let us now focus on how to use Stable Diffusion XL for inpainting. The model name is: diffusers/stable-diffusion-xl-1.0-inpainting-0.1.
What is SDXL Image Inpainting?
SDXL is a larger and more powerful version of Stable Diffusion v1.5. It generally follows a two-stage process, where the base model first produces an image, and then the refiner model polishes it. However, each model can be used separately as well. We can see sdxl inpainting in work in Figure 7.

Let us see how we can use it. We load the pipeline using AutoPipelineForInpainting and pass in the prompt, negative_prompt, and the image dimensions and the original and mask images.
In Figure 8, we see the final result.
prompt = "ilustration of a banyan tree with lush green leafs, high resolution, disney, pixar, 8k"
negative_prompt = "bad anatomy, deformed, ugly, disfigured"
model_id = "diffusers/stable-diffusion-xl-1.0-inpainting-0.1"
pipeline = AutoPipelineForInpainting.from_pretrained(
model_id,
low_cpu_mem_usage=True,
use_safetensors=True,
).to(DEVICE)
output = pipeline(
prompt=prompt,
negative_prompt=negative_prompt,
height=IMAGE_SIZE[0],
width=IMAGE_SIZE[0],
image=initial_image,
mask_image=initial_mask_image,
generator=GENERATOR,
).images[0]
make_image_grid([initial_image, initial_mask_image, output], rows=1, cols=3)

Preserving the Unmasked Area
A frequent problem that arises is how to preserve the unmasked area while doing generations,
Again, we can make use of the VaeImageProcessor or the VaeImageProcessor.apply_overlay method specifically.
This forces the unmasked area of the original image to remain the same, even though this can create some artifacts between the masked and unmasked area in the final generation.
Let us see how we can achieve this using a previously used model: runwayml/stable-diffusion-inpainting.
prompt = "ilustration of a banyan tree with lush green leafs, high resolution, disney, pixar, 8k"
negative_prompt = "bad anatomy, deformed, ugly, disfigured"
model_id = "runwayml/stable-diffusion-inpainting"
pipeline = AutoPipelineForInpainting.from_pretrained(
model_id,
low_cpu_mem_usage=True,
).to(DEVICE)
Here, we first create the inpainted_image exactly as we had done before.
inpainted_image = pipeline(
prompt=prompt,
negative_prompt=negative_prompt,
height=IMAGE_SIZE[0],
width=IMAGE_SIZE[0],
image=initial_image,
mask_image=initial_mask_image,
generator=GENERATOR,
).images[0]
Now, we apply the apply_overlay, which allows us to paste the unmasked region of the original image back on the generated inpainted_image.
unmasked_unchanged_image = pipeline.image_processor.apply_overlay(
initial_mask_image,
initial_image,
inpainted_image,
)
Finally, we visualize the images using the make_image_grid utility in Figure 9.
make_image_grid([initial_image, initial_mask_image, inpainted_image, unmasked_unchanged_image], rows=2, cols=2)

Pipeline Parameters
As with the previous tutorial, it is important to understand the various pipeline parameters to:
strength: controls noise added to the base image.- High strength: More noise, longer processing. Higher quality, more different from base.
- Low strength: Less noise, faster processing. Lower quality, closer to base.
guidance_scale: describes how aligned the text prompt and generated image are.- High: Stricter interpretation of prompt (less creativity).
- Low: More varied output (more creative).
- High strength & High
guidance_scale: Maximum creative freedom within prompt restrictions.
negative_prompt: It has the opposite role of a prompt.- Guides the model away from unwanted visuals.
- It can be used effectively to improve image quality without much effort.
padding_mask_crop: This crops the masked area with some user-specified padding, and it’ll also crop the same area from the original image.- Crops masked area + padding from image and mask.
- Upscales cropped image and mask.
- Overlays upscaled on the original image.
- Boosts quality without complex pipelines.
Let us see how we can effectively play with these parameters using a previously defined model: runwayml/stable-diffusion-inpainting.
Parameters to tune:
- Strength: defines how much the inpainted region should resemble the original region. 1 = no trace left of original, 0 = original region reconstructed.
- Guidance Scale: how well aligned the generation and the prompt are. Higher = strictly aligned, lower = loosely aligned.
- Negative Prompt: what visuals and imageries to stay away from when generating the image.
- Padding Mask Crop: crop parts of the mask and the original image for a more informed image generation.
model_id = "runwayml/stable-diffusion-inpainting"
pipeline = AutoPipelineForInpainting.from_pretrained(
model_id,
low_cpu_mem_usage=True,
).to(DEVICE)
Feel free to change these parameters and watch the generated image change.
output = pipeline(
prompt=prompt,
negative_prompt=negative_prompt,
image=initial_image,
mask_image=initial_mask_image,
height=IMAGE_SIZE[0],
width=IMAGE_SIZE[1],
strength=1,
guidance_scale=10.5,
padding_mask_crop=32
).images[0]
Visualize the final image using the make_image_grid utility in Figure 10.
make_image_grid([initial_image, initial_mask_image, output], rows=1, cols=3)

Chained Inpainting (Text2Img to Inpainting)
AutoPipelineForInpainting can be chained with other Diffusers pipelines.
This can improve the quality of generations and also remove any unnecessary artifacts that may crop up during image inpainting or other generations.
Chaining a text-to-image and inpainting pipeline allows us to inpaint the generated image.
prompt = "ilustration of a banyan tree with lush green leafs, high resolution, disney, pixar, 8k"
negative_prompt = "bad anatomy, deformed, ugly, disfigured"
model_id = "runwayml/stable-diffusion-v1-5"
pipeline = AutoPipelineForText2Image.from_pretrained(
model_id,
low_cpu_mem_usage=True,
use_safetensors=True,
).to(DEVICE)
First, we create the text2image pipeline for generating images based on a prompt.
text2image_output = pipeline(
prompt,
height=IMAGE_SIZE[0],
width=IMAGE_SIZE[1],
generator=GENERATOR,
).images[0]
We can visualize the image using the make_image_grid utility, as shown in Figure 11.
make_image_grid([text2image_output], rows=1, cols=1)

Next, we load an arbitrary_mask, which has an arbitrary shape to be inpainted. We visualize the arbitrarily shaped mask in Figure 12.
arbitrary_mask = load_image("https://i.imgur.com/X4yzBR7.png").resize(IMAGE_SIZE)
make_image_grid([arbitrary_mask], rows=1, cols=1)

model_id = "kandinsky-community/kandinsky-2-2-decoder-inpaint"
pipeline = AutoPipelineForInpainting.from_pretrained(
model_id,
low_cpu_mem_usage=True,
).to(DEVICE)
We supply this pipeline with a new prompt and use it to create the inpainted generation. Let’s visualize the result in Figure 13.
arbitrary_mask_text2image_output = pipeline(
prompt="a blossom of cherry flowers, beautiful, cute, disney, pixar, 8k",
image=text2image_output,
mask_image=arbitrary_mask,
height=IMAGE_SIZE[0],
width=IMAGE_SIZE[1],
generator=GENERATOR,
).images[0]
make_image_grid([text2image_output, arbitrary_mask, arbitrary_mask_text2image_output], rows=1, cols=3)

Chained Inpainting (Inpainting to Img2Img)
We can also chain the inpainting pipeline with another image-to-image pipeline to refine its quality.
The model we use for the initial inpainting is: runwayml/stable-diffusion-inpainting, and the model used for image-to-image is: stabilityai/stable-diffusion-xl-refiner-1.0. Let’s view the end product in Figure 14.
prompt = "ilustration of a banyan tree with lush green leafs, high resolution, disney, pixar, 8k"
negative_prompt = "bad anatomy, deformed, ugly, disfigured"
model_id = "runwayml/stable-diffusion-inpainting"
pipeline = AutoPipelineForInpainting.from_pretrained(
model_id,
low_cpu_mem_usage=True,
).to(DEVICE)
image_inpainting = pipeline(
prompt=prompt,
negative_prompt=negative_prompt,
image=initial_image,
mask_image=initial_mask_image,
height=IMAGE_SIZE[0],
width=IMAGE_SIZE[1],
generator=GENERATOR,
).images[0]
make_image_grid([image_inpainting], rows=1, cols=1)

model_id = "stabilityai/stable-diffusion-xl-refiner-1.0"
pipeline = AutoPipelineForInpainting.from_pretrained(
model_id,
low_cpu_mem_usage=True,
).to(DEVICE)
refined_inpaint_image = pipeline(
prompt=prompt,
image=image_inpainting,
mask_image=initial_mask_image,
output_type="latent",
height=IMAGE_SIZE[0],
width=IMAGE_SIZE[1],
generator=GENERATOR,
).images[0]
pipeline = AutoPipelineForImage2Image.from_pipe(pipeline).to(DEVICE)
image = pipeline(
prompt=prompt,
image=refined_inpaint_image,
height=IMAGE_SIZE[0],
width=IMAGE_SIZE[1],
generator=GENERATOR,
).images[0]
make_image_grid([initial_image, initial_mask_image, image_inpainting, image], rows=2, cols=2)
Here, we use the AutoPipelineForImage2Image to create another image from the inpainted image shown in Figure 15.

Controlling Image Generation
Denoising a noisy image to get a generated image is a stochastic process. We can play around with the pipeline parameters, but only to a certain extent. Fortunately, there are more definitive ways to control image generation.
Let us learn how to do this with the following models:
"lllyasviel/control_v11p_sd15_inpaint"runwayml/stable-diffusion-inpainting
Using a Control Image
ControlNet models can be used with other models from the Diffusers library.
- It works by accepting a conditioning image input.
- This guides the diffusion model to preserve the features in it.
Let’s see how we can achieve this.
prompt = "ilustration of a banyan tree with lush green leafs, high resolution, disney, pixar, 8k" negative_prompt = "bad anatomy, deformed, ugly, disfigured"
First, we create two pipelines:
- A ControlNet pipeline
- A StableDiffusion pipeline
controlnet_model_id = "lllyasviel/control_v11p_sd15_inpaint"
sd_model_id = "runwayml/stable-diffusion-inpainting"
# load ControlNet
controlnet = ControlNetModel.from_pretrained(controlnet_model_id,
torch_dtype=torch.float16,
variant="fp16").to(device)
# pass ControlNet to the pipeline
pipeline = StableDiffusionControlNetInpaintPipeline.from_pretrained(
sd_model_id,
controlnet=controlnet,
torch_dtype=torch.float16,
variant="fp16"
).to(device)
Next, we create a function named make_inpaint_condition that prepares a “control image” for inpainting based on an input image and its corresponding mask image. Its purpose is:
- Marking the masked regions in the original image for the inpainting algorithm to target.
- Ensuring the image and mask have matching dimensions for proper processing.
- Converting the data to a format compatible with commonly used inpainting libraries.
# prepare control image
def make_inpaint_condition(init_image, mask_image):
init_image = np.array(init_image.convert("RGB")).astype(np.float32) / 255.0
mask_image = np.array(mask_image.convert("L")).astype(np.float32) / 255.0
assert init_image.shape[0:1] == mask_image.shape[0:1], "image and image_mask must have the same image size"
init_image[mask_image > 0.5] = -1.0 # set as masked pixel
init_image = np.expand_dims(init_image, 0).transpose(0, 3, 1, 2)
init_image = torch.from_numpy(init_image)
return init_image
control_image = make_inpaint_condition(init_image, mask_image)
We can visualize the control image using the make_image_grid functionality, as shown in Figure 16.
make_image_grid([control_image], rows=1, cols=1)

We can chain this with an image-to-image pipeline to get a more refined image.
Now, we generate the final image using the initial image, mask image, and control image, as shown in Figure 17.
image = pipeline(
prompt=prompt,
negative_prompt=negative_prompt,
image=initial_image,
mask_image=initial_mask_image,
control_image=control_image,
height=IMAGE_SIZE[0],
width=IMAGE_SIZE[1],
generator=GENERATOR,
).images[0]
make_image_grid([initial_image, initial_mask_image, Image.fromarray(np.uint8(control_image[0][0])).convert('RGB'), image], rows=2, cols=2)

Using Another Refiner Model
We can go a step further by using the stabilityai/stable-diffusion-xl-refiner-1.0 model.
This will allow us to generate the image in the custom style we want. The final output is shown in Figure 18.
prompt = "zack snyder style"
negative_prompt = "bad architecture, deformed, disfigured, poor details"
model_id = "stabilityai/stable-diffusion-xl-refiner-1.0"
pipeline = AutoPipelineForImage2Image.from_pretrained(
model_id,
low_cpu_mem_usage=True,
).to(DEVICE)
refined_image = pipeline(
prompt,
negative_prompt=negative_prompt,
image=image,
height=IMAGE_SIZE[0],
width=IMAGE_SIZE[1],
generator=GENERATOR,
).images[0]
make_image_grid([initial_image, initial_mask_image, image, refined_image], rows=2, cols=2)

Summary
This tutorial delves into image inpainting with the Diffusers library, showcasing its versatility for both basic edits and elaborate artistic endeavors.
Here are the following things we learned:
- Inpainting Demo
- Simple example
- Blurring the mask area
- SDXL for Image Inpainting
- Preserving the Unmasked area
- Chained Image Inpainting
- Text2Img to Image Inpainting
- Inpainting to Img2Img
- Controlling Image Generation
- Using a control image
- Using a refiner model
Image inpainting can be really simple, and it can also be really complex, depending upon the size of the masked region, the specific shape of the region, and the prompt from the user.
By leveraging these methods, you’ll gain greater control over the image generation process, minimizing the randomness introduced by denoising and getting closer to your ideal visual representation.
A number of web applications have started internet businesses founded on the principle of basic image inpainting.
It is important to see how inpainting works and how to easily get your own results using the Diffusers library from Hugging Face.
In the next part of the tutorial, we will discuss some advanced workflows like Depth2Img and more.
Citation Information
A. R. Gosthipaty and R. Raha. “Understanding Tasks in Diffusers: Part 2,” PyImageSearch, P. Chugh, S. Huot, and K. Kidriavsteva, eds., 2024, https://pyimg.co/ga0jk
@incollection{ARG-RR_2024_Understanding-Tasks-in-Diffusers-Part-2,
author = {Aritra Roy Gosthipaty and Ritwik Raha},
title = {Understanding Tasks in Diffusers: Part 2},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Kseniia Kidriavsteva},
year = {2024},
url = {https://pyimg.co/ga0jk},
}

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.


Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.