
Between myself and my father, Jemma, the super-sweet, hyper-active, extra-loving family beagle may be the most photographed dog of all time. Since we got her as a 8-week old puppy, to now, just under three years later, we have accumulated over 6,000+ photos of the dog.
Excessive?
Perhaps. But I love dogs. A lot. Especially beagles. So it should come as no surprise that as a dog owner, I spend a lot of time playing tug-of-war with Jemma’s favorite toys, rolling around on the kitchen floor with her as we roughhouse, and yes, snapping tons of photos of her with my iPhone.
Over this past weekend I sat down and tried to organize the massive amount of photos in iPhoto. Not only was it a huge undertaking, I started to notice a pattern fairly quickly — there were lots of photos with excessive amounts of blurring.
Whether due to sub-par photography skills, trying to keep up with super-active Jemma as she ran around the room, or her spazzing out right as I was about to take the perfect shot, many photos contained a decent amount of blurring.
Now, for the average person I suppose they would have just deleted these blurry photos (or at least moved them to a separate folder) — but as a computer vision scientist, that wasn’t going to happen.
Instead, I opened up an editor and coded up a quick Python script to perform blur detection with OpenCV.
In the rest of this blog post, I’ll show you how to compute the amount of blur in an image using OpenCV, Python, and the Laplacian operator. By the end of this post, you’ll be able to apply the variance of the Laplacian method to your own photos to detect the amount of blurring.
Variance of the Laplacian

My first stop when figuring out how to detect the amount of blur in an image was to read through the excellent survey work, Analysis of focus measure operators for shape-from-focus [2013 Pertuz et al]. Inside their paper, Pertuz et al. reviews nearly 36 different methods to estimate the focus measure of an image.
If you have any background in signal processing, the first method to consider would be computing the Fast Fourier Transform of the image and then examining the distribution of low and high frequencies — if there are a low amount of high frequencies, then the image can be considered blurry. However, defining what is a low number of high frequencies and what is a high number of high frequencies can be quite problematic, often leading to sub-par results.
Instead, wouldn’t it be nice if we could just compute a single floating point value to represent how blurry a given image is?
Pertuz et al. reviews many methods to compute this “blurryness metric”, some of them simple and straightforward using just basic grayscale pixel intensity statistics, others more advanced and feature-based, evaluating the Local Binary Patterns of an image.
After a quick scan of the paper, I came to the implementation that I was looking for: variation of the Laplacian by Pech-Pacheco et al. in their 2000 ICPR paper, Diatom autofocusing in brightfield microscopy: a comparative study.
The method is simple. Straightforward. Has sound reasoning. And can be implemented in only a single line of code:
cv2.Laplacian(image, cv2.CV_64F).var()
You simply take a single channel of an image (presumably grayscale) and convolve it with the following 3 x 3 kernel:
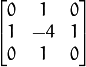
And then take the variance (i.e. standard deviation squared) of the response.
If the variance falls below a pre-defined threshold, then the image is considered blurry; otherwise, the image is not blurry.
The reason this method works is due to the definition of the Laplacian operator itself, which is used to measure the 2nd derivative of an image. The Laplacian highlights regions of an image containing rapid intensity changes, much like the Sobel and Scharr operators. And, just like these operators, the Laplacian is often used for edge detection. The assumption here is that if an image contains high variance then there is a wide spread of responses, both edge-like and non-edge like, representative of a normal, in-focus image. But if there is very low variance, then there is a tiny spread of responses, indicating there are very little edges in the image. As we know, the more an image is blurred, the less edges there are.
Obviously the trick here is setting the correct threshold which can be quite domain dependent. Too low of a threshold and you’ll incorrectly mark images as blurry when they are not. Too high of a threshold then images that are actually blurry will not be marked as blurry. This method tends to work best in environments where you can compute an acceptable focus measure range and then detect outliers.
Detecting the amount of blur in an image
So now that we’ve reviewed the the method we are going to use to compute a single metric to represent how “blurry” a given image is, let’s take a look at our dataset of the following 12 images:

As you can see, some images are blurry, some images are not. Our goal here is to correctly mark each image as blurry or non-blurry.
With that said, open up a new file, name it detect_blur.py , and let’s get coding:
# import the necessary packages
from imutils import paths
import argparse
import cv2
def variance_of_laplacian(image):
# compute the Laplacian of the image and then return the focus
# measure, which is simply the variance of the Laplacian
return cv2.Laplacian(image, cv2.CV_64F).var()
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--images", required=True,
help="path to input directory of images")
ap.add_argument("-t", "--threshold", type=float, default=100.0,
help="focus measures that fall below this value will be considered 'blurry'")
args = vars(ap.parse_args())
We start off by importing our necessary packages on Lines 2-4. If you don’t already have my imutils package on your machine, you’ll want to install it now:
$ pip install imutils
From there, we’ll define our variance_of_laplacian function on Line 6. This method will take only a single argument the image (presumed to be a single channel, such as a grayscale image) that we want to compute the focus measure for. From there, Line 9 simply convolves the image with the 3 x 3 Laplacian operator and returns the variance.
Lines 12-17 handle parsing our command line arguments. The first switch we’ll need is --images , the path to the directory containing our dataset of images we want to test for blurriness.
We’ll also define an optional argument --thresh , which is the threshold we’ll use for the blurry test. If the focus measure for a given image falls below this threshold, we’ll mark the image as blurry. It’s important to note that you’ll likely have to tune this value for your own dataset of images. A value of 100 seemed to work well for my dataset, but this value is quite subjective to the contents of the image(s), so you’ll need to play with this value yourself to obtain optimal results.
Believe it or not, the hard part is done! We just need to write a bit of code to load the image from disk, compute the variance of the Laplacian, and then mark the image as blurry or non-blurry:
# loop over the input images
for imagePath in paths.list_images(args["images"]):
# load the image, convert it to grayscale, and compute the
# focus measure of the image using the Variance of Laplacian
# method
image = cv2.imread(imagePath)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
fm = variance_of_laplacian(gray)
text = "Not Blurry"
# if the focus measure is less than the supplied threshold,
# then the image should be considered "blurry"
if fm < args["threshold"]:
text = "Blurry"
# show the image
cv2.putText(image, "{}: {:.2f}".format(text, fm), (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 0, 255), 3)
cv2.imshow("Image", image)
key = cv2.waitKey(0)
We start looping over our directory of images on Line 20. For each of these images we’ll load it from disk, convert it to grayscale, and then apply blur detection using OpenCV (Lines 24-27).
In the case that the focus measure exceeds the threshold supplied a command line argument, we’ll mark the image as “blurry”.
Finally, Lines 35-38 write the text and computed focus measure to the image and display the result to our screen.
Applying blur detection with OpenCV
Now that we have the detect_blur.py script coded up, let’s give it a shot. Open up a shell and issue the following command:
$ python detect_blur.py --images images

The focus measure of this image is 83.17, falling below our threshold of 100; thus, we correctly mark this image as blurry.

This image has a focus measure of 64.25, also causing us to mark it as “blurry”.

Figure 6 has a very high focus measure score at 1004.14 — orders of magnitude higher than the previous two figures. This image is clearly non-blurry and in-focus.

The only amount of blur in this image comes from Jemma wagging her tail.

The reported focus measure is lower than Figure 7, but we are still able to correctly classify the image as “non-blurry”.

However, we can clearly see the above image is blurred.

The large focus measure score indicates that the image is non-blurry.

However, this image contains dramatic amounts of blur.




What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: March 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this blog post we learned how to perform blur detection using OpenCV and Python.
We implemented the variance of Laplacian method to give us a single floating point value to represent the “blurryness” of an image. This method is fast, simple, and easy to apply — we simply convolve our input image with the Laplacian operator and compute the variance. If the variance falls below a predefined threshold, we mark the image as “blurry”.
It’s important to note that threshold is a critical parameter to tune correctly and you’ll often need to tune it on a per-dataset basis. Too small of a value, and you’ll accidentally mark images as blurry when they are not. With too large of a threshold, you’ll mark images as non-blurry when in fact they are.
Be sure to download the code using the form at the bottom of this post and give it a try!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

