
Based on our previous two sections on image classification and types of learning algorithms, you might be starting to feel a bit steamrolled with new terms, considerations, and what looks to be an insurmountable amount of variation in building an image classifier, but the truth is that building an image classifier is fairly straightforward, once you understand the process.

In this section, we’ll review an important shift in mindset you need to take on when working with machine learning. From there I’ll review the four steps of building a deep learning-based image classifier as well as compare and contrast traditional feature-based machine learning versus end-to-end deep learning.
A Shift in Mindset
Before we get into anything complicated, let’s start off with something that we’re all (most likely) familiar with: the Fibonacci sequence.
The Fibonacci sequence is a series of numbers where the next number of the sequence is found by summing the two integers before it. For example, given the sequence 0, 1, 1, the next number is found by adding 1 + 1 = 2. Similarly, given 0, 1, 1, 2, the next integer in the sequence is 1 + 2 = 3.
Following that pattern, the first handful of numbers in the sequence are as follows:
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, ...
Of course, we can also define this pattern in an (extremely unoptimized) Python function using recursion:
>>> def fib(n): ... if n == 0: ... return 0 ... elif n == 1: ... return 1 ... else: ... return fib(n-1) + fib(n-2) ... >>>
Using this code, we can compute the n-th number in the sequence by supplying a value of n to the fib function. For example, let’s compute the 7th number in the Fibonacci sequence:
>>> fib(7) 13
And the 13th number:
>>> fib(13) 233
And finally the 35th number:
>>> fib(35) 9227465
As you can see, the Fibonacci sequence is straightforward and is an example of a family of functions that:
- Accepts an input, returns an output.
- The process is well defined.
- The output is easily verifiable for correctness.
- Lends itself well to code coverage and test suites.
In general, you’ve probably written thousands upon thousands of procedural functions like these in your life. Whether you’re computing a Fibonacci sequence, pulling data from a database, or calculating the mean and standard deviation from a list of numbers, these functions are all well defined and easily verifiable for correctness.
Unfortunately, this is not the case for deep learning and image classification!
Notice the pictures of a cat and a dog in Figure 1. Now, imagine trying to write a procedural function that can not only tell the difference between these two photos, but any photo of a cat and a dog. How would you go about accomplishing this task? Would you check individual pixel values at various (x, y)-coordinates? Write hundreds of if/else statements? And how would you maintain and verify the correctness of such a massive rule-based system? The short answer is: you don’t.

Unlike coding up an algorithm to compute the Fibonacci sequence or sort a list of numbers, it’s not intuitive or obvious how to create an algorithm to tell the difference between pictures of cats and dogs. Therefore, instead of trying to construct a rule-based system to describe what each category “looks like,” we can instead take a data-driven approach by supplying examples of what each category looks like and then teach our algorithm to recognize the difference between the categories using these examples.
We call these examples our training dataset of labeled images, where each data point in our training dataset consists of:
- An image
- The label/category (i.e., dog, cat, panda, etc.) of the image
Again, it’s important that each of these images have labels associated with them because our supervised learning algorithm will need to see these labels to “teach itself” how to recognize each category. Keeping this in mind, let’s go ahead and work through the four steps to constructing a deep learning model.
Step #1: Gather Your Dataset
The first component of building a deep learning network is to gather our initial dataset. We need the images themselves as well as the labels associated with each image. These labels should come from a finite set of categories, such as: categories = dog, cat, panda.
Furthermore, the number of images for each category should be approximately uniform (i.e., the same number of examples per category). If we have twice the number of cat images than dog images, and five times the number of panda images than cat images, then our classifier will become naturally biased to overfitting into these heavily-represented categories.
Class imbalance is a common problem in machine learning and there exist a number of ways to overcome it. We’ll discuss some of these methods later in this book, but keep in mind the best method to avoid learning problems due to class imbalance is to simply avoid class imbalance entirely.
Step #2: Split Your Dataset
Now that we have our initial dataset, we need to split it into two parts:
- A training set
- A testing set
A training set is used by our classifier to “learn” what each category looks like by making predictions on the input data and then correct itself when predictions are wrong. After the classifier has been trained, we can evaluate the performing on a testing set.
It’s extremely important that the training set and testing set are independent of each other and do not overlap! If you use your testing set as part of your training data, then your classifier has an unfair advantage since it has already seen the testing examples before and “learned” from them. Instead, you must keep this testing set entirely separate from your training process and use it only to evaluate your network.
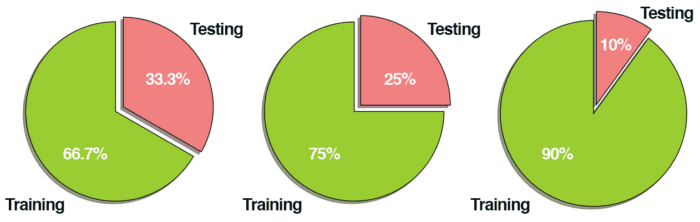
Common split sizes for training and testing sets include 66.6%/33.3%, 75%/25%, and 90%/10%, respectively (Figure 2):
These data splits make sense, but what if you have parameters to tune? Neural networks have a number of knobs and levers (e.g., learning rate, decay, regularization, etc.) that need to be tuned and dialed to obtain optimal performance. We’ll call these types of parameters hyperparameters, and it’s critical that they get set properly.
In practice, we need to test a bunch of these hyperparameters and identify the set of parameters that works the best. You might be tempted to use your testing data to tweak these values, but again, this is a major no-no! The test set is only used in evaluating the performance of your network.
Instead, you should create a third data split called the validation set. This set of the data (normally) comes from the training data and is used as “fake test data” so we can tune our hyperparameters. Only after have we determined the hyperparameter values using the validation set do we move on to collecting final accuracy results in the testing data.
We normally allocate roughly 10-20% of the training data for validation. If splitting your data into chunks sounds complicated, it’s actually not. As we’ll see in our next chapter, it’s quite simple and can be accomplished with only a single line of code thanks to the scikit-learn library.
Step #3: Train Your Network
Given our training set of images, we can now train our network. The goal here is for our network to learn how to recognize each of the categories in our labeled data. When the model makes a mistake, it learns from this mistake and improves itself.
So, how does the actual “learning” work? In general, we apply a form of gradient descent that we detail in a separate post.
Step #4: Evaluate
Last, we need to evaluate our trained network. For each of the images in our testing set, we present them to the network and ask it to predict what it thinks the label of the image is. We then tabulate the predictions of the model for an image in the testing set.
Finally, these model predictions are compared to the ground-truth labels from our testing set. The ground-truth labels represent what the image category actually is. From there, we can compute the number of predictions our classifier got correct and compute aggregate reports such as precision, recall, and f-measure, which are used to quantify the performance of our network as a whole.
Feature-based Learning versus Deep Learning for Image Classification
In the traditional, feature-based approach to image classification, there is actually a step inserted between Step #2 and Step #3 — this step is feature extraction. During this phase, we apply hand-engineered algorithms such as HOG, LBPs, etc., to quantify the contents of an image based on a particular component of the image we want to encode (i.e., shape, color, texture). Given these features, we then proceed to train our classifier and evaluate it.
When building Convolutional Neural Networks, we can actually skip the feature extraction step. The reason for this is because CNNs are end-to-end models. We present the raw input data (pixels) to the network. The network then learns filters inside its hidden layers that can be used to discriminate amongst object classes. The output of the network is then a probability distribution over class labels.
One of the exciting aspects of using CNNs is that we no longer need to fuss over hand-engineered features — we can let our network learn the features instead. However, this tradeoff does come at a cost. Training CNNs can be a non-trivial process, so be prepared to spend considerable time familiarizing yourself with the experience and running many experiments to determine what does and does not work.
What Happens When My Predictions Are Incorrect?
Inevitably, you will train a deep learning network on your training set, evaluate it on your test set (finding that it obtains high accuracy), and then apply it to images that are outside both your training and testing set — only to find that the network performs poorly.
This problem is called generalization, the ability for a network to generalize and correctly predict the class label of an image that does not exist as part of its training or testing data. The ability for a network to generalize is quite literally the most important aspect of deep learning research — if we can train networks that can generalize to outside datasets without retraining or fine-tuning, we’ll make great strides in machine learning, enabling networks to be re-used in a variety of domains. The ability of a network to generalize will be discussed many times in this book, but I wanted to bring up the topic now since you will inevitably run into generalization issues, especially as you learn the ropes of deep learning.
Instead of becoming frustrated with your model not correctly classifying an image, consider the set of factors of variation mentioned above. Does your training dataset accurately reflect examples of these factors of variation? If not, you’ll need to gather more training data (and read the rest of this book to learn other techniques to reduce bias and combat overfitting).
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
We learned what image classification is and why it’s such a challenging task for computers to perform well on (even though humans do it intuitively with seemingly no effort). We then discussed the three main types of machine learning: supervised learning, unsupervised learning, and semi-supervised learning.
Finally, we reviewed the four steps in the deep learning classification pipeline. These steps include gathering your dataset, splitting your data into training, testing, and validation steps, training your network, and finally evaluating your model.
Unlike traditional feature-based approaches which require us to utilize hand-crafted algorithms to extract features from an image, image classification models, such as Convolutional Neural Networks, are end-to-end classifiers which internally learn features that can be used to discriminate amongst image classes.

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.