Table of Contents
- Getting Started with Diffusers for Text-to-Image
- Introduction
- A Brief Primer on Diffusion
- Configuring Your Development Environment
- Need Help Configuring Your Development Environment?
- Setup and Imports
- Diffusers
- But What Is
AutoPipeline? - What Are Some Other Pipelines and Models?
- Diving Deep into a Pipeline
- Summary
Getting Started with Diffusers for Text-to-Image
In this tutorial, you will learn to generate images from text descriptions using the Diffusers library from Hugging Face.
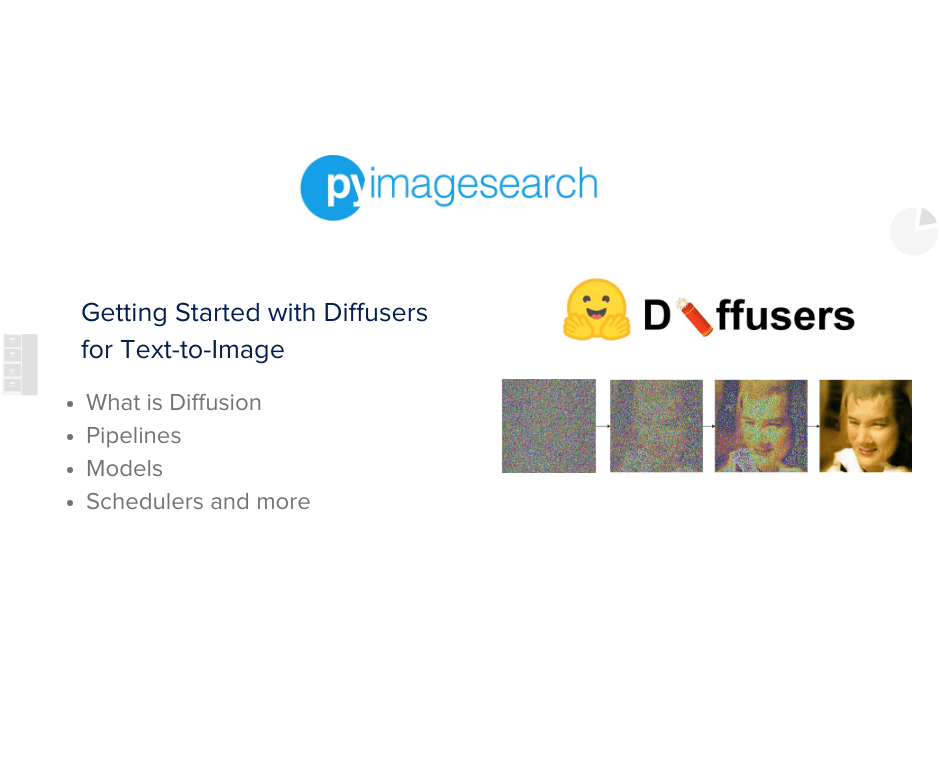
To learn how to get started with using diffusers, just keep reading.
Introduction
In this tutorial, we will use the Diffusers library from Hugging Face. Most of the tutorial is inspired by the awesome documentation and helpful resources from the Diffusers team.
Our primary objective in this tutorial will be to:
- Gather a basic intuition of Diffusion
- Use the Hugging Face Diffusers library to generate an image
- Learn about the parameters inside the
AutoPipelineForText2Image - Learn about the model and scheduler from the DDPM (Denoising Diffusion Probabilistic Models) pipeline
A Brief Primer on Diffusion
Diffusion Models are generative models, meaning that they are used to generate data similar to the data on which they are trained. Fundamentally, Diffusion Models work by destroying training data through the successive addition of Gaussian noise and then learning to recover the data by reversing this noising process. After training, we can use the Diffusion Model to generate data by simply passing randomly sampled noise through the learned denoising process.
➤ Diffusion probabilistic models are parameterized Markov chains trained to gradually denoise data. We estimate the parameters of the generative process (Ho, Jain, and Abbeel, “Denoising Diffusion Probabilistic Modelsm” 2020).
The underlying model, often a neural network, is trained to predict a way to slightly denoise the image in each step. After a certain number of steps, a sample is obtained, as shown in Figure 1.

The Diffusers library, developed by Hugging Face, is an accessible tool designed for a broad spectrum of deep learning practitioners. It emphasizes three core principles: ease of use, intuitive understanding, and simplicity in contribution.
In essence, the diffusion process initiates with random noise, matching the size of the intended output, which is repeatedly processed through the model. This procedure concludes after a predetermined number of steps, culminating in an output image that mirrors a sample from the model’s training data distribution. For example, if the model is trained on butterfly images, the resulting image will closely resemble a butterfly.
The training phase involves exposing the model to numerous samples from a specific distribution (e.g., butterfly images). Post-training, this model is adept at transforming random noise into images that bear a striking resemblance to butterflies.
The workflow of a diffusion model is shown in Figure 2:

Do you want to learn about DIFFUSION MODELS in full detail?
Please let us know your choice here.
Configuring Your Development Environment
To follow this guide, you need to have the diffusers and accelerate libraries installed on your system.
Luckily, diffusers is pip-installable:
$ pip install diffusers $ pip install accelerate
Need Help Configuring Your Development Environment?

All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code immediately on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Setup and Imports
We start by importing the necessary libraries we need for this project.
import tqdm import torch import PIL import PIL.Image import numpy as np import diffusers from PIL import Image from diffusers import UNet2DModel from diffusers import AutoPipelineForText2Image from diffusers import DDPMPipeline from diffusers import DDPMScheduler
Diffusers
In this tutorial, we’ll delve into three pivotal components of the Hugging Face Diffusers library (shown in Figure 3).

- The Role of the Model: Simplifying the complexity, the model in a diffusion process, particularly in a type known as “DDPM,” is typically not tasked with directly forecasting a marginally less noisy image. Instead, its role is to ascertain the “noise residual.” This is essentially the disparity between a less noisy image and its preceding input.
- The Role of the Scheduler: For the denoising process, a specific noise scheduling algorithm is thus necessary and “wraps” the model to define how many diffusion steps are needed for inference, as well as how to compute a less noisy image from the model’s output. Here is where the different schedulers of the
diffuserslibrary come into play. - The Role of the Pipeline: The concept of a pipeline is integral to the
diffuserslibrary. It amalgamates a model with a scheduler, streamlining the process for end-users to execute a complete denoising loop. Our journey will commence with an exploration of pipelines, progressively delving into their mechanics before shifting our focus to the nuances of models and schedulers.
Let us see how to bring this together and generate an image, as shown in Figure 4.
pipeline = AutoPipelineForText2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, variant="fp16"
).to("cuda")
image = pipeline( "impressionist oil painting of pikachu, backlight, centered composition, masterpiece, photorealistic, 8k" ).images[0] image

But What Is AutoPipeline?
The Hugging Face Diffusers library, renowned for its versatility, is capable of accomplishing a multitude of tasks. Remarkably, the same pretrained weights can often be employed for varied tasks like text-to-image, image-to-image, and inpainting. However, for those new to the library or diffusion models, selecting the appropriate pipeline for a specific task might pose a challenge.
The AutoPipeline class is designed to streamline the complexity inherent in the plethora of pipelines within the Hugging Face Diffusers framework. This class embodies a task-first approach, allowing users to concentrate on the task at hand rather than the intricacies of pipeline selection.
The ingenuity of AutoPipeline lies in its ability to automatically discern the most suitable pipeline class for a given task. This feature is particularly beneficial for users, as it simplifies the process of loading a model checkpoint for a specific task without the need to know the exact pipeline class name, thereby making the user experience more intuitive and accessible.
What Are Some Other Pipelines and Models?
The realm of text-to-image generation within the Hugging Face Diffusers library is rich with a variety of models, each unique in its capabilities and outputs. Among the most popular are Stable Diffusion v1.5, Stable Diffusion XL (SDXL), and Kandinsky 2.2. In addition to these, there are specialized models (e.g., ControlNet models or adapters) that can be integrated with text-to-image models to provide more precise control over image generation. While the results from each model vary due to their distinct architectures and training methodologies, their application remains largely consistent across different models.
To truly appreciate the nuances and distinctiveness of these models, let’s experiment. We will use the same prompt across different models and observe the variations in the generated images. This comparison will provide insights into the strengths and characteristics of each model:
- For Stable Diffusion v1.5, we use the model identifier:
runwayml/stable-diffusion-v1-5 - For Stable Diffusion XL, the model identifier is:
stabilityai/stable-diffusion-xl-base-1.0 - And for Kandinsky 2.2, we use:
kandinsky-community/kandinsky-2-2-decoder
We have used the stabilityai/stable-diffusion-xl-base-1.0 model here, but readers are encouraged to experiment with different models with the same prompts to see how the generated images differ. The generated image is shown in Figure 5.
pipeline = AutoPipelineForText2Image.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16"
).to("cuda")
prompt = "Astronaut in a 1700 New York, cold color palette, muted colors, detailed, 8k"
image = pipeline(prompt = prompt,
height=768,
width=512,
).images[0]
image

Under the Hood, AutoPipelineForText2Image
The AutoPipelineForText2Image within the Hugging Face Diffusers library is ingeniously crafted to streamline the text-to-image generation process. Here’s an insight into its functionality:
- Automatic Model Detection: This pipeline is adept at automatically identifying a “stable-diffusion” class. It achieves this by parsing through the
model_index.jsonfile, a key component that guides the pipeline in selecting the appropriate model. - Pipeline Loading: Once the “stable-diffusion” class is identified,
AutoPipelineForText2Imageproceeds to load the correspondingStableDiffusionPipeline. This is directly linked to the class name “stable-diffusion,” ensuring that the most suitable text-to-image pipeline is employed for the task at hand.
Additionally, AutoPipelineForText2Image is designed to be flexible and accommodating to specific user needs. It allows for the integration of various additional arguments that are characteristic of the pipeline class. Some notable examples include:
guidance_scale: A crucial parameter that plays a pivotal role in dictating the degree to which the prompt influences image generation. A lower value on this scale grants more creative freedom to the model, allowing it to generate images that are not strictly confined to the prompt, thus introducing a blend of creativity and abstraction.num_inference_steps: This parameter defines the number of steps the model will take during the inference process.
image = pipeline(prompt,
height=768,
width=512,
num_inference_steps=70,
guidance_scale=10.5,
).images[0]
image
Diving Deep into a Pipeline
Now, in this part of the tutorial, we will learn to use models and schedulers to assemble a diffusion system for inference, starting with a basic pipeline.
The DDPM Pipeline
In this section, we will explore the Denoising Diffusion Probabilistic Models (DDPM) pipeline using the google/ddpm-celebahq-256 model. This model is an implementation of the DDPM algorithm, as detailed in the research paper, Denoising Diffusion Probabilistic Models, and is specifically trained on a dataset comprising images of celebrities.
The DDPMPipeline is a simple starting point for us to understand the various aspects of the pipeline.
ddpm_pipeline = DDPMPipeline.from_pretrained("google/ddpm-celebahq-256")
ddpm_pipeline.to("cuda")
DDPMPipeline {
"_class_name": "DDPMPipeline",
"_diffusers_version": "0.25.0",
"_name_or_path": "google/ddpm-celebahq-256",
"scheduler": [
"diffusers",
"DDPMScheduler"
],
"unet": [
"diffusers",
"UNet2DModel"
]
}
To generate an image, we simply run the pipeline and don’t even need to give it any input. It will generate a random initial noise sample and then iterate the diffusion process.
The pipeline returns as output a dictionary with a generated sample of interest.
images = ddpm_pipeline().images images[0]
Let’s break down the pipeline and take a look at what’s happening under the hood. Here, we are taking a repository from Hugging Face and extracting the scheduler and the model from it. You can take other repositories from Hugging Face to experiment.
repo_id = "google/ddpm-church-256"
repo_id = "google/ddpm-cat-256"
repo_id = "google/ddpm-celebahq-256"
scheduler = DDPMScheduler.from_pretrained(repo_id)
model = UNet2DModel.from_pretrained(repo_id).to("cuda")
Models
Instances of the model class are neural networks that take a noisy sample as well as a timestep as inputs to predict a less noisy output sample. Let’s load a pre-trained model and try to understand the API.
Here, we load a simple unconditional image generation model of type UNet2DModel, which was released with the DDPM Paper, and for instance, take a look at another checkpoint trained on church images: google/ddpm-celebahq-256.
Similar to the pipeline class, we can load the model configuration and weights with one line using the from_pretrained() method that you may be familiar with if you’ve worked with the transformers library.
The from_pretrained() method caches the model weights locally, so if you execute the cell above a second time, it will go much faster. The model is a pure PyTorch torch.nn.Module class, which you can see when printing out model.
model
Schedulers
Schedulers play a critical role in the functioning of diffusion models, acting as the algorithmic backbone that guides both the training and inference processes. Let’s delve into what schedulers are and how they operate within the diffusion framework, particularly focusing on their application during inference.
- Schedulers are essentially algorithms encapsulated within a Python class. They meticulously define the noise schedule — a key component in the diffusion process. This noise schedule is instrumental during the model’s training phase, where it dictates how noise is added to the model.
- Besides defining the noise schedule for training, schedulers are also responsible for the computation process during inference. They take the model output, typically the
noisy_residual, and compute a slightly less noisy sample from it. This step is crucial in progressively refining the image through the diffusion steps.
Distinction from Models
It’s important to distinguish schedulers from models in some key aspects:
- Unlike models, which have trainable weights, schedulers usually do not possess any trainable parameters. Their primary function is to define the algorithmic steps for computing the less noisy sample rather than learning from data.
- Despite not inheriting from
torch.nn.Modulelike typical neural network models, schedulers are still instantiated based on a configuration. This configuration sets the parameters for the algorithm that the scheduler will use during the inference process.
To download a scheduler config from the Hub, you can make use of the from_config() method to load a configuration and instantiate a scheduler.
As is evident, we are using DDPMScheduler, the denoising algorithm proposed in the DDPM Paper.
scheduler.config
Pairing Models with Schedulers
Now, to summarize, models, such as UNet2DModel (PyTorch modules), are parameterized neural networks trained to predict a slightly less noisy image or residual. They are defined by their .config and can be loaded from the Hub as well as saved and loaded locally. The next step is learning how to combine this model with the correct scheduler to be able to generate images.
Creating a Random Noise
torch.manual_seed(666)
noisy_sample = torch.randn(
1, model.config.in_channels, model.config.sample_size, model.config.sample_size
).to("cuda")
noisy_sample.shape
Finding a Residual Noise
with torch.no_grad():
noisy_residual = model(sample=noisy_sample, timestep=2).sample
Using a Scheduler to Subtract Noise
Different schedulers usually define different parameters. To better understand what the parameters are used for exactly, the reader is advised to directly look into the respective scheduler files under src/diffusers/schedulers/, such as the src/diffusers/schedulers/scheduling_ddpm.py file.
All schedulers provide one or multiple step() methods that can be used to compute the slightly less noisy image. The step() method may vary from one scheduler to another, but normally expects at least the model_output, the timestep, and the current noisy_sample.
If you want to understand how exactly the previous noisy sample is computed as defined in the original paper, you can check the code here.
Let us look at the code in action.
less_noisy_sample = scheduler.step(
model_output=noisy_residual, timestep=2, sample=noisy_sample
).prev_sample
less_noisy_sample.shape
The Denoising Loop
We can see that the computed sample has the same shape as the model input, meaning that you are ready to pass it to the model again in the next step. Let’s now bring it all together and actually define the denoising loop. This loop prints out the (less and less) noisy samples along the way for better visualization in the denoising loop.
Utility Function
Let’s define a display function that takes care of post-processing the denoised image, converts it to a PIL.Image, and displays it.
def display_sample(sample, i):
image_processed = sample.cpu().permute(0, 2, 3, 1)
image_processed = (image_processed + 1.0) * 127.5
image_processed = image_processed.numpy().astype(np.uint8)
image_pil = PIL.Image.fromarray(image_processed[0])
display(f"Image at step {i}")
display(image_pil)
Inference from the Denoising Loop
The denoising loop described here is a crucial part of the operation in diffusion models like DDPM (Denoising Diffusion Probabilistic Models). For the DDPM variant, it is actually quite simple.
Let’s break down the process outlined:
1. Predicting the Residual of the Less Noisy Sample
- This step involves the model predicting the difference (residual) between the current noisy sample and a less noisy version of it. The model essentially learns how to reverse the diffusion process step by step.
2. Computing the Less Noisy Sample with the Scheduler
- The scheduler is responsible for managing the timesteps of the denoising process. It determines how the noise level decreases at each step.
- By computing the less noisy sample, the model effectively walks back through the noise-adding process, progressively denoising the image.
3. Displaying Progress Every 100th Step
- This is a practical addition to visualize the denoising process. Since the total number of timesteps is 1000, displaying the image every 100th step allows you to observe the gradual formation of the final image from noise.
- This visualization is akin to watching a structure being constructed gradually, where the structure (like a church) becomes more defined and clear with each step.
The looping over scheduler.timesteps in decreasing order is essential as it simulates the reverse of the diffusion process, starting from a completely noisy state (at the highest timestep) and gradually reducing the noise to reveal the final image. The process is illustrated in Figure 6.
sample = noisy_sample
for i, t in enumerate(tqdm.tqdm(scheduler.timesteps)):
# predict the noise residual
with torch.no_grad():
residual = model(sample, t).sample
# compute the less noisy image
# by removing the predicted noise
# residual at the current timestep
sample = scheduler.step(residual, t, sample).prev_sample
# visualize the image
if (i + 1) % 100 == 0:
display_sample(sample, i + 1)

What's next? We recommend PyImageSearch University.

120+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 120+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 94+ Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
This tutorial provided a starting point for using the Hugging Face Diffusers library for text-to-image generation. We covered the essentials of diffusion models, setting up the environment, and the components of the diffusers library. Additionally, we delved into the various parameters of an Automatic Text-to-Image Pipeline.
We also dissected the DDPM pipeline from the diffusers library and hand-crafted a custom denoising loop to see how all components come together to create an image from a noisy vector conditioned on a text prompt.
Survey Form
Citation Information
A. R. Gosthipaty and R. Raha. “Getting Started with Diffusers for Text-to-Image,” PyImageSearch, P. Chugh, S. Huot, and K. Kidriavsteva, eds., 2024, https://pyimg.co/4ukb0
@incollection{ARG-RR_2024_Diffusers-4-Text-to-Image,
author = {Aritra Roy Gosthipaty and Ritwik Raha},
title = {Getting Started with Diffusers for Text-to-Image},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Kseniia Kidriavsteva},
year = {2024},
url = {https://pyimg.co/4ukb0},
}

Unleash the potential of computer vision with Roboflow - Free!
- Step into the realm of the future by signing up or logging into your Roboflow account. Unlock a wealth of innovative dataset libraries and revolutionize your computer vision operations.
- Jumpstart your journey by choosing from our broad array of datasets, or benefit from PyimageSearch’s comprehensive library, crafted to cater to a wide range of requirements.
- Transfer your data to Roboflow in any of the 40+ compatible formats. Leverage cutting-edge model architectures for training, and deploy seamlessly across diverse platforms, including API, NVIDIA, browser, iOS, and beyond. Integrate our platform effortlessly with your applications or your favorite third-party tools.
- Equip yourself with the ability to train a potent computer vision model in a mere afternoon. With a few images, you can import data from any source via API, annotate images using our superior cloud-hosted tool, kickstart model training with a single click, and deploy the model via a hosted API endpoint. Tailor your process by opting for a code-centric approach, leveraging our intuitive, cloud-based UI, or combining both to fit your unique needs.
- Embark on your journey today with absolutely no credit card required. Step into the future with Roboflow.

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.