
Table of Contents
- Build a Search Engine: Semantic Search System Using OpenSearch
- Introduction
- Why Semantic Search? (Beyond Keyword Matching)
- How Semantic Search Works
- How OpenSearch Performs Semantic Search
- Why Does This Matter for Movie Search?
- Configuring Your Development Environment
- Project Structure
- Executing Semantic Search Queries in OpenSearch
- Understanding and Implementing Neural Search in OpenSearch
- Running a Neural Search Query in OpenSearch
- Code Implementation: find_similar_movies.py
- Understanding the perform_search Function
- Example Search Query and Response in OpenSearch
- Running and Evaluating Search Queries
- AWS Users: Adapting This Setup for OpenSearch on AWS
- Summary
Build a Search Engine: Semantic Search System Using OpenSearch
In this tutorial, you will learn how to perform semantic search in OpenSearch by querying indexed embeddings using k-NN search, and retrieving similar movies.

This lesson is the last of a 3-part series on Building a Semantic Search System with AWS OpenSearch:
- Build a Search Engine: Setting Up AWS OpenSearch
- Build a Search Engine: Deploy Models and Index Data in AWS OpenSearch
- Build a Search Engine: Semantic Search System Using OpenSearch (this tutorial)
To learn how to implement semantic search in OpenSearch using embeddings and k-NN retrieval, just keep reading.
Introduction
In the previous post, we walked through the process of indexing and storing movie data in OpenSearch. We set up an ingest pipeline, deployed a Sentence Transformer model, and successfully generated embeddings for movie plot summaries. By the end, we had metadata and vector embeddings stored in OpenSearch, laying the foundation for semantic search — a more intelligent way of retrieving relevant content.
Now, we take the next step: building a semantic search system that retrieves movies based on their meaning rather than just matching keywords. Unlike traditional keyword-based search, which relies on exact word matches, semantic search enables OpenSearch to understand intent and find conceptually related results, even if they don’t share the same words. This approach dramatically improves search relevance, especially for natural language queries where users might describe a movie rather than using its exact title or keywords.
In this tutorial, we’ll explore how OpenSearch performs k-NN (k-Nearest Neighbor) search on embeddings. By leveraging vector similarity, OpenSearch efficiently retrieves movies with the most similar plot summaries — making it an invaluable tool for recommendation systems, intelligent search, and natural language understanding.
By the end of this post, you’ll know how to:
- Query OpenSearch using neural search to find semantically similar movies based on embeddings.
- Run k-NN search to find relevant results based on meaning, not just words.
Why Semantic Search? (Beyond Keyword Matching)
Traditional keyword-based search works by matching exact words in a query to those present in indexed documents. This approach is effective for structured data and simple lookups, but it struggles with:
- Synonyms and Context: A search for “sci-fi adventure” won’t return results containing “science fiction journey” unless the exact phrase appears.
- Misspellings and Variations: Small differences in spelling or phrasing can cause relevant documents to be missed.
- Conceptual Understanding: If someone searches for “a movie about space travel and time dilation,” a traditional search might not return Interstellar unless those exact words appear.
Semantic search, on the other hand, uses embeddings to understand the meaning behind queries. Instead of looking for exact words, it compares vector representations of text to find conceptually similar results. This allows OpenSearch to:
- Retrieve relevant results even if exact words don’t match.
- Understand intent rather than just words.
- Handle synonyms, variations, and related concepts naturally.
Example of Lexical Search:
In Figure 1, a lexical search for “Where was the last world cup?” only finds exact word matches, ranking sentences based on term frequency rather than meaning. This could lead to irrelevant results, like sentences containing “world cup” but referring to unrelated contexts. In this case, the winning response is on the first row as circled, “The last world cup was in Qatar”. This is the correct response, luckily. However, this won’t always be the case, as we will see in the next example.

However, keyword-based search fails when:
- The query and stored text use different words with the same meaning.
- It ranks results based on exact keyword overlap rather than intent.
The Problem with Lexical Search
Figure 2 highlights a real problem — queries can match completely irrelevant results if word similarity is considered without understanding the context.
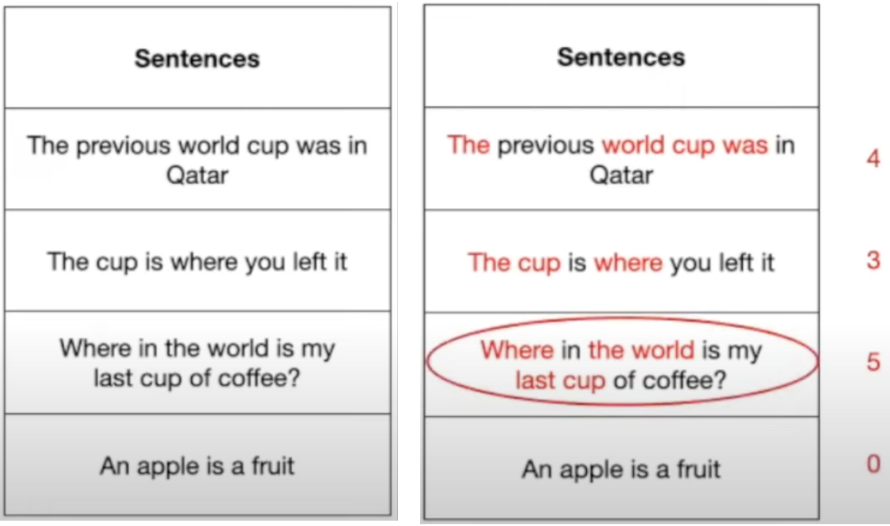
For instance, searching for “Where was the last world cup?” can mistakenly retrieve sentences like “Where in the world is my last cup of coffee?” due to overlapping words. This is why a deeper understanding of semantic meaning is crucial.
How Semantic Search Works
Semantic search overcomes this limitation by understanding intent and meaning rather than relying solely on word matching. It leverages vector embeddings to represent text as numerical values in a multi-dimensional space.
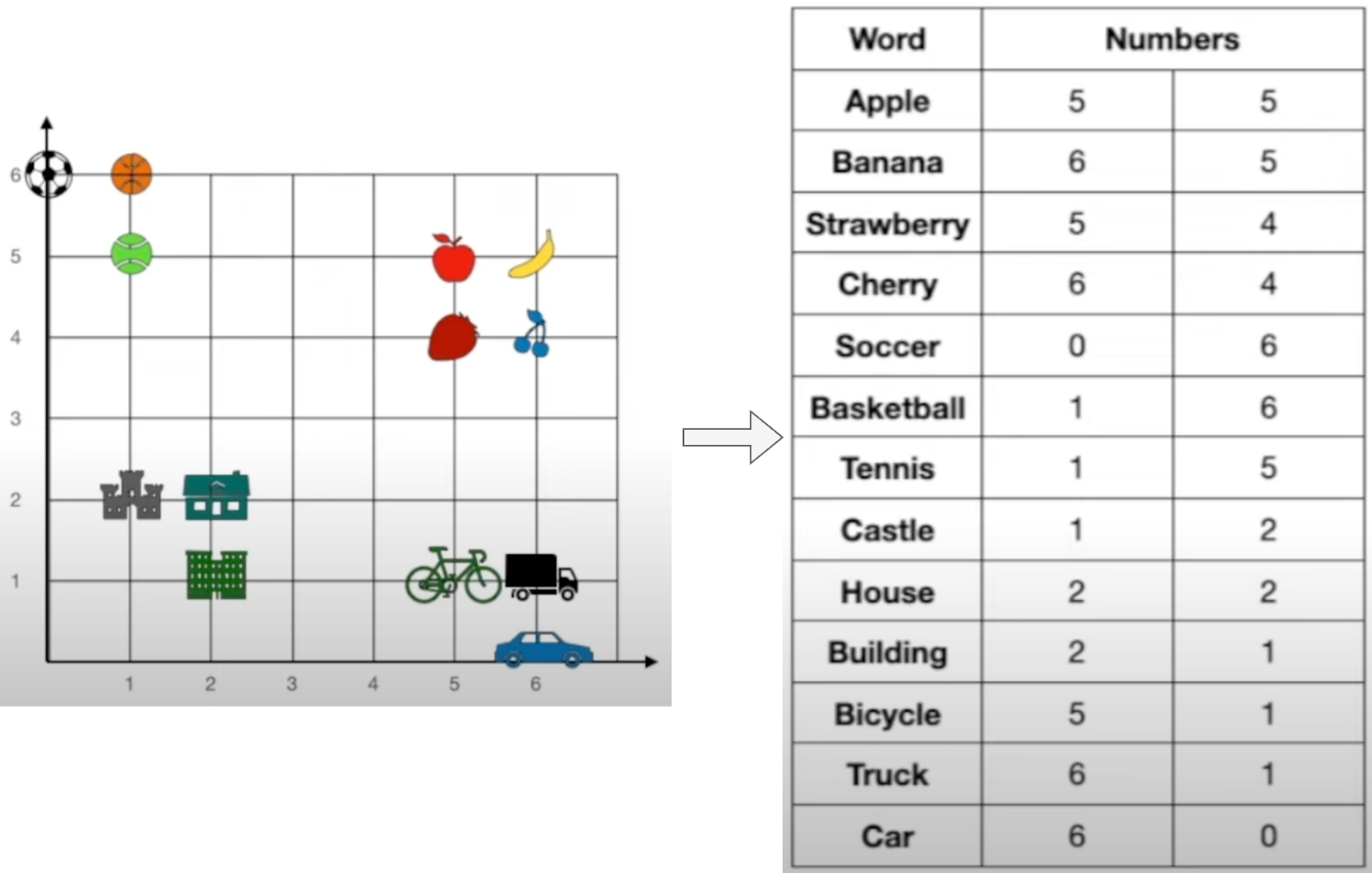
What Are Embeddings?
Instead of searching for exact words, semantic search converts text into numerical embeddings, as shown in Figure 3. Each word or sentence is mapped to a high-dimensional vector space, where similar meanings cluster together.
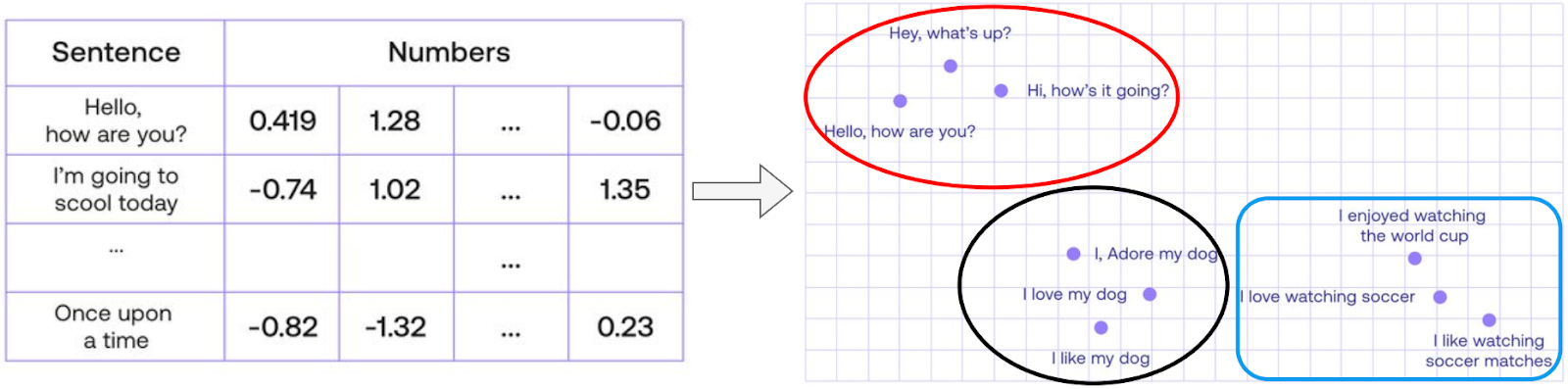
Sentence Embeddings in Action
Figure 4 demonstrates sentence embeddings in a 2D space, grouping similar sentences. Sentences like “I love my dog” and “I, Adore my dog” are positioned closer because they convey the same meaning, even though they use different words.
Nearest Neighbors and Semantic Search
Finally, Figure 5 illustrates how nearest neighbor search is used to retrieve similar sentences based on embeddings. When a user searches for “Where is the world cup?”, the system finds semantically similar results by identifying the closest vectors in the embedding space.
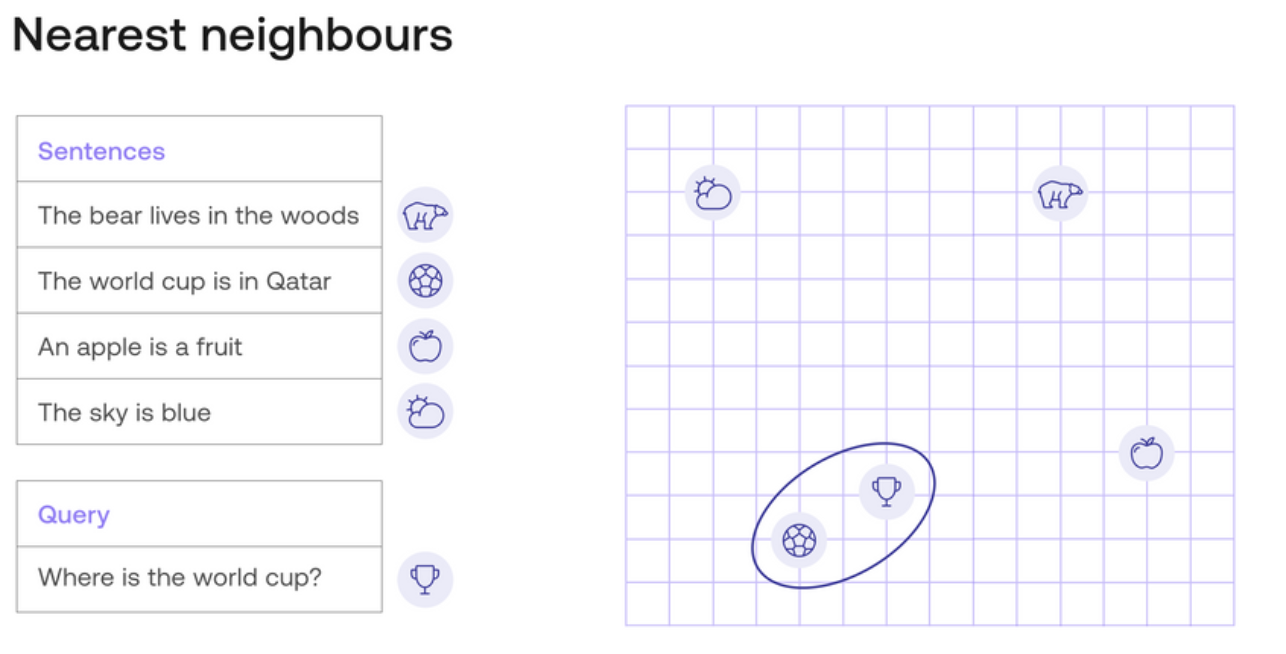
This nearest neighbor approach is fundamental to semantic search, whether used in OpenSearch or any other vector-based retrieval system.
How OpenSearch Performs Semantic Search
Now that we understand why traditional keyword search has limitations and how embeddings help in capturing semantic meaning, let’s explore how OpenSearch uses vector search (k-NN search) to retrieve similar documents.
How OpenSearch Uses Neural Search and k-NN Indexing
Figure 6 illustrates the entire workflow of how OpenSearch processes a neural query and retrieves results using k-Nearest Neighbor (k-NN) search.
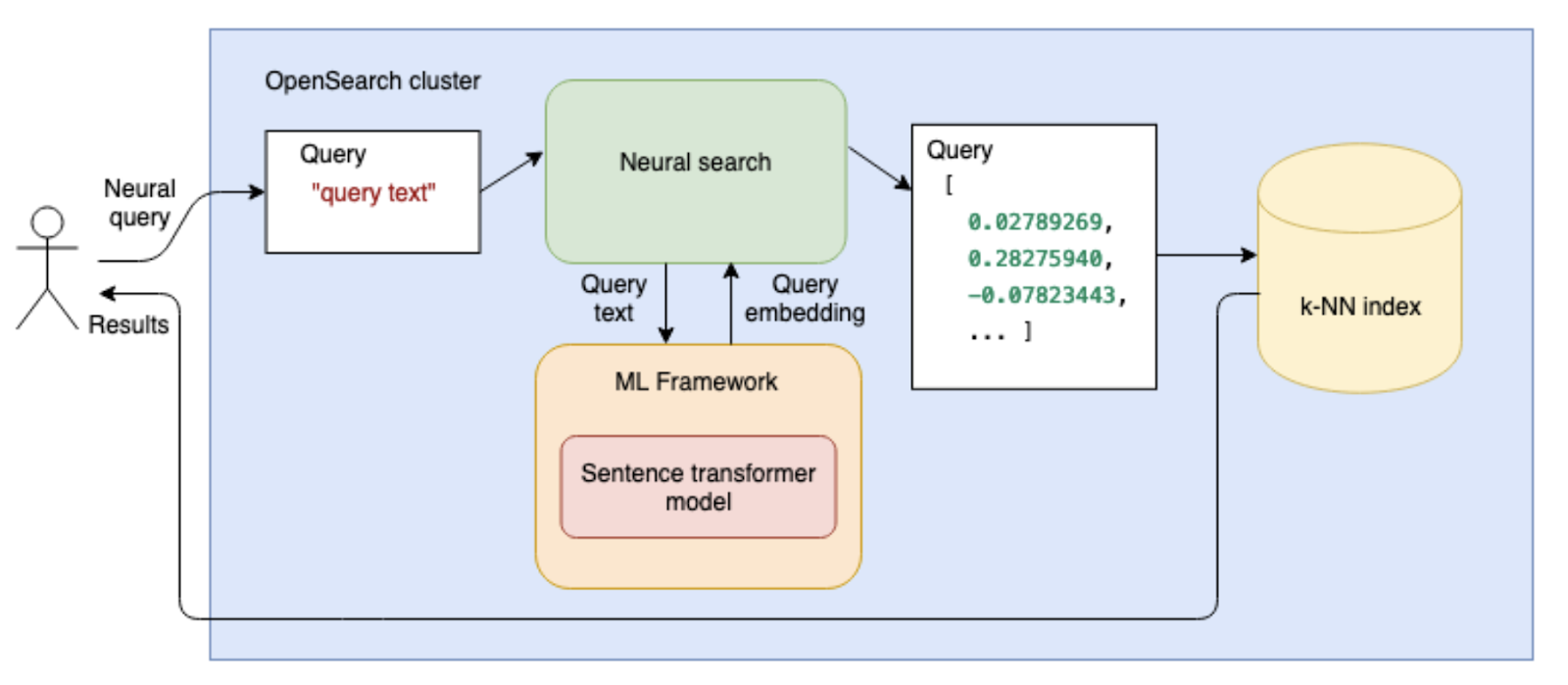
Understanding the Workflow
User Query → Neural Search
- The user submits a natural language query (e.g., “A time travel movie set in space”).
- This query is sent to OpenSearch as a neural search request.
Text-to-Vector Conversion (Sentence Transformer Model)
- Inside OpenSearch, the neural search module passes the query text to a pre-trained Sentence Transformer model (from Hugging Face or another ML framework).
- The model converts the query text into a dense vector representation (embedding).
- This embedding captures the semantic meaning of the query rather than just the words.
Querying the k-NN Index
- The generated query embedding is compared against the pre-stored embeddings in OpenSearch.
- OpenSearch uses k-Nearest Neighbors (k-NN) search to find the most similar embeddings in the dataset.
- The search is based on vector distance (e.g., cosine similarity or Euclidean distance) rather than exact keyword matching.
Retrieving and Ranking Results
- The k-NN index returns a ranked list of results, with the closest matches appearing at the top.
- Each result contains metadata (title, director, year, etc.), which helps in displaying meaningful search results.
Returning the Results to the User
- The search results are sent back to the user, displaying the most semantically similar movies based on their plot descriptions.
Why Does This Matter for Movie Search?
- In our case, plot descriptions are embedded into vector space, allowing OpenSearch to retrieve movies that are conceptually related to a query, even if they don’t contain the exact words.
- This approach ensures that users get more relevant search results by matching movie plots based on meaning rather than keywords.
- By leveraging sentence embeddings and k-NN search, we ensure that our movie search understands the context of queries, improving search accuracy and relevance.
Now that we understand why semantic search is powerful, let’s see how we can implement it in OpenSearch. We will start by setting up queries, running k-NN searches on embeddings, and retrieving the most relevant movies based on their plot descriptions.
Configuring Your Development Environment
Before we begin querying OpenSearch using neural search and k-NN retrieval, we need to set up our development environment with the same dependencies we installed in the previous post.
Installing Docker (Required for This Lesson)
Since we will be running OpenSearch locally using Docker, be sure Docker is installed on your system. If you haven’t installed it yet, follow this step-by-step guide: Getting Started with Docker for Machine Learning.
Installing Required Libraries
Below are the libraries we need for this tutorial, and you can install them using pip:
$ pip install opensearch-py==2.4.2 pandas==2.0.3 tqdm==4.66.1 pyarrow==14.0.2
Once the installations are complete and Docker is set up, you’re ready to proceed with indexing movie data in OpenSearch.
Need Help Configuring Your Development Environment?

All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code immediately on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Project Structure
Before running semantic search queries, let’s review the project directory structure. This will help us understand where our search scripts, queries, and configurations reside.
If you haven’t already set up the project from the previous post, you can download the source code from the tutorial’s “Downloads” section.
$ tree . . ├── data │ ├── queries_set_1.txt │ ├── queries_set_2.txt │ └── wiki_movie_plots.csv ├── deploy_and_index.py ├── find_similar_movies.py ├── pyimagesearch │ ├── __init__.py │ ├── config.py │ ├── index.json │ ├── ingest_pipeline.json │ ├── model_data.json │ ├── search_utils.py │ └── utils.py ├── results │ ├── search_results_set_1.csv │ └── search_results_set_2.csv └── run_opensearch.sh 4 directories, 15 files
📂 data/ — Query and Dataset Storage
wiki_movie_plots.csv: The dataset containing movie metadata and plot descriptions. This was indexed in OpenSearch in the previous post.queries_set_1.txtandqueries_set_2.txt: Predefined query sets for testing semantic search. These will be used to evaluate OpenSearch’s ability to retrieve relevant movies.
🔎 find_similar_movies.py — The Core Search Script
- Accepts a text query (e.g., “A sci-fi movie about space travel and time loops”).
- Converts the query into an embedding using OpenSearch’s deployed Sentence Transformer model.
- Runs a neural search on OpenSearch to find semantically similar movies.
- Returns movies ranked by similarity based on the k-NN search.
🛠 pyimagesearch/ — Utility Modules and Search Configurations
config.py: Stores OpenSearch connection details (host, port, authentication, index name, model ID).search_utils.py: Contains helper functions for performing neural search queries in OpenSearch.utils.py: General utility functions used in both indexing and search.
📊 results/ — Storing Search Outputs
search_results_set_1.csvandsearch_results_set_2.csv: Store search results for different test queries. These can be used for evaluation and comparison.
🚀 run_opensearch.sh — Running OpenSearch Locally
- A script to start OpenSearch using Docker for local testing before deploying to AWS.
Executing Semantic Search Queries in OpenSearch
Now that we have indexed movie metadata and embeddings in OpenSearch, it’s time to run actual search queries and retrieve results using neural search. Unlike traditional keyword-based search, semantic search leverages embeddings and k-Nearest Neighbors (k-NN) retrieval to find conceptually similar results based on meaning rather than exact word matches.
In this section, we will:
- Understand how OpenSearch processes a semantic search query.
- Construct and execute a neural search query in OpenSearch.
- Implement and analyze search results using Python scripts.
Understanding and Implementing Neural Search in OpenSearch
Before executing a search query, let’s first understand how OpenSearch performs neural search using embeddings.
When a user submits a query, OpenSearch follows these steps:
Convert Query into an Embedding
- The input text is processed using the same Sentence Transformer model used during indexing.
- The model generates a dense vector representation (embedding) for the query.
Perform k-Nearest Neighbors (k-NN) Search
- OpenSearch compares the query embedding against the pre-stored embeddings in the index.
- It uses vector similarity (e.g., cosine similarity) to retrieve the most similar movies.
Retrieve and Rank Results
- OpenSearch returns the top-k results (e.g., the 5 most similar movies).
- Each result includes metadata (e.g., title, director, year, and plot).
Return the Results to the User
- The response is structured in JSON format, ranking movies based on their similarity scores.
Running a Neural Search Query in OpenSearch
To perform semantic search, we need to construct a neural search query that OpenSearch can process.
Constructing a Neural Search Query
A neural search query in OpenSearch must contain the following:
- Query Text: The input text provided by the user.
- Model ID: Specifies the Sentence Transformer model for embedding generation.
- Vector Field (
plot_embedding): The field containing the precomputed embeddings. - k (Number of Neighbors): Defines how many similar results should be retrieved.
Example Neural Search Query
{
"query": {
"neural": {
"plot_embedding": {
"query_text": "A futuristic movie about space exploration",
"model_id": "abc123xyz",
"k": 5
}
}
},
"_source": {
"excludes": ["plot_embedding"]
}
}
Code Implementation: find_similar_movies.py
Now, let’s implement a Python script to execute the neural search query in OpenSearch.
import csv from pyimagesearch.config import model_id_path, queries_set_1_path from pyimagesearch.search_utils import perform_search from pyimagesearch.utils import load_queries
We start by importing the essential modules needed to execute semantic search queries in OpenSearch. The csv module is used for saving search results in a structured format. From pyimagesearch.config, we import model_id_path (which stores the registered model’s ID) and queries_set_1_path (a file containing predefined test queries).
The perform_search function, imported from search_utils, handles sending a neural search request to OpenSearch and retrieving results. Lastly, load_queries from utils reads the queries from a text file, ensuring that each query can be processed sequentially.
def perform_queries_and_save_results(model_id, queries_path):
# Load predefined queries
queries = load_queries(queries_path)
print(f"Loaded {len(queries)} queries.")
with open(csv_file, "w", newline="", encoding="utf-8") as file:
writer = csv(file)
writer.writerow(
["Query", "Director", "Title", "Year", "Wiki"]
)
The perform_queries_and_save_results function loads a set of predefined queries from a file using load_queries and prints the total number of queries loaded. It then defines an output CSV file, search_results.csv, where the retrieved search results will be stored.
The script opens this file in write mode and initializes a CSV writer, adding a header row with columns for query text, movie metadata (e.g., director, title, year), and Wiki link. This setup ensures that each query’s results are systematically stored for further analysis.
# Loop through each query
for query in queries:
print(f"Searching for: {query}")
response = perform_search(query)
for hit in response["hits"]["hits"]:
match_score = hit["_score"]
year = hit["_source"].get("year", "")
wiki = hit["_source"].get("wiki", "")
writer.writerow([query, match_score, plot_text, director, title, year, wiki])
print(f"Completed search for: {query}")
print("All results have been saved to:", csv_file)
This code loops through each query, prints the query being processed, and calls perform_search to retrieve semantically similar movies from OpenSearch.
For each result (hit), it extracts relevant fields (e.g., match score, plot text, director, title, year, and Wiki link). These details are then written to the CSV (Comma Separated Values) file. Once a query’s results are processed, a confirmation message is printed. Finally, after all queries are completed, the script prints a message indicating that the results have been successfully saved.
if __name__ == "__main__":
with open(model_id_path, "r") as file:
model_id = file.read().strip()
print(f"Model ID: {model_id}")
perform_queries_and_save_results(model_id, queries_set_1_path)
Finally, this last part of the code executes the script when run directly. It reads the model ID from model_id_path, trims any extra spaces, and displays it. Then, it invokes perform_queries_and_save_results, supplying the model ID and the predefined queries file (queries_set_1_path). This initiates the search process, retrieving relevant results and saving them to a file.
Understanding the perform_search Function
This function is responsible for constructing and sending the neural search request to OpenSearch.
import requests
import urllib3
from pyimagesearch import config
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
def perform_search(query_text, model_id):
"""
Perform a search operation using the neural query on the OpenSearch cluster.
Args:
query_text: The text string you want to search for.
model_id: The ID of the model used for semantic search.
Returns:
response: JSON response from the OpenSearch server.
"""
# forming the search body
search_body = {
"query": {
"neural": {
"plot_embedding": {
"query_text": query_text,
"model_id": model_id,
"k": 5,
}
}
},
"_source": {
"excludes": ["plot_embedding"] # exclude plot_embedding from the results
},
}
# sending the search request to OpenSearch and returning the response
response = requests.post(
config.search_url, json=search_body, auth=config.auth, verify=False
)
return response.json()
The above code defines the perform_search function, which sends a neural search query to OpenSearch to retrieve semantically similar movie plots.
It begins by importing necessary libraries, including requests for making HTTP requests and urllib3 to handle SSL (Secure Sockets Layer) warnings. The function takes two arguments: query_text, which is the user’s input query, and model_id, which specifies the pre-trained Sentence Transformer model used to generate embeddings.
The search_body dictionary constructs the request payload, specifying that the query should be processed using the neural search method on the plot_embedding field. OpenSearch uses the provided model to convert the query into an embedding and retrieves the top-5 (k=5) most similar results based on vector similarity.
The _source field is configured to exclude embeddings from the response to keep it lightweight.
The function then sends a POST request to OpenSearch using the configured search_url, passing authentication details from the config file.
Finally, the function returns the JSON response, which contains the ranked search results based on semantic similarity.
Example Search Query and Response in OpenSearch
When executing a neural search, OpenSearch returns a JSON response similar to the one below:
{
"hits": {
"total": 3,
"hits": [
{
"_score": 0.98,
"_source": {
"title": "Interstellar",
"plot_text": "A team of astronauts travel through a wormhole in search of a new home for humanity.",
"director": "Christopher Nolan",
"year": 2014
}
},
{
"_score": 0.92,
"_source": {
"title": "Gravity",
"plot_text": "Two astronauts are stranded in space after the destruction of their shuttle.",
"director": "Alfonso Cuarón",
"year": 2013
}
}
]
}
}
The above JSON response from OpenSearch shows the results of a neural search query performed on the indexed movie dataset. The hits field contains a total of three matching results, ranked by their similarity score (_score). The first result, "Interstellar", has the highest score (0.98), indicating that its plot is the closest semantic match to the search query.
The second result, "Gravity", follows with a similarity score of 0.92, showing that it is also relevant but slightly less similar than the first. Each result is structured under the _source field, containing key metadata (e.g., the movie title, plot description, director, and release year).
OpenSearch ranks these results based on vector similarity rather than keyword matching, ensuring that the retrieved movies align with the search intent even if the exact words from the query are not present.
Running and Evaluating Search Queries
To execute the script:
$ python find_similar_movies.py
When executing find_similar_movies.py, you will see an output similar to this in the terminal:
Model ID: abc123xyz Loaded 5 queries. Searching for: "A futuristic movie about space exploration" Completed search for: "A futuristic movie about space exploration" Results saved to search_results.csv
This output confirms that the search execution was successful and provides key details about the process:
Model ID: abc123xyz- This shows that OpenSearch is using the correct deployed model for embedding generation.
- The model ID (
abc123xyz) was previously registered when we indexed data in OpenSearch.
Loaded 5 queries- The script successfully read 5 predefined queries from the
queries_set_1.txtfile. - These queries will be sequentially processed in OpenSearch.
- The script successfully read 5 predefined queries from the
Searching for: "A futuristic movie about space exploration"- The first query is being processed.
- The query text is converted into an embedding, which OpenSearch will use for k-NN retrieval.
Completed search for: "A futuristic movie about space exploration"- OpenSearch has successfully retrieved semantically similar movies.
- The search results are now ranked and prepared for saving.
Results saved to search_results.csv- The retrieved movie results (title, director, year, similarity score, etc.) are stored in
search_results.csv. - This CSV file can be used for further evaluation and analysis.
- The retrieved movie results (title, director, year, similarity score, etc.) are stored in
AWS Users: Adapting This Setup for OpenSearch on AWS
If you are using AWS OpenSearch instead of running OpenSearch locally with Docker, you need to make the following changes before indexing data:
- Update the OpenSearch URL: Replace
localhost:9200with your AWS OpenSearch domain. - Register the Sentence Transformer model in AWS OpenSearch: AWS users must ensure that OpenSearch can access the model before indexing.
- If model registration fails, try hosting the model in S3: AWS OpenSearch may not allow model registration via URL, so storing the model in S3 and granting OpenSearch access could be required.
- Ensure IAM (Identity and Access Management) permissions are set up: AWS OpenSearch must have the necessary permissions to access the hosted model and perform ML-based text embedding.
To switch from local OpenSearch to AWS OpenSearch, update the OpenSearch client in Python like this:
from opensearchpy import OpenSearch
# AWS OpenSearch URL
client = OpenSearch(
hosts=["https://your-aws-opensearch-domain"],
http_auth=("your-username", "your-password"),
use_ssl=True,
verify_certs=True
)
For now, AWS users can follow the same steps as in this post with these adjustments. A dedicated AWS OpenSearch deployment guide will be published separately.
What's next? We recommend PyImageSearch University.
120+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 120+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 94+ Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this final post of the series, we explored how to perform semantic search in OpenSearch, building on our previous work of setting up OpenSearch, indexing movie metadata, and generating embeddings. We began by explaining why semantic search is more effective than traditional keyword-based search, highlighting how it retrieves results based on meaning rather than exact word matches. We also covered how OpenSearch performs k-NN search on vector embeddings to find similar content efficiently.
We then moved on to constructing and executing a neural search query using OpenSearch’s neural search feature. Through the find_similar_movies.py script, we automated the process of retrieving semantically similar movies based on their plot descriptions. A detailed breakdown of the perform_search function demonstrated how OpenSearch processes search requests, ranks results, and returns the most relevant matches. Finally, we executed test queries, analyzed OpenSearch responses, and saved the results for further evaluation.
This concludes our series on OpenSearch for Semantic Search. While we covered setting up AWS OpenSearch Service in the first post, we primarily used local OpenSearch with Docker for indexing and querying. As a next step, we encourage readers to try deploying indexing and querying on AWS OpenSearch, modifying the setup to accommodate hosted models and authentication mechanisms. A future post may dive deeper into AWS OpenSearch indexing and querying best practices.
Citation Information
Singh, V. “Build a Search Engine: Semantic Search System Using OpenSearch,” PyImageSearch, P. Chugh, S. Huot, G. Kudriavtsev, A. Sharma, and P. Thakur, eds., 2025, https://pyimg.co/h0lxg
@incollection{Singh_2025_build-search-engine-semantic-search-system-using-opensearch,
author = {Vikram Singh},
title = {{Build a Search Engine: Semantic Search System Using OpenSearch}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Georgii Kudriavtsev and Aditya Sharma and Piyush Thakur},
year = {2025},
url = {https://pyimg.co/h0lxg},
}
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.