
Table of Contents
- SmolVLM to SmolVLM2: Compact Models for Multi-Image VQA
- SmolVLM 1: A Compact Yet Capable Vision-Language Model
- What Is SmolVLM?
- Why SmolVLM?
- The Three Variants of SmolVLM
- Architecture Overview
- Vision Encoder: SigLIP Variants
- Pixel Shuffle (Space-to-Depth) for Image Compression
- Visual Token Projection and Embedding
- Image Patching and Splitting Strategy
- SmolLM2 as the Language Model and Context Extension
- Integrating Vision and Language Inputs (Prompt Structure)
- Learned Positional Tokens vs. String Layout Tokens
- Video Handling and Frame Strategy
- Key Differences from Idefics3
- Trade-Offs and Efficiency Benefits
- Memory Efficiency of SmolVLM
- Performance
- Training Strategy
- Vision Training Datasets and Tasks
- Pixel Shuffle and Image Patch Handling
- Prompt Structure, Media Intros/Outros, and Formatting
- Learned Positional Encodings vs. String Tokens
- Video Fine-Tuning: Data Mix and Frame Strategy
- Instruction Tuning: Prompts, Masking, CoT, and SFT Insights
- Benchmarks Used for Evaluation
- Ablation Findings and Design Choices
- Deployment and Real-World Readiness
- SmolVLM2: Taking Visual and Video Understanding to the Next Level
- Key Updates from SmolVLM1 to SmolVLM2
- SmolVLM2-2.2B: The New Star Model
- Going Even Smaller: SmolVLM2-500M and SmolVLM2-256M
- Configuring Your Development Environment
- Setup and Imports
- Load the SmolVLM2 Model and Processor
- Display Image
- Build a Chat Template
- Initialize Processor
- Generate the Output
- Summary
SmolVLM to SmolVLM2: Compact Modes for Multi-Image VQA
In this blog post, we explore the design and capabilities of SmolVLM and its successor, SmolVLM2, two lightweight yet powerful vision-language models developed by Hugging Face. These models are optimized for performance and efficiency, making them suitable for edge devices and real-time applications. We’ll break down the architectural differences, training strategies, benchmark results, and most importantly, demonstrate their ability to perform multi-image understanding using a practical code example.

This lesson is the 1st in a 2-part series on Vision-Language Models — SmolVLM:
- SmolVLM to SmolVLM2: Compact Models for Multi-Image VQA (this tutorial)
- Generating Video Highlights Using the SmolVLM2 Model
To learn about SmolVLMs and perform a multi-image understanding task, just keep reading.
How would you like immediate access to 3,457 images curated and labeled with hand gestures to train, explore, and experiment with … for free? Head over to Roboflow and get a free account to grab these hand gesture images.
Need Help Configuring Your Development Environment?

All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code immediately on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
SmolVLM 1: A Compact Yet Capable Vision-Language Model
What Is SmolVLM?
In 2024, we saw a remarkable shift in the development of Vision-Language Models (VLMs). Initially, the field focused on scaling up compute and model size. Later, attention turned to scaling data diversity using synthetic samples. Recently, we’ve seen an exciting new direction: scaling down.
SmolVLM is the result of this trend. It’s a compact, memory-efficient VLM with only 2 billion parameters. Despite its size, it delivers competitive multimodal performance. While many state-of-the-art VLMs focus on scale and server-grade deployment, SmolVLM flips the narrative: it’s optimized for on-device inference, low memory consumption, and fast execution — all while delivering surprisingly strong results.
Why SmolVLM?
Large-scale VLMs (e.g., Flamingo, GPT-4V, and Gemini Pro) have shown impressive capabilities but come at a high cost — both in terms of compute and accessibility. On the other hand, SmolVLM offers a strong trade-off between efficiency and performance, making it:
- Small: Just 2B parameters
- Fast: High throughput during inference
- Efficient: Requires minimal GPU memory (5 GB)
- Open: Fully open-source under Apache 2.0
These traits make SmolVLM ideal for local deployment, browser-based use cases, and custom fine-tuning without high-end infrastructure.
The Three Variants of SmolVLM
SmolVLM comes in three distinct variants:
- SmolVLM-Base: A pre-trained model suitable for custom fine-tuning tasks.
- SmolVLM-Synthetic: Fine-tuned on synthetic VLM data to boost generalization.
- SmolVLM-Instruct: An instruction-tuned version ready for interactive applications.
Each variant is integrated into the transformers library, making them easy to use and extend.
Architecture Overview
SmolVLM is designed to bring powerful multimodal reasoning capabilities to resource-constrained environments. Unlike many small VLMs that simply shrink large models, SmolVLM rethinks architecture, tokenization, and data flows to maximize performance per compute.
The high-level architecture (Figure 1) is straightforward. Each input image (or video frame) is first split into sub-images and encoded by a Sigmoid Loss for Language-Image Pretraining (SigLIP) vision encoder. We then apply a pixel-shuffle (space-to-depth) operation to compress the features, feed them through a small MLP to produce “visual tokens,” and concatenate those tokens with the text token embeddings. This mixed sequence is passed into a SmolLM2 language model to produce the final text output.
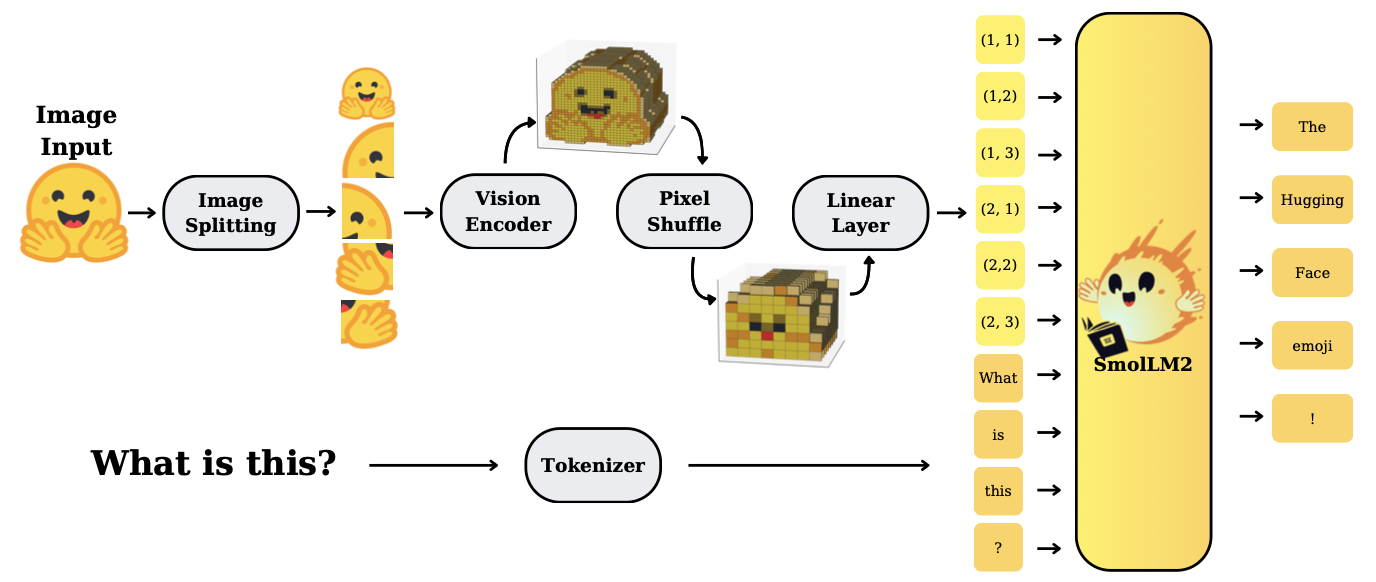
Marafioti, Zohar, et al. (2025) found that using smaller vision encoders complements a compact Large Language Model (LLM) — for example, pairing a 93M-parameter SigLIP-B/16 encoder with a 135M or 360M SmolLM2 instead of a huge encoder leads to better efficiency and only modest performance loss.
They also designed SmolVLM to handle high-resolution images and long contexts by extending the LLM’s context window (via RoPE scaling) and aggressively compressing visual tokens.
Overall, the systematic exploration of these choices yields a unified, cost-effective recipe for tiny VLMs.
Vision Encoder: SigLIP Variants
The architecture begins with Google’s SigLIP image encoders (a variant of Contrastive Language-Image Pretraining (CLIP)) for vision feature extraction. In particular, it pairs different SigLIP versions with each model size. SmolVLM uses two main SigLIP variants:
- SigLIP-B/16 (93M parameters, 16×16 patch size): for 256M and 500M models
- SigLIP-SO400M (428M parameters, 14×14 patches): for the 2.2B model
Experiments confirmed that smaller LMs get little extra benefit from a huge encoder, so we keep the encoder compact for the 135M and 360M LMs (SmolLM2). This balanced allocation — using a relatively small vision tower with a small language tower — turns out to be most efficient.
Pixel Shuffle (Space-to-Depth) for Image Compression
To fit images into the LLM’s fixed context size, the authors compress the visual features using pixel shuffle (aka space-to-depth) (Figure 2).
After SigLIP encodes an image patch into a feature map, pixel-shuffle rearranges it: it trades spatial resolution for extra channels.
Concretely, a 2×2 pixel shuffle turns each 2×2 block of pixels into 4 channels, so the feature map height and width each halve, reducing the token count by 4×. We found that this preserves information density but shrinks token count by  when using an
when using an  shuffle.
shuffle.
For example, a 512×512 image normally yields 1024 SigLIP patches, but after a 2×2 pixel shuffle, it yields only 256 “super-patches.” In our compact models, we even use a 3×3 shuffle (9× reduction) to be extra aggressive.
This saves huge attention costs: smaller VLMs actually benefit from more aggressive compression (they can afford to lose some fine detail because it greatly reduces overhead). By contrast, models like Idefics3 used only a 2×2 shuffle.

- Smaller models (e.g., SmolVLM-256M) benefit more from aggressive compression (
 ), whereas larger models use a lower ratio (
), whereas larger models use a lower ratio ( ) to preserve fine spatial detail.
) to preserve fine spatial detail. - This enables long-sequence handling (up to 16k tokens) while maintaining OCR and localization performance.
 ), whereas larger models use a lower ratio (
), whereas larger models use a lower ratio ( ) to preserve fine spatial detail.
) to preserve fine spatial detail.Visual Token Projection and Embedding
Once the compressed feature map from pixel shuffle is obtained, the authors flatten it into a sequence of vectors and map each to the LLM’s input embedding space.
Technically, this is done with a small feed-forward projection (an MLP) that takes each pixel-shuffled feature vector and outputs a “visual token” in the SmolLM2 embedding dimension. In other words, the MLP learns how to embed image features just like word embeddings.
These visual tokens are then concatenated or interleaved with the text token embeddings in the same input sequence.
In the LLM’s self-attention layers, the model now sees both visual tokens and text tokens jointly so that it can fuse image content with language. Because the projection is learned, we effectively teach the LLM how to interpret image features as part of its normal input.
Image Patching and Splitting Strategy
Handling high-resolution images is crucial for vision tasks, but the authors only have a limited token budget.
To maintain detail without huge cost, they break each large image into multiple sub-images (patches) plus a downsized overview.
In practice, when an image is high-res, they slide a window or split it into tiles and also include a lower-resolution version of the whole image. For example, one might split a big page into four quadrants of 384×384 plus a 256×256 downscaled full image.
Each sub-image is encoded separately (so smaller SigLIP inputs), and their tokens all go into the LLM.
They observed this “document splitting” (inspired by UReader/SPHINX) preserves visual fidelity while keeping token counts manageable. This strategy improves performance on image tasks. (Notably, they found a similar technique like frame-averaging for video hurt performance, so they dropped that for video.)
SmolLM2 as the Language Model and Context Extension
For the language backbone, SmolVLM uses SmolLM2, a family of small transformer LMs (135M, 360M, 1.7B parameters). The key goal is efficient inference, so the authors chose SmolLM2 instead of a large model (e.g., Llama 8B).
SmolVLM uses the SmolLM2 language model with three configurations:
- 135M parameters (SmolVLM-256M)
- 360M parameters (SmolVLM-500M)
- 1.7B parameters (SmolVLM-2.2B)
Importantly, the original SmolLM2 was limited to 2k tokens of context. However, even a single 512×512 image patch (encoded by SigLIP-B/16) produced 1024 visual tokens, which far exceeds 2k when you include text. To fix this, the authors extended the context window to up to 16k tokens by scaling the RoPE (rotary positional encoding) base from 10k to 273k.
We then fine-tuned the model on long-context data, so it learned to handle this longer history. In practice, our largest model can use a 16k token context (fitting the visual tokens plus any prompt), while the tiny 135M and 360M variants reliably use up to 8k.
Extending context was crucial: with 16k the model can see the full image at high resolution, whereas a 2k limit forced excessive downsizing.
Integrating Vision and Language Inputs (Prompt Structure)
In operation, SmolVLM receives a joint prompt containing both text and images. The authors found it important to mark the boundaries between language and visuals clearly.
For example, we prepend a short system prompt to clarify the task. If the user is asking a vision question, the prompt might start with “You are a visual assistant…”. If it’s a general conversation, we use “You are a helpful assistant…”. These instructions help reduce ambiguity.
Then, before each image or video, we insert a media intro token like “Here is an image:” or “Here are frames from a video:” and after the visuals, we use an outro like “Given this image…”. In code, this means the token sequence looks something like this:
![\large[\text{System Prompt}] \ldots [\text{Here is an image:}]\ {[<\!\!\text{VISUAL TOKENS}\!\!>]}\](https://b2633864.smushcdn.com/2633864/wp-content/latex/9c9/9c9bff0230ce0b0da72833ccc3fcb266-ffffff-000000-0.png?size=524x20&lossy=2&strip=1&webp=1 "\large[\text{System Prompt}] \ldots [\text{Here is an image:}]\ {[<\!\!\text{VISUAL TOKENS}\!\!>]}\")
![\large{[\text{Given this image},\ldots]}\ [\text{User question tokens}]\ [\text{Answer tokens} \ldots]](https://b2633864.smushcdn.com/2633864/wp-content/latex/131/131bd71e76a6cd471e2db3ac3375c701-ffffff-000000-0.png?size=531x20&lossy=2&strip=1&webp=1 "\large{[\text{Given this image},\ldots]}\ [\text{User question tokens}]\ [\text{Answer tokens} \ldots]")
So, the LLM clearly knows when visual content begins and ends. This structured prompting (with explicit cues around the images/videos) gave a big boost in performance, especially on video tasks.
Under the hood, the visual tokens generated by the MLP projection are simply placed in line with the text embeddings. Everything is sent together into SmolLM2 so the model attends to both text and vision jointly.
Learned Positional Tokens vs. String Layout Tokens
One tricky issue was how to tell the model where each sub-image fits.
The first approach was naive: include text tokens like  in the prompt to mark each patch’s position. This failed badly — training would plateau (the “OCR loss plague”), and the model struggled to learn to read text from images.
in the prompt to mark each patch’s position. This failed badly — training would plateau (the “OCR loss plague”), and the model struggled to learn to read text from images.
Instead, they introduced special learned positional tokens (one for each patch location) before encoding. In practice, they add an embedding token that encodes “this is patch (i,j)” for each sub-image. This change dramatically stabilized training.
The model learned these positional tokens much faster than raw string tags, and small models, in particular, got much better at optical character recognition (OCR) and spatial reasoning. In short, teaching the model dedicated learned embeddings for layout positions (instead of forcing it to parse a string) gave consistently higher accuracy.
Video Handling and Frame Strategy
SmolVLM also supports video by treating frames like images. In a video prompt, the authors insert a cue like “Here are frames sampled from a video:” before the frame tokens.
Originally, they experimented with averaging or combining frames to reduce token count, but that actually hurt performance on benchmarks. So, instead, they sample a few frames and resize each to the encoder’s input size.
In other words, each frame is downscaled (e.g., 384×384), then encoded by SigLIP and tokenized just like an image. This way the model sees the raw frames (with visual markers around them) and can still answer questions about motion or sequence.
Overall, they found that treating video frames like multiple images in the sequence works well as long as the prompt clearly marks them, and they avoid blurring them together.
Key Differences from Idefics3
Although SmolVLM builds on the same overall design as Idefics3, there are a few important differences.
First, the language backbone is different: Idefics3 uses Llama-2 (8B) as the text model, whereas SmolVLM swaps in our SmolLM2 1.7B.
Second, the authors compress vision tokens more aggressively. Idefics3 uses a 2×2 pixel shuffle (4× reduction), but SmolVLM uses a 3×3 shuffle (9× reduction) by splitting into 384×384 patches. (This change required adjusting patch size: we use 384×384 input patches — divisible by 3 — instead of the 364×364 that Idefics3 used.)
Third, they specifically use SigLIP encoders and learned position tokens as described above.
Finally, SmolVLM is designed to handle multi-image and video inputs, whereas the original Idefics3 focused on single images.
In short, they followed Idefics3’s implementation but tuned the core components for a much smaller, on-device setting (smaller LM, more compression, and extended context).
Trade-Offs and Efficiency Benefits
SmolVLM makes deliberate trade-offs to gain efficiency. The authors sacrifice some fine-grained visual detail by collapsing pixels (which can slightly hurt tasks like precise OCR), but this lets fit full-resolution scenes into a very small model.
The payoff is huge: for example, each 384×384 patch only becomes 81 tokens after pixel shuffle and splitting. A 512×512 image (4 patches) ends up as about 324 visual tokens plus the text, rather than the >16K tokens that some models use. Thanks to this, SmolVLM runs with very low memory.
The smallest 256M model inference uses under 1 GB of GPU RAM, and even the big 2.2B SmolVLM needs only  5 GB to answer with an image. This is dramatically less than competing 2B models (e.g., Qwen2-VL uses 13-16 GB in similar tests.
5 GB to answer with an image. This is dramatically less than competing 2B models (e.g., Qwen2-VL uses 13-16 GB in similar tests.
In practice, they see a much faster generation: fewer tokens means faster self-attention. All together, SmolVLM’s design choices (balanced vision and Lang capacity, extended 16k context, aggressive token compression, positional tokens, etc.) let it match or beat larger models on many benchmarks while using only a fraction of the compute.
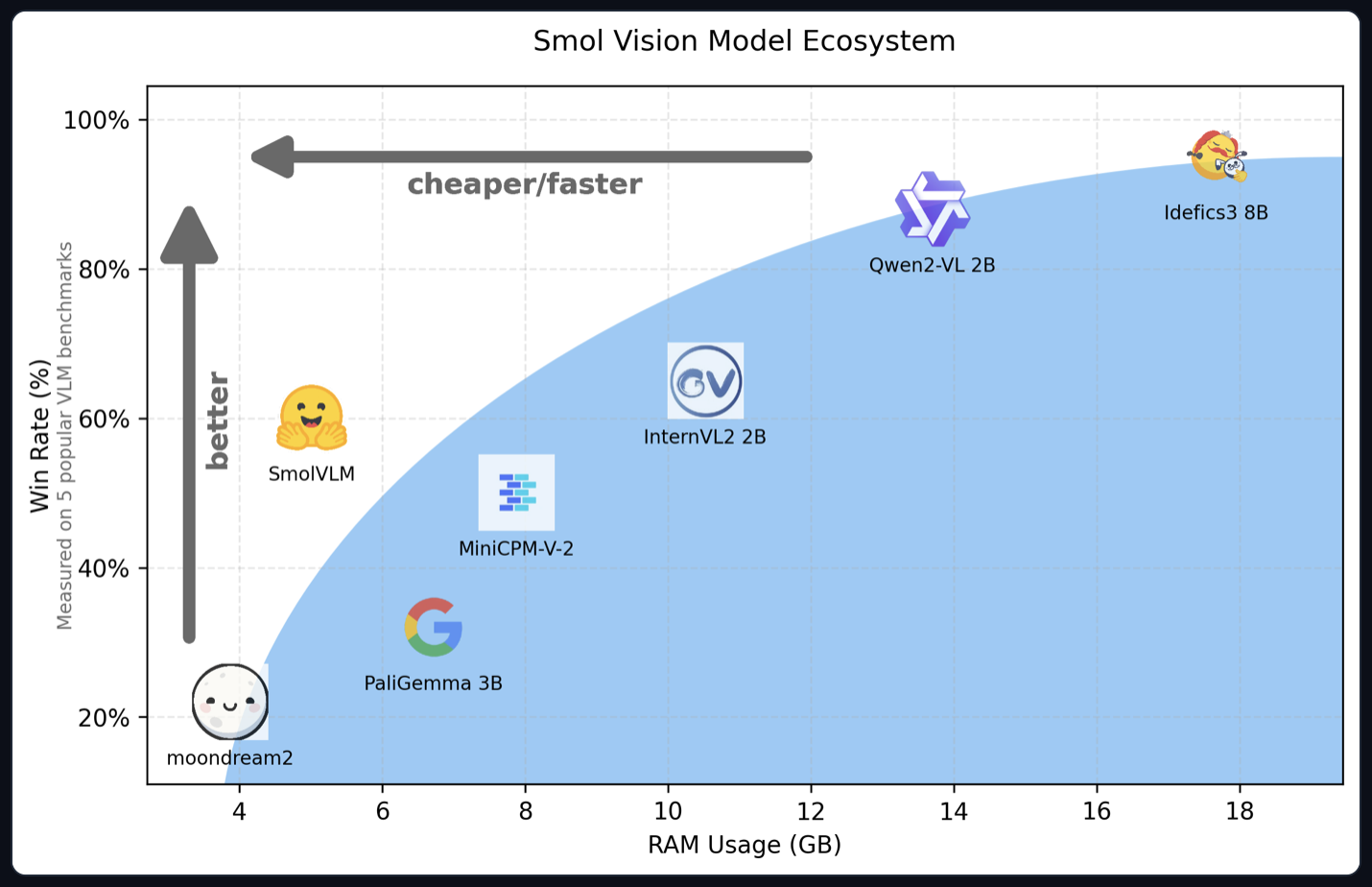
Memory Efficiency of SmolVLM
These models are memory-efficient yet match or outperform much larger models (e.g., Idefics-80B and Qwen2VL-2B) on many VQA and video understanding tasks (Figure 3).

Performance
In Figure 4, we can see that SmolVLM gives a nice trade-off between memory footprint and performance compared to other models in a similar size range.
Let’s see the performance benchmarks, memory footprint, and throughput of the SmolVLM model.
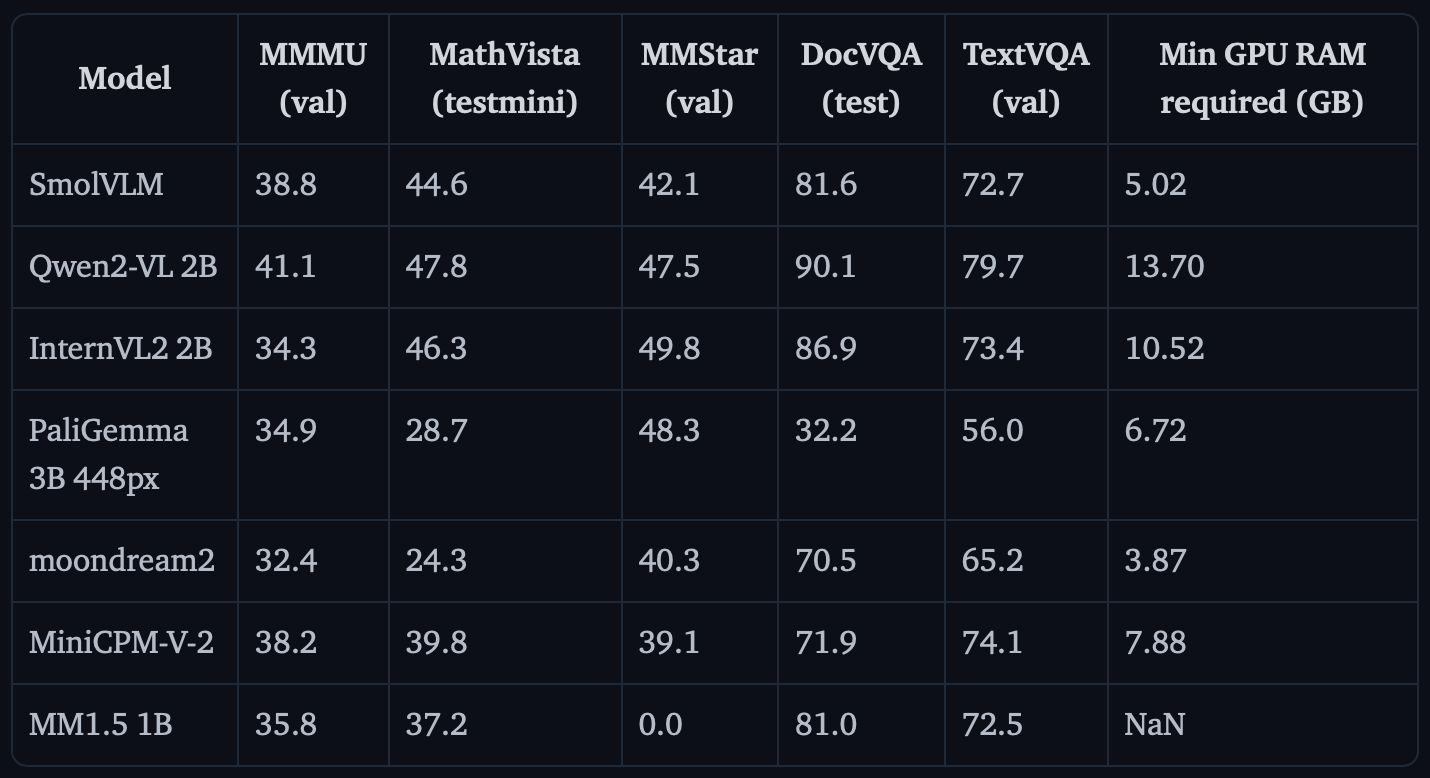
Benchmarks
In Figure 5, we can see the performance benchmark on some of the datasets compared to other models in the same size range. Its low memory usage (just 5 GB) and better performance make it one of the most accessible VLMs to deploy.
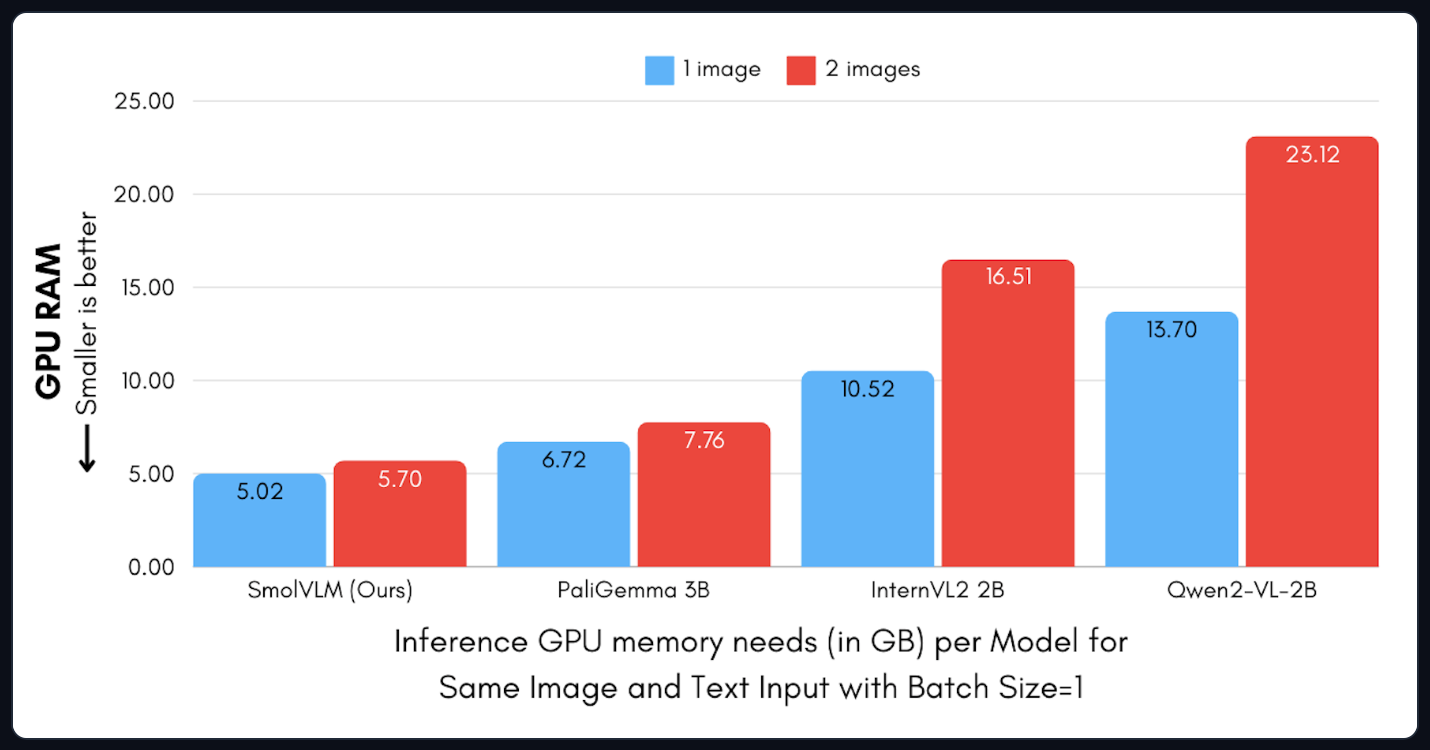
Memory
In Figure 6, we compare GPU memory usage (in GB) across models. We run inference with one and two images, using the same inputs and prompts for all models.
SmolVLM is efficient by design. It encodes each 384×384 image into just 81 tokens. So, with one image and a test prompt, SmolVLM processes only 1.2k tokens. In comparison, Qwen2-VL expands this to 16k tokens.
This efficiency becomes more noticeable when we add a second image. Models like Qwen2 and InternVL show a large jump in memory use. But for SmolVLM and PaliGemma, the increase stays modest — thanks to their shared approach to image encoding. This makes it ideal for running on-device, even on a laptop.
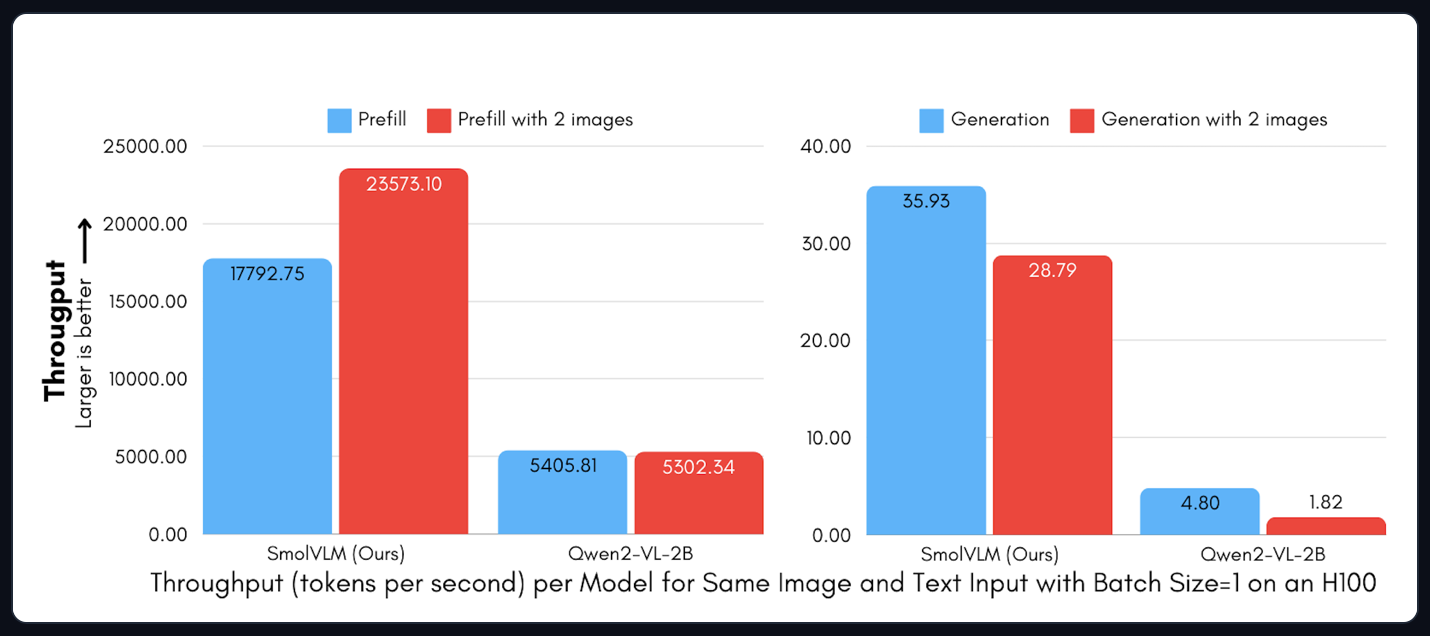
Throughput
SmolVLM’s small memory footprint also means it needs fewer computations during prefill and generation.
When we compare throughput (Figure 7), SmolVLM is much faster than Qwen2-VL. The prefill stage (where the model processes the full input prompt (text + image embeddings)) is 3.3 to 4.5× faster. The generation stage is 7.5 to 16× faster.
Video
Marafioti, Zohar, et al. (2025) also tested SmolVLM on video analysis. By sampling 50 frames per video and feeding them as image sequences, they observed surprisingly strong results on the CinePile benchmark.
- CinePile score: 27.14%
- This places SmolVLM between InternVL2 (2B) and Video-LLaVA (7B).
Training Strategy
Let’s briefly discuss the training strategy used by SmolVLM.
Vision Training Datasets and Tasks
Marafioti, Zohar, et al. (2025) use a two-stage training process: first, a vision stage, then a video stage.
For the vision stage, they built a new mixed dataset drawing on previous work (Laurençon et al., 2024) and added a MathWriting corpus. They balanced this mix to emphasize visual understanding and structured data tasks, while still keeping some reasoning problems.
In practice, this means the model sees document understanding, image captioning, and visual question-answering examples (with a bit of multi-image reasoning), as well as chart and table understanding and other visual reasoning tasks.
They also retained a modest amount of pure text Q&A and logic problems (including math and coding challenges) so the model remembers general knowledge. This blend of tasks prepares SmolVLM to handle a range of visual-language queries.
Pixel Shuffle and Image Patch Handling
Marafioti, Zohar, et al. (2025) took care to feed images into the language model efficiently. First, high-resolution images are split into patches (break each image into multiple sub-images plus a downscaled copy). Each patch is then encoded by the vision encoder, yielding feature maps.
To compress these features, they apply a pixel shuffle (space-to-depth) operation. This rearranges the spatial grid into more channels (trading resolution for depth), which drastically reduces the number of tokens while preserving detail.
Finally, an MLP projects these shuffled features into visual tokens that are concatenated or interleaved with the text tokens for the LLM. Together, splitting + pixel shuffle keeps the input token count low without losing much visual information.
- Image Splitting: They divide each image into several smaller patches plus a downsized copy. This maintains image fidelity without exploding token count.
- Pixel Shuffle: They use pixel-shuffle to trade spatial resolution for channel depth. The result is far fewer visual tokens to process in the LLM, which improves efficiency.
- Frame Handling: For videos, they sample individual frames and treat them like images (resizing to the encoder’s input size). We do not average frames together, because they found that frame-averaging hurt performance. Instead, each frame is encoded separately and passed through the same splitting + shuffle pipeline.
Prompt Structure, Media Intros/Outros, and Formatting
The authors found that careful prompt design helps SmolVLM understand tasks better. In zero-shot queries, they prepend a short system prompt to explain the task. For example, we might say, “You are a useful conversational assistant” for chat data, or “You are a visual agent and should provide concise answers” for vision tasks. These fixed instructions clarify the goal and significantly boost accuracy (especially on image questions).
They also explicitly mark where the visual content appears. They insert media intro/outro markers around images and videos. For example, we might prefix an image with “Here is an image:” and end the segment with “Given this image, …”. Similarly, for videos, we might say “Here are frames sampled from a video:” followed by “Given this video, …”. These cues help the model know when vision content starts and ends. Using these intros/outros gave a large performance lift on video tasks (and a noticeable boost on image tasks).
Finally, during supervised fine-tuning (SFT), we mask out user prompts and train only on the model’s completion. In other words, they hide the user’s question and focus the loss on the answer. This simple trick (borrowed from Allal et al., 2025) prevents the model from “cheating” by memorizing questions. In practice, they observed that masking user prompts improved both image and video accuracy.
Learned Positional Encodings vs. String Tokens
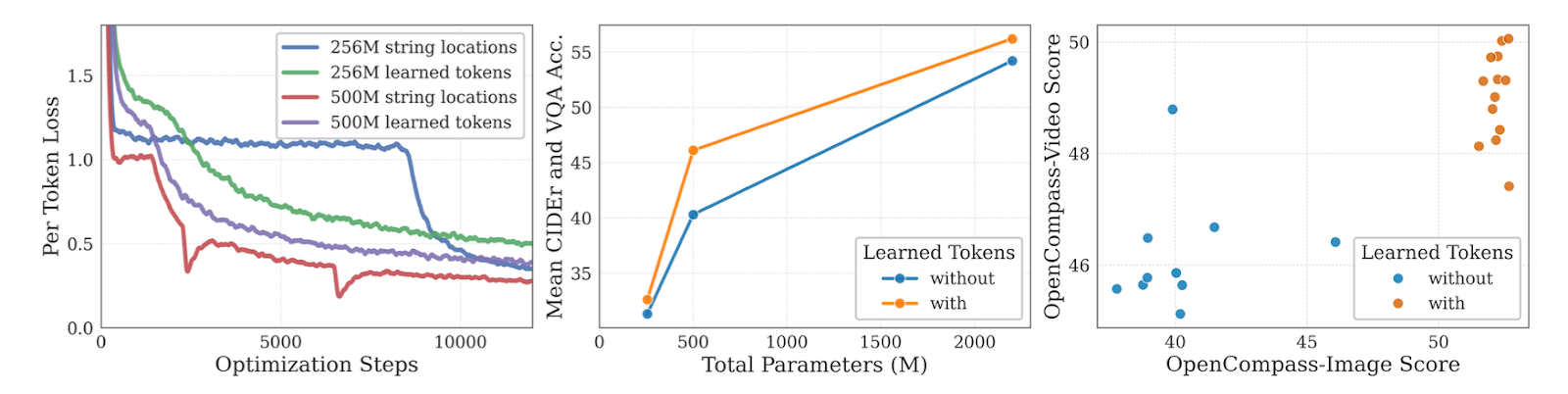
A key implementation detail was how to label each image patch’s position. Early on, Marafioti, Zohar, et al. (2025) tried using string tokens like  to tag each patch. However, small models struggled: training would plateau (the so-called “OCR loss plague”) without any gain in OCR accuracy. The model basically got confused by raw text tokens for positions.
to tag each patch. However, small models struggled: training would plateau (the so-called “OCR loss plague”) without any gain in OCR accuracy. The model basically got confused by raw text tokens for positions.
To fix this, they introduced learned positional tokens. Instead of spelling out coordinates, the model learns special position embeddings for patch positions. This change stabilized training and dramatically improved results. In fact, learned tokens gave much higher OCR accuracy and better overall scores than the naive string labels.
For example, Figure 8 shows that models with learned tokens consistently beat string tokens on multiple benchmarks. In short, for compact VLMs, structured positional tokenization works far better than raw text hints.
Video Fine-Tuning: Data Mix and Frame Strategy
After the vision stage, Marafioti, Zohar, et al. (2025) fine-tune video tasks using a mix of text and video data.
Inspired by prior work, they keep a certain fraction of training as text Q&A (so the model remembers language) and the rest as video examples. For the video portion, they sample from a variety of datasets: video captioning and description (LLaVA-video-k, Video-STAR, Vript, ShareGPT4Video), temporal reasoning (Vista-k), and narrative comprehension (MovieChat, FineVideo).
They also include some multi-image examples from M-Instruct and Mammoth, so the model can compare multiple frames or views when needed. The specific ratio of text-to-video was chosen based on prior tuning: they found a balanced mix that achieves the best performance.
For frame sampling, they sample frames and resize them for the encoder rather than combining them. They do not use any frame-averaging or other merging tricks because experiments showed those hurt the model. Each video frame is treated individually by the same image pipeline, so the language model sees a sequence of visual tokens from separate frames (with our intro/outro markers to avoid confusion).
Instruction Tuning: Prompts, Masking, CoT, and SFT Insights
During supervised instruction tuning, the authors uncovered several practical lessons:
- System Prompts and Masking: As above, using system-level prompts (“You are a visual assistant…”) and media markers greatly improved results. They also found that always masking out user queries during fine-tuning helped the model focus on the answer, avoiding overfit to repetitive questions. In effect, they only compute loss on the model’s completion tokens.
- Chain-of-Thought (CoT) Data: They experimented with adding explicit reasoning steps (CoT) to our training. They found that very little CoT is best. In the tests, adding only about 0.02-0.05% chain-of-thought examples gave a slight performance gain. However, heavier CoT usage actually degraded performance on vision tasks. It seems too much text-heavy reasoning data overwhelms a small VLM’s capacity. So, they keep CoT examples to a minimum.
- LLM Fine-tuning Text (SmolTalk): Another surprise was that reusing the text data from LLM instruction-tuning (our “SmolTalk” corpus) hurt performance. Intuitively, one might think more text is better, but for the small multimodal model it reduced accuracy by several percent. This likely comes from reduced data diversity. Following Zohar, Wang, et al. (2024), they, therefore, fixed the training mix to a modest amount of text (around 14%) and did not reuse large LLM SFT datasets.
These findings highlight that small VLMs need careful tuning. Simple tricks that help large LLMs (e.g., dumping tons of CoT or reusing huge text mixes) can actually hurt SmolVLM.
Benchmarks Used for Evaluation
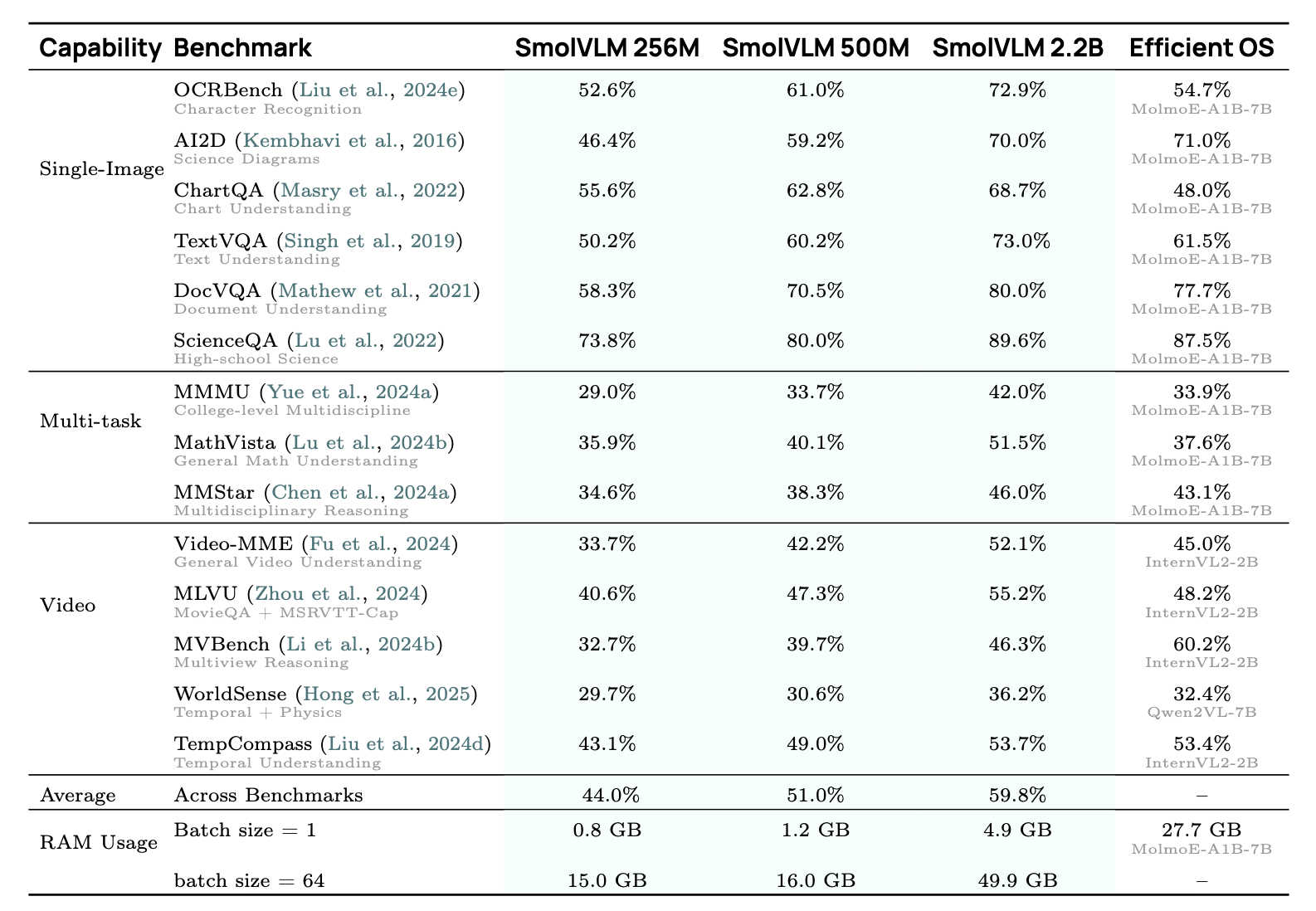
Marafioti, Zohar, et al. (2025) evaluated SmolVLM using VLMEvalKit for consistency and reproducibility.
Results were reported on a wide suite of benchmarks — nine vision-language tasks and five video tasks. These include: OCRBench (text extraction from images), diagram tasks (AI2D, ChartQA), VQA tasks (TextVQA, DocVQA, ScienceQA), and advanced reasoning sets (MMMU, MathVista, MMStar).
On the video side, they cover the following benchmarks: Video-MME (multi-modal embeddings), MLVU (multi-task long video understanding), MVBench, WorldSense, and TempCompass.
Figure 9 shows SmolVLM’s scores on each, confirming that even the smallest 256M model is competitive on many tasks. They compare against other efficient open-source VLMs (e.g., MolmoE, InternVL), often achieving state-of-the-art in their size class.
Ablation Findings and Design Choices
Our ablation studies revealed several key insights about the model’s design:
- Long Context Helps: We tested various context window sizes. We found that even compact VLMs benefit from very long contexts. Our 2.2B model was stable up to 4096 tokens of context (adopting this as our default), whereas smaller models topped out around 2048. This extended context improved performance on long instructions and document queries.
- Aggressive Token Compression: Contrary to larger models, SmolVLM works well with heavy compression of visual tokens. We experimented with different pixel-shuffle ratios. Larger ratios (more spatial reduction) cut token count drastically and actually improved performance in our small models. This is because fewer tokens reduce attention overhead. In practice, we use a fairly aggressive shuffle factor (similar to Idefics) to balance detail with efficiency.
- Image Splitting and Frame Averaging: We confirmed that splitting images into patches yields better results. Trying to merge frames (frame-averaging) was consistently detrimental, so we dropped it. Instead, we rescale each frame independently, ensuring no loss of temporal information.
- Structured Tokens: The switch to learned positional tokens (instead of string labels) was critical. As noted earlier, the “OCR loss plague” went away when we used learned tokens.
- Prompt Engineering: Each introduced prompt strategy (system prompts, media markers, masking) gave incremental gains. Figure 10 shows a clear stepwise improvement as we add these techniques.
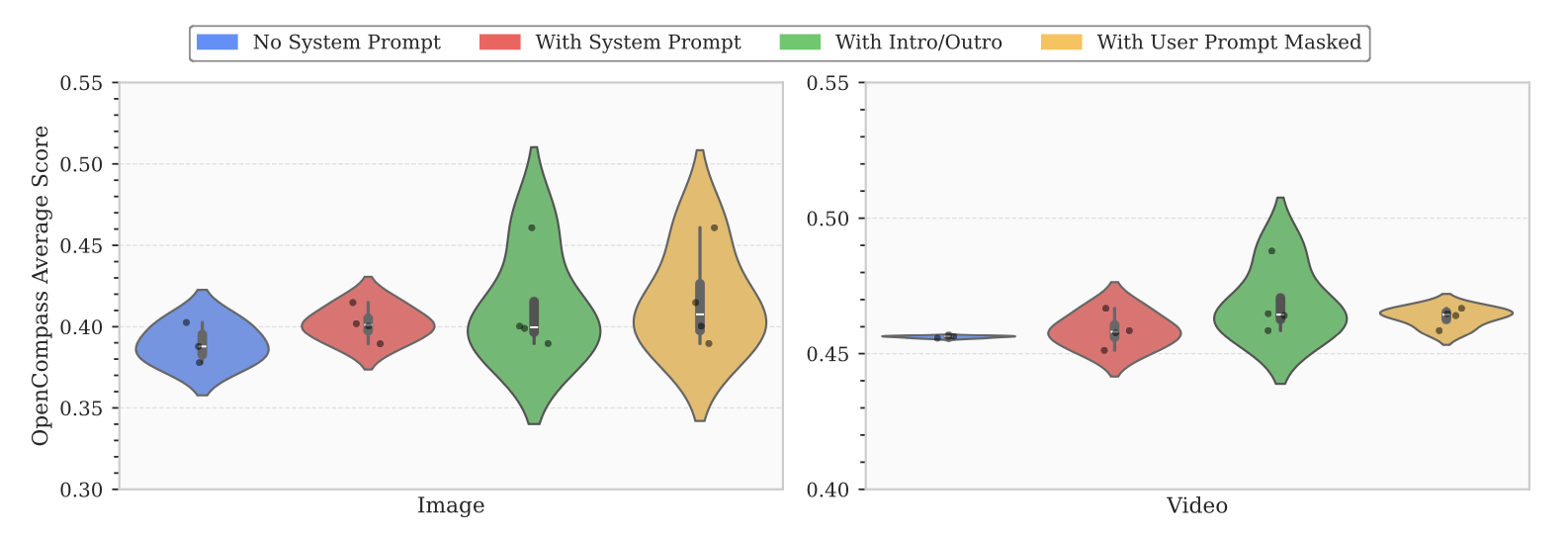
In summary, the best-performing setup for SmolVLM comes from these careful choices: extended context, aggressive spatial tokenization (pixel-shuffle), patch splitting, learned tokens, and structured prompts. We ablated each factor to arrive at this combination.
Deployment and Real-World Readiness
A major goal was to make SmolVLM usable on edge devices.
To that end, Marafioti, Zohar, et al. (2025) built and tested on-device variants and demos. The smallest 256M and 500M models (SmolVLM-M) are optimized for mobile/edge use. They ran benchmarks on consumer-grade hardware: for example, on an NVIDIA A100 GPU, the 256M model processes hundreds of examples per second, even at batch size 1.
They also exported the models to Open Neural Network Exchange (ONNX) format, enabling them to run on many platforms. Impressively, they demonstrated SmolVLM running in a browser via WebGPU: the 500M model can decode on the order of 2-3k tokens per second on a MacBook Pro (Apple M1/M2).
They accompany this release with user-friendly demos. For instance, Hugging Face hosts a “ColSmolVLM” demo that runs the small SmolVLM models directly in the browser or on-device.
Another showcase is SmolDocling, a 256M-parameter variant tailored for document OCR/formatting, which operates efficiently even on low-power machines.
There’s also Biomedical Visual Question Answering (Bio VQA), a compact SmolVLM adapted to answer biomedical image questions.
In practice, the team has provided Hugging Face Spaces, iOS apps (e.g., HuggingSnap), and Colab notebooks so anyone can try SmolVLM live. All code and weights are open-source, making it straightforward to deploy SmolVLM in real-world settings.
In short, SmolVLM is not just a research model but is ready for practical use. Its small size and efficient design let it run on modern mobile/edge hardware and have supplied demos and libraries so developers can integrate it today.
SmolVLM2: Taking Visual and Video Understanding to the Next Level
SmolVLM2 represents a major step forward from the original SmolVLM family. We move from lightweight visual understanding to true video reasoning — while keeping the model small, fast, and accessible across all devices.
The goal remains simple: Make vision and video understanding available everywhere — from mobile phones to servers.
Key Updates from SmolVLM1 to SmolVLM2
Video Understanding: SmolVLM2 can now handle video inputs directly. It shows strong results on video benchmarks like Video-MME (Figure 11), outperforming all existing models in the 2B parameter range.
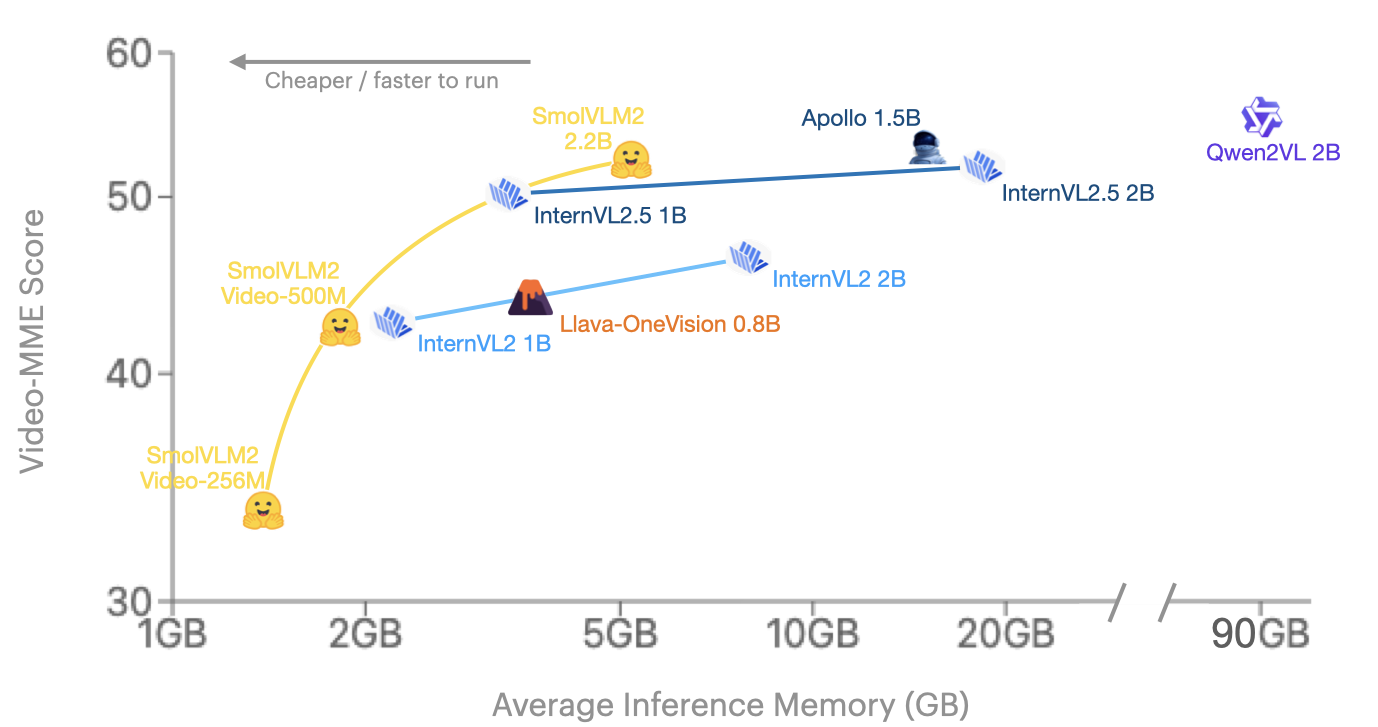
Three Model Sizes: Releasing SmolVLM2 in three sizes:
- 2.2B (recommended for vision and video tasks)
- 500M (compact, strong video capabilities)
- 256M (experimental, pushing the limits of small models)
MLX Ready: All models are MLX compatible, with support for both Python and Swift APIs.
Better Efficiency: Despite adding video capabilities, SmolVLM2 remains extremely memory-efficient. It can even run in a free Google Colab.
SmolVLM2-2.2B: The New Star Model
SmolVLM2-2.2B brings big improvements (Figure 12) across:
- Math with images (MathVista)
- Reading text in images (OCRBench)
- Understanding complex diagrams (AI2D)
- Scientific visual reasoning (Science QA)
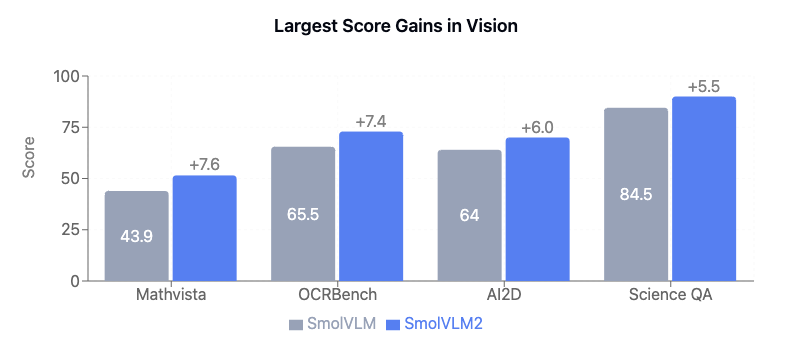
It also delivers strong performance on video benchmarks like Video-MME, maintaining a good balance between video and image understanding. The improvements are driven by better training recipes, especially inspired by Apollo’s data mixture strategies.
Going Even Smaller: SmolVLM2-500M and SmolVLM2-256M
- SmolVLM2-500M-Video-Instruct: Delivers video understanding almost on par with the 2.2B model, at less than a quarter of the size.
- SmolVLM2-256M-Video-Instruct: An experimental release that tests the extreme limits of small model video understanding. It aims to inspire creative applications and specialized fine-tuning efforts.
Now, we will move on to show a simple demo of multi-image understanding using the SmolVLM2-2.2B-Instruct model.
Configuring Your Development Environment
To follow this guide, you need to have the following libraries installed on your system.
!pip install -q transformers num2words flash-attn
transformers: to load the SmolVLM2 model and processor. It handles everything from tokenization to model inference.num2words: required to run the SmolVLM2 processor. It converts numerical digits (e.g.,5) into their corresponding word representations (e.g.,"five"). This normalization is helpful when preparing text inputs for vision-language models, as it ensures consistency with natural language patterns commonly found in training data. For example, an image caption like"There are 3 dogs"is converted to"There are three dogs", improving model understanding in tasks like image captioning or visual question answering.flash-attn: an optimized implementation of attention mechanisms, allowing the model to run faster and more efficiently, especially on GPU. It’s particularly useful for handling longer sequences or multi-modal prompts.
Be sure you have a CUDA-enabled GPU for best performance since you are using flash-attn.
Setup and Imports
import torch from IPython.display import Image, display from transformers import AutoProcessor, AutoModelForImageTextToText
We begin by importing torch, which are used to handle tensor computations efficiently. Next, we bring in Image and display from IPython.display to render and visualize images directly within the notebook environment — an essential feature when working with vision-based tasks.
From the Hugging Face Transformers library, we import AutoProcessor to automatically load the SmolVLM2 processor, which handles both image and text preprocessing. We also import AutoModelForImageTextToText, which loads the SmolVLM2 model designed to take image-text inputs and generate text outputs — enabling a wide range of vision-language applications.
Load the SmolVLM2 Model and Processor
model_path = "HuggingFaceTB/SmolVLM2-2.2B-Instruct"
We load the SmolVLM2 model and its associated processor using the model_path, which points to the "HuggingFaceTB/SmolVLM2-2.2B-Instruct" checkpoint hosted on the Hugging Face Hub.
processor = AutoProcessor.from_pretrained(model_path)
The processor is initialized using AutoProcessor.from_pretrained(), which prepares the image and text inputs in a format compatible with the model.
model = AutoModelForImageTextToText.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
_attn_implementation="flash_attention_2"
).to("cuda")
We then load the model itself with AutoModelForImageTextToText.from_pretrained(), specifying torch_dtype=torch.bfloat16 to use bfloat16 precision for better memory efficiency on modern GPUs. Additionally, we enable flash_attention_2 for faster and more efficient attention computation. Finally, the model is moved to the GPU using .to("cuda") to leverage hardware acceleration during inference.
Display Image
image1_url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg" display(Image(url=image1_url, width=400, height=300))
This code block displays an image (Figure 13) directly within the notebook interface using IPython’s display() and Image() functions. The first image is loaded from a Hugging Face-hosted URL and rendered at a width of 400 pixels and a height of 300 pixels.

image2_url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/0052a70beed5bf71b92610a43a52df6d286cd5f3/diffusers/rabbit.jpg" display(Image(url=image2_url, width=300, height=400))
Similarly, the second image is fetched from another Hugging Face URL and displayed (Figure 14) at a width of 300 pixels and a height of 400 pixels.

These images will be used later as inputs for visual understanding tasks with the SmolVLM2 model.
Build a Chat Template
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "What are the differences between these two images?"},
{"type": "image", "url": image1_url},
{"type": "image", "url": image2_url},
]
},
]
Now, we construct a chat-style input prompt that aligns with the SmolVLM2 model’s expected input format. We define a list named messages, where each entry simulates a conversational exchange. Here, a single message is created from the user role. The content field contains a mix of text and visual inputs: a text query asking about the differences between two images, followed by the two image URLs defined earlier.
This structure enables the model to process both textual and visual information simultaneously, allowing it to perform complex vision-language reasoning.
Initialize Processor
inputs = processor.apply_chat_template( messages, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt", ).to(model.device, dtype=torch.bfloat16)
In this step, we prepare the input for the SmolVLM2 model by using the apply_chat_template method from the processor.
This method formats the messages into a structure suitable for vision-language understanding tasks. By setting add_generation_prompt=True, we signal the model that it should generate a response based on the input. The tokenize=True argument ensures that the combined text and image inputs are tokenized appropriately. return_dict=True returns the processed inputs as a dictionary, and return_tensors="pt" ensures the output is in PyTorch tensor format.
Finally, we move the inputs to the same device as the model (CUDA-enabled GPU) and cast them to torch.bfloat16 for optimized computation.
Generate the Output
In this final step, we generate a response from the SmolVLM2 model based on the processed inputs.
generated_ids = model.generate(**inputs, do_sample=False, max_new_tokens=100) generated_texts = processor.batch_decode( generated_ids, skip_special_tokens=True, ) print(generated_texts[0])
The model.generate() function produces token IDs for the output text, with do_sample=False ensuring deterministic generation and max_new_tokens=100 limiting the length of the response.
These generated token IDs are then decoded back into human-readable text using the processor’s batch_decode method, where skip_special_tokens=True removes any special tokens like  or
or  .
.
Finally, we print the first item in the output list, which contains the model’s answer to the visual question.
User: What are the differences between these two images? Assistant: The first image is a photograph of a bee on a pink flower, with a blurred background of other flowers and plants. The bee is in the center of the frame, and the flower is in sharp focus. The second image is a digital painting of a rabbit in a blue coat and brown pants, standing on a dirt path in a rural setting. The rabbit is the main focus of the image, and the background is blurred to emphasize the rabbit.
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: March 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
SmolVLM proves that we don’t need massive models to achieve strong vision-language performance. By combining careful design (e.g., aggressive pixel shuffling, small vision and language backbones, and smart prompt formatting), we get a model that runs fast, fits on consumer GPUs, and still holds its own across a range of benchmarks.
With SmolVLM2 extending these capabilities to video more efficiently, we’re moving closer to real-world multimodal applications that can run anywhere — from servers to smartphones.
We explored how SmolVLM handles multiple images using a simple but powerful pipeline. We loaded the SmolVLM2 model and processor using Hugging Face Transformers, displayed two images, and used a chat-style prompt to ask a question comparing them. We applied the processor’s chat template, passed everything to the model, and decoded the generated output.
In the next tutorial, we will move from images to videos and will guide you to create your own video highlights using the SmolVLM2 model. Stay Tuned!
Citation Information
Thakur, P. “SmolVLM to SmolVLM2: Compact Models for Multi-Image VQA,” PyImageSearch, P. Chugh, S. Huot, G. Kudriavtsev, and A. Sharma, eds., 2025, https://pyimg.co/wgq8x
@incollection{Thakur_2025_smolvlm-to-smolvlm2-compact-models-for-multi-image-vqa,
author = {Piyush Thakur},
title = {{SmolVLM to SmolVLM2: Compact Models for Multi-Image VQA}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Georgii Kudriavtsev and Aditya Sharma},
year = {2025},
url = {https://pyimg.co/wgq8x},
}
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.