
In today’s tutorial, we will be looking at image segmentation and building our own segmentation model from scratch, based on the popular U-Net architecture.
This lesson is the last of a 3-part series on Advanced PyTorch Techniques:
- Training a DCGAN in PyTorch (the tutorial 2 weeks ago)
- Training an Object Detector from Scratch in PyTorch (last week’s lesson)
- U-Net: Training Image Segmentation Models in PyTorch (today’s tutorial)
The computer vision community has devised various tasks, such as image classification, object detection, localization, etc., for understanding images and their content. These tasks give us a high-level understanding of the object class and its location in the image.
In Image Segmentation, we go a step further and ask our model to classify each pixel in our image to the object category it represents. This can be viewed as pixel-level image classification and is a much harder task than simple image classification, detection, or localization. Our model must automatically determine all objects and their precise location and boundaries at a pixel level in the image.
Thus image segmentation provides an intricate understanding of the image and is widely used in medical imaging, autonomous driving, robotic manipulation, etc.
To learn how to train a U-Net-based segmentation model in PyTorch, just keep reading.
U-Net: Training Image Segmentation Models in PyTorch
Throughout this tutorial, we will be looking at image segmentation and building and training a segmentation model in PyTorch. We will focus on a very successful architecture, U-Net, which was originally proposed for medical image segmentation. Furthermore, we will understand the salient features of the U-Net model, which make it an apt choice for the task of image segmentation.
Specifically, we will discuss the following, in detail, in this tutorial:
- The architectural details of U-Net that make it a powerful segmentation model
- Creating a custom PyTorch Dataset for our image segmentation task
- Training the U-Net segmentation model from scratch
- Making predictions on novel images with our trained U-Net model
U-Net Architecture Overview
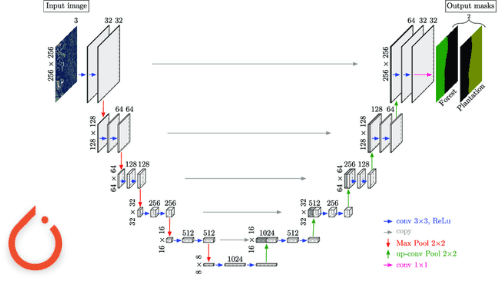
The U-Net architecture (see Figure 1) follows an encoder-decoder cascade structure, where the encoder gradually compresses information into a lower-dimensional representation. Then the decoder decodes this information back to the original image dimension. Owing to this, the architecture gets an overall U-shape, which leads to the name U-Net.
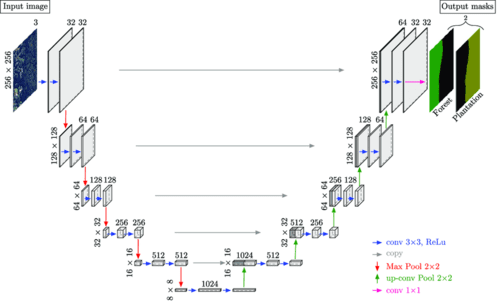
In addition to this, one of the salient features of the U-Net architecture is the skip connections (shown with grey arrows in Figure 1), which enable the flow of information from the encoder side to the decoder side, enabling the model to make better predictions.
Specifically, as we go deeper, the encoder processes information at higher levels of abstraction. This simply means that at the initial layers, the feature maps of the encoder capture low-level details about object texture and edges, and as we gradually go deeper, the features capture high-level information about object shapes and categories.
It is worth noting that to segment objects in an image, both low-level and high-level information is important. For example, a change in texture between objects and edge information can help determine the boundaries of various objects. On the other hand, high-level information about the class to which an object shape belongs can help segment corresponding pixels to correct object classes they represent.
Thus, to use both these pieces of information during predictions, the U-Net architecture implements skip connections between the encoder and decoder. This enables us to take intermediate feature map information from various depths on the encoder side and concatenate it at the decoder side to process and facilitate better predictions.
We will look at the U-Net model in further detail and build it from scratch in PyTorch later in this tutorial.
Our TGS Salt Segmentation Dataset
For this tutorial, we will use the TGS Salt Segmentation dataset. The dataset was introduced as part of the TGS Salt Identification Challenge on Kaggle.
Practically, it is difficult to accurately identify the location of salt deposits from images even with the help of human experts. Therefore, the challenge required participants to help experts precisely identify the locations of salt deposits from seismic images of the earth sub-surface. This is practically important since incorrect estimates of salt presence can lead companies to set up drillers at the wrong locations for mining, leading to a waste of time and resources.
We use a sub-part of this dataset which comprises 4000 images of size 101×101 pixels, taken from various locations on earth. Here, each pixel corresponds to either salt deposit or sediment. In addition to images, we are also provided with the ground-truth pixel-level segmentation masks of the same dimension as the image (see Figure 2).

The white pixels in the masks represent salt deposits, and the black pixels represent sediment. We aim to correctly predict the pixels that correspond to salt deposits in the images. Thus, we have a binary classification problem where we have to classify each pixel into one of the two classes, Class 1: Salt or Class 2: Not Salt (or, in other words, sediment).
Configuring Your Development Environment
To follow this guide, you need to have the PyTorch deep learning library, matplotlib, OpenCV, imutils, scikit-learn, and tqdm packages installed on your system.
Luckily, these packages are extremely easy to install using pip:
$ pip install torch torchvision $ pip install matplotlib $ pip install opencv-contrib-python $ pip install imutils $ pip install scikit-learn $ pip install tqdm
If you need help configuring your development environment for PyTorch, I highly recommend that you read the PyTorch documentation — PyTorch’s documentation is comprehensive and will have you up and running quickly.
Having Problems Configuring Your Development Environment?
All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code right now on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides that are pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Project Structure
We first need to review our project directory structure.
Start by accessing the “Downloads” section of this tutorial to retrieve the source code and example images.
From there, take a look at the directory structure:
. ├── dataset │ └── train ├── output ├── pyimagesearch │ ├── config.py │ ├── dataset.py │ └── model.py ├── predict.py └── train.py
The dataset folder stores the TGS Salt Segmentation dataset we will use for training our segmentation model.
Furthermore, we will be storing our trained model and training loss plots in the output folder.
The config.py file in the pyimagesearch folder stores our code’s parameters, initial settings, and configurations.
On the other hand, the dataset.py file consists of our custom segmentation dataset class, and the model.py file contains the definition of our U-Net model.
Finally, our model training and prediction codes are defined in train.py and predict.py files, respectively.
Creating Our Configuration File
We start by discussing the config.py file, which stores configurations and parameter settings used in the tutorial.
# import the necessary packages
import torch
import os
# base path of the dataset
DATASET_PATH = os.path.join("dataset", "train")
# define the path to the images and masks dataset
IMAGE_DATASET_PATH = os.path.join(DATASET_PATH, "images")
MASK_DATASET_PATH = os.path.join(DATASET_PATH, "masks")
# define the test split
TEST_SPLIT = 0.15
# determine the device to be used for training and evaluation
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# determine if we will be pinning memory during data loading
PIN_MEMORY = True if DEVICE == "cuda" else False
We start by importing the necessary packages on Lines 2 and 3. Then, we define the path for our dataset (i.e., DATASET_PATH) on Line 6 and the paths for images and masks within the dataset folder (i.e., IMAGE_DATASET_PATH and MASK_DATASET_PATH) on Lines 9 and 10.
On Line 13, we define the fraction of the dataset we will keep aside for the test set. Then, on Line 16, we define the DEVICE parameter, which determines based on availability, whether we will be using a GPU or CPU for training our segmentation model. In this case, we are using a CUDA-enabled GPU device, and we set the PIN_MEMORY parameter to True on Line 19.
# define the number of channels in the input, number of classes, # and number of levels in the U-Net model NUM_CHANNELS = 1 NUM_CLASSES = 1 NUM_LEVELS = 3 # initialize learning rate, number of epochs to train for, and the # batch size INIT_LR = 0.001 NUM_EPOCHS = 40 BATCH_SIZE = 64 # define the input image dimensions INPUT_IMAGE_WIDTH = 128 INPUT_IMAGE_HEIGHT = 128 # define threshold to filter weak predictions THRESHOLD = 0.5 # define the path to the base output directory BASE_OUTPUT = "output" # define the path to the output serialized model, model training # plot, and testing image paths MODEL_PATH = os.path.join(BASE_OUTPUT, "unet_tgs_salt.pth") PLOT_PATH = os.path.sep.join([BASE_OUTPUT, "plot.png"]) TEST_PATHS = os.path.sep.join([BASE_OUTPUT, "test_paths.txt"])
Next, we define the NUM_CHANNELS, NUM_CLASSES, and NUM_LEVELS parameters on Lines 23-25, which we will discuss in more detail later in the tutorial. Finally, on Lines 29-31, we define the training parameters such as initial learning rate (i.e., INIT_LR), the total number of epochs (i.e., NUM_EPOCHS), and batch size (i.e., BATCH_SIZE).
On Lines 34 and 35, we also define input image dimensions to which our images should be resized for our model to process them. We further define a threshold parameter on Line 38, which will later help us classify the pixels into one of the two classes in our binary classification-based segmentation task.
Finally, we define the path to our output folder (i.e., BASE_OUTPUT) on Line 41 and the corresponding paths to the trained model weights, training plots, and test images within the output folder on Lines 45-47.
Creating Our Custom Segmentation Dataset Class
Now that we have defined our initial configurations and parameters, we are ready to understand the custom dataset class we will be using for our segmentation dataset.
Let’s open the dataset.py file from the pyimagesearch folder in our project directory.
# import the necessary packages from torch.utils.data import Dataset import cv2 class SegmentationDataset(Dataset): def __init__(self, imagePaths, maskPaths, transforms): # store the image and mask filepaths, and augmentation # transforms self.imagePaths = imagePaths self.maskPaths = maskPaths self.transforms = transforms def __len__(self): # return the number of total samples contained in the dataset return len(self.imagePaths) def __getitem__(self, idx): # grab the image path from the current index imagePath = self.imagePaths[idx] # load the image from disk, swap its channels from BGR to RGB, # and read the associated mask from disk in grayscale mode image = cv2.imread(imagePath) image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) mask = cv2.imread(self.maskPaths[idx], 0) # check to see if we are applying any transformations if self.transforms is not None: # apply the transformations to both image and its mask image = self.transforms(image) mask = self.transforms(mask) # return a tuple of the image and its mask return (image, mask)
We begin by importing the Dataset class from the torch.utils.data module on Line 2. This is important since all PyTorch datasets must inherit from this base dataset class. Furthermore, on Line 3, we import the OpenCV package, which will enable us to use its image handling functionalities.
We are now ready to define our own custom segmentation dataset. Each PyTorch dataset is required to inherit from Dataset class (Line 5) and should have a __len__ (Lines 13-15) and a __getitem__ (Lines 17-34) method. We discuss each of these methods below.
We start by defining our initializer constructor, that is, the __init__ method on Lines 6-11. The method takes as input the list of image paths (i.e., imagePaths) of our dataset, the corresponding ground-truth masks (i.e., maskPaths), and the set of transformations (i.e., transforms) we want to apply to our input images (Line 6).
On Lines 9-11, we initialize the attributes of our SegmentationDataset class with the parameters input to the __init__ constructor.
Next, we define the __len__ method, which returns the total number of image paths in our dataset, as shown on Line 15.
The task of the __getitem__ method is to take an index as input (Line 17) and returns the corresponding sample from the dataset. On Line 19, we simply grab the image path at the idx index in our list of input image paths. Then, we load the image using OpenCV (Line 23). By default, OpenCV loads an image in the BGR format, which we convert to the RGB format as shown on Line 24. We also load the corresponding ground-truth segmentation mask in grayscale mode on Line 25.
Finally, we check for input transformations that we want to apply to our dataset images (Line 28) and transform both the image and mask with the required transforms on Lines 30 and 31, respectively. This is important since we want our image and ground-truth mask to correspond and have the same dimension. On Line 34, we return the tuple containing the image and its corresponding mask (i.e., (image, mask)) as shown.
This completes the definition of our custom Segmentation dataset. Next, we will discuss the implementation of the U-Net architecture.
Building Our U-Net Model in PyTorch
It is time to look at our U-Net model architecture in detail and build it from scratch in PyTorch.
We open our model.py file from the pyimagesearch folder in our project directory and get started.
# import the necessary packages from . import config from torch.nn import ConvTranspose2d from torch.nn import Conv2d from torch.nn import MaxPool2d from torch.nn import Module from torch.nn import ModuleList from torch.nn import ReLU from torchvision.transforms import CenterCrop from torch.nn import functional as F import torch
On Lines 2-11, we import the necessary layers, modules, and activation functions from PyTorch, which we will use to build our model.
Overall, our U-Net model will consist of an Encoder class and a Decoder class. The encoder will gradually reduce the spatial dimension to compress information. Furthermore, it will increase the number of channels, that is, the number of feature maps at each stage, enabling our model to capture different details or features in our image. On the other hand, the decoder will take the final encoder representation and gradually increase the spatial dimension and reduce the number of channels to finally output a segmentation mask of the same spatial dimension as the input image.
Next, we define a Block module as the building unit of our encoder and decoder architecture. It is worth noting that all models or model sub-parts that we define are required to inherit from the PyTorch Module class, which is the parent class in PyTorch for all neural network modules.
class Block(Module): def __init__(self, inChannels, outChannels): super().__init__() # store the convolution and RELU layers self.conv1 = Conv2d(inChannels, outChannels, 3) self.relu = ReLU() self.conv2 = Conv2d(outChannels, outChannels, 3) def forward(self, x): # apply CONV => RELU => CONV block to the inputs and return it return self.conv2(self.relu(self.conv1(x)))
We start by defining our Block class on Lines 13-23. The function of this module is to take an input feature map with the inChannels number of channels, apply two convolution operations with a ReLU activation between them and return the output feature map with the outChannels channels.
The __init__ constructor takes as input two parameters, inChannels and outChannels (Line 14), which determine the number of channels in the input feature map and the output feature map, respectively.
We initialize the two convolution layers (i.e., self.conv1 and self.conv2) and a ReLU activation on Lines 17-19. On Lines 21-23, we define the forward function which takes as input our feature map x, applies self.conv1 => self.relu => self.conv2 sequence of operations and returns the output feature map.
class Encoder(Module): def __init__(self, channels=(3, 16, 32, 64)): super().__init__() # store the encoder blocks and maxpooling layer self.encBlocks = ModuleList( [Block(channels[i], channels[i + 1]) for i in range(len(channels) - 1)]) self.pool = MaxPool2d(2) def forward(self, x): # initialize an empty list to store the intermediate outputs blockOutputs = [] # loop through the encoder blocks for block in self.encBlocks: # pass the inputs through the current encoder block, store # the outputs, and then apply maxpooling on the output x = block(x) blockOutputs.append(x) x = self.pool(x) # return the list containing the intermediate outputs return blockOutputs
Next, we define our Encoder class on Lines 25-47. The class constructor (i.e., the __init__ method) takes as input a tuple (i.e., channels) of channel dimensions (Line 26). Note that the first value denotes the number of channels in our input image, and the subsequent numbers gradually double the channel dimension.
We start by initializing a list of blocks for the encoder (i.e., self.encBlocks) with the help of PyTorch’s ModuleList functionality on Lines 29-31. Each Block takes the input channels of the previous block and doubles the channels in the output feature map. We also initialize a MaxPool2d() layer, which reduces the spatial dimension (i.e., height and width) of the feature maps by a factor of 2.
Finally, we define the forward function for our encoder on Lines 34-47. The function takes as input an image x as shown on Line 34. On Line 36, we initialize an empty blockOutputs list, storing the intermediate outputs from the blocks of our encoder. Note that this will enable us to later pass these outputs to that decoder where they can be processed with the decoder feature maps.
On Lines 39-44, we loop through each block in our encoder, process the input feature map through the block (Line 42), and add the output of the block to our blockOutputs list. We then apply the max pool operation on our block output (Line 44). This is done for each block in the encoder.
Finally, we return our blockOutputs list on Line 47.
class Decoder(Module): def __init__(self, channels=(64, 32, 16)): super().__init__() # initialize the number of channels, upsampler blocks, and # decoder blocks self.channels = channels self.upconvs = ModuleList( [ConvTranspose2d(channels[i], channels[i + 1], 2, 2) for i in range(len(channels) - 1)]) self.dec_blocks = ModuleList( [Block(channels[i], channels[i + 1]) for i in range(len(channels) - 1)]) def forward(self, x, encFeatures): # loop through the number of channels for i in range(len(self.channels) - 1): # pass the inputs through the upsampler blocks x = self.upconvs[i](x) # crop the current features from the encoder blocks, # concatenate them with the current upsampled features, # and pass the concatenated output through the current # decoder block encFeat = self.crop(encFeatures[i], x) x = torch.cat([x, encFeat], dim=1) x = self.dec_blocks[i](x) # return the final decoder output return x def crop(self, encFeatures, x): # grab the dimensions of the inputs, and crop the encoder # features to match the dimensions (_, _, H, W) = x.shape encFeatures = CenterCrop([H, W])(encFeatures) # return the cropped features return encFeatures
Now we define our Decoder class (Lines 50-87). Similar to the encoder definition, the decoder __init__ method takes as input a tuple (i.e., channels) of channel dimensions (Line 51). Note that the difference here, when compared with the encoder side, is that the channels gradually decrease by a factor of 2 instead of increasing.
We initialize the number of channels on Line 55. Furthermore, on Lines 56-58, we define a list of upsampling blocks (i.e., self.upconvs) that use the ConvTranspose2d layer to upsample the spatial dimension (i.e., height and width) of the feature maps by a factor of 2. In addition, the layer also reduces the number of channels by a factor of 2.
Finally, we initialize a list of blocks for the decoder (i.e., self.dec_Blocks) similar to that on the encoder side.
On Lines 63-75, we define the forward function, which takes as input our feature map x and the list of intermediate outputs from the encoder (i.e., encFeatures). Starting on Line 65, we loop through the number of channels and perform the following operations:
- First, we upsample the input to our decoder (i.e.,
x) by passing it through our i-th upsampling block (Line 67) - Since we have to concatenate (along the channel dimension) the i-th intermediate feature map from the encoder (i.e.,
encFeatures[i]) with our current outputxfrom the upsampling block, we need to ensure that the spatial dimensions ofencFeatures[i]andxmatch. To accomplish this, we use ourcropfunction on Line 73. - Next, we concatenate our cropped encoder feature maps (i.e.,
encFeat) with our current upsampled feature mapx, along the channel dimension on Line 74 - Finally, we pass the concatenated output through our i-th decoder block (Line 75)
After the completion of the loop, we return the final decoder output on Line 78.
On Lines 80-87, we define our crop function which takes an intermediate feature map from the encoder (i.e., encFeatures) and a feature map output from the decoder (i.e., x) and spatially crops the former to the dimension of the latter.
To do this, we first grab the spatial dimensions of x (i.e., height H and width W) on Line 83. Then, we crop encFeatures to the spatial dimension [H, W] using the CenterCrop function (Line 84) and finally return the cropped output on Line 87.
Now that we have defined the sub-modules that make up our U-Net model, we are ready to build our U-Net model class.
class UNet(Module): def __init__(self, encChannels=(3, 16, 32, 64), decChannels=(64, 32, 16), nbClasses=1, retainDim=True, outSize=(config.INPUT_IMAGE_HEIGHT, config.INPUT_IMAGE_WIDTH)): super().__init__() # initialize the encoder and decoder self.encoder = Encoder(encChannels) self.decoder = Decoder(decChannels) # initialize the regression head and store the class variables self.head = Conv2d(decChannels[-1], nbClasses, 1) self.retainDim = retainDim self.outSize = outSize
We start by defining the __init__ constructor method (Lines 91-103). It takes the following parameters as input:
encChannels: The tuple defines the gradual increase in channel dimension as our input passes through the encoder. We start with 3 channels (i.e., RGB) and subsequently double the number of channels.decChannels: The tuple defines the gradual decrease in channel dimension as our input passes through the decoder. We reduce the channels by a factor of 2 at every step.nbClasses: This defines the number of segmentation classes where we have to classify each pixel. This usually corresponds to the number of channels in our output segmentation map, where we have one channel for each class.- Since we are working with two classes (i.e., binary classification), we keep a single channel and use thresholding for classification, as we will discuss later.
retainDim: This indicates whether we want to retain the original output dimension.outSize: This determines the spatial dimensions of the output segmentation map. We set this to the same dimension as our input image (i.e., (config.INPUT_IMAGE_HEIGHT, config.INPUT_IMAGE_WIDTH)).
On Lines 97 and 98, we initialize our encoder and decoder networks. Furthermore, we initialize a convolution head through which will later take our decoder output as input and output our segmentation map with nbClasses number of channels (Line 101).
We also initialize the self.retainDim and self.outSize attributes on Lines 102 and 103.
def forward(self, x): # grab the features from the encoder encFeatures = self.encoder(x) # pass the encoder features through decoder making sure that # their dimensions are suited for concatenation decFeatures = self.decoder(encFeatures[::-1][0], encFeatures[::-1][1:]) # pass the decoder features through the regression head to # obtain the segmentation mask map = self.head(decFeatures) # check to see if we are retaining the original output # dimensions and if so, then resize the output to match them if self.retainDim: map = F.interpolate(map, self.outSize) # return the segmentation map return map
Finally, we are ready to discuss our U-Net model’s forward function (Lines 105-124).
We begin by passing our input x through the encoder. This outputs the list of encoder feature maps (i.e., encFeatures) as shown on Line 107. Note that the encFeatures list contains all the feature maps starting from the first encoder block output to the last, as discussed previously. Therefore, we can reverse the order of feature maps in this list: encFeatures[::-1].
Now the encFeatures[::-1] list contains the feature map outputs in reverse order (i.e., from the last to the first encoder block). Note that this is important since, on the decoder side, we will be utilizing the encoder feature maps starting from the last encoder block output to the first.
Next, we pass the output of the final encoder block (i.e., encFeatures[::-1][0]) and the feature map outputs of all intermediate encoder blocks (i.e., encFeatures[::-1][1:]) to the decoder on Line 111. The output of the decoder is stored as decFeatures.
We pass the decoder output to our convolution head (Line 116) to obtain the segmentation mask.
Finally, we check if the self.retainDim attribute is True (Line 120). If yes, we interpolate the final segmentation map to the output size defined by self.outSize (Line 121). We return our final segmentation map on Line 124.
This completes the implementation of our U-Net model. Next, we will look at the training procedure for our segmentation pipeline.
Training Our Segmentation Model
Now that we have implemented our dataset class and model architecture, we are ready to construct and train our segmentation pipeline in PyTorch. Let’s open the train.py file from our project directory.
Specifically, we will be looking at the following in detail:
- Structuring the data-loading pipeline
- Initializing the model and training parameters
- Defining the training loop
- Visualizing the training and test loss curves
# USAGE # python train.py # import the necessary packages from pyimagesearch.dataset import SegmentationDataset from pyimagesearch.model import UNet from pyimagesearch import config from torch.nn import BCEWithLogitsLoss from torch.optim import Adam from torch.utils.data import DataLoader from sklearn.model_selection import train_test_split from torchvision import transforms from imutils import paths from tqdm import tqdm import matplotlib.pyplot as plt import torch import time import os
We begin by importing our custom-defined SegmentationDataset class and the UNet model on Lines 5 and 6. Next, we import our config file on Line 7.
Since our salt segmentation task is a pixel-level binary classification problem, we will be using binary cross-entropy loss to train our model. On Line 8, we import the binary cross-entropy loss function (i.e., BCEWithLogitsLoss) from the PyTorch nn module. In addition to this, we import the Adam optimizer from the PyTorch optim module, which we will be using to train our network (Line 9).
Next, on Line 11, we import the in-built train_test_split function from the sklearn library, enabling us to split our dataset into training and testing sets. Furthermore, we import the transforms module from torchvision on Line 12 to apply image transformations on our input images.
Finally, we import other useful packages for handling our file system, keeping track of progress during training, timing our training process, and plotting loss curves on Lines 13-18.
Once we have imported all necessary packages, we will load our data and structure the data loading pipeline.
# load the image and mask filepaths in a sorted manner
imagePaths = sorted(list(paths.list_images(config.IMAGE_DATASET_PATH)))
maskPaths = sorted(list(paths.list_images(config.MASK_DATASET_PATH)))
# partition the data into training and testing splits using 85% of
# the data for training and the remaining 15% for testing
split = train_test_split(imagePaths, maskPaths,
test_size=config.TEST_SPLIT, random_state=42)
# unpack the data split
(trainImages, testImages) = split[:2]
(trainMasks, testMasks) = split[2:]
# write the testing image paths to disk so that we can use then
# when evaluating/testing our model
print("[INFO] saving testing image paths...")
f = open(config.TEST_PATHS, "w")
f.write("\n".join(testImages))
f.close()
On Lines 21 and 22, we first define two lists (i.e., imagePaths and maskPaths) that store the paths of all images and their corresponding segmentation masks, respectively.
We then partition our dataset into a training and test set with the help of scikit-learn’s train_test_split on Line 26. Note that this function takes as input a sequence of lists (here, imagePaths and maskPaths) and simultaneously returns the training and test set images and corresponding training and test set masks which we unpack on Lines 30 and 31.
We store the paths in the testImages list in the test folder path defined by config.TEST_PATHS on Line 36.
Now, we are ready to set up our data loading pipeline.
# define transformations
transforms = transforms.Compose([transforms.ToPILImage(),
transforms.Resize((config.INPUT_IMAGE_HEIGHT,
config.INPUT_IMAGE_WIDTH)),
transforms.ToTensor()])
# create the train and test datasets
trainDS = SegmentationDataset(imagePaths=trainImages, maskPaths=trainMasks,
transforms=transforms)
testDS = SegmentationDataset(imagePaths=testImages, maskPaths=testMasks,
transforms=transforms)
print(f"[INFO] found {len(trainDS)} examples in the training set...")
print(f"[INFO] found {len(testDS)} examples in the test set...")
# create the training and test data loaders
trainLoader = DataLoader(trainDS, shuffle=True,
batch_size=config.BATCH_SIZE, pin_memory=config.PIN_MEMORY,
num_workers=os.cpu_count())
testLoader = DataLoader(testDS, shuffle=False,
batch_size=config.BATCH_SIZE, pin_memory=config.PIN_MEMORY,
num_workers=os.cpu_count())
We first define the transformations that we want to apply while loading our input images and consolidate them with the help of the Compose function on Lines 41-44. Our transformations include:
ToPILImage(): it enables us to convert our input images to PIL image format. Note that this is necessary since we used OpenCV to load images in our custom dataset, but PyTorch expects the input image samples to be in PIL format.Resize(): allows us to resize our images to a particular input dimension (i.e.,config.INPUT_IMAGE_HEIGHT,config.INPUT_IMAGE_WIDTH) that our model can acceptToTensor(): enables us to convert input images to PyTorch tensors and convert the input PIL Image, which is originally in the range from[0, 255], to[0, 1].
Finally, we pass the train and test images and corresponding masks to our custom SegmentationDataset to create the training dataset (i.e., trainDS) and test dataset (i.e., testDS) on Lines 47-50. Note that we can simply pass the transforms defined on Line 41 to our custom PyTorch dataset to apply these transformations while loading the images automatically.
We can now print the number of samples in trainDS and testDS with the help of the len() method, as shown in Lines 51 and 52.
On Lines 55-60, we create our training dataloader (i.e., trainLoader) and test dataloader (i.e., testLoader) directly by passing our train dataset and test dataset to the Pytorch DataLoader class. We keep the shuffle parameter True in the train dataloader since we want samples from all classes to be uniformly present in a batch which is important for optimal learning and convergence of batch gradient-based optimization approaches.
Now that we have structured and defined our data loading pipeline, we will initialize our U-Net model and the training parameters.
# initialize our UNet model
unet = UNet().to(config.DEVICE)
# initialize loss function and optimizer
lossFunc = BCEWithLogitsLoss()
opt = Adam(unet.parameters(), lr=config.INIT_LR)
# calculate steps per epoch for training and test set
trainSteps = len(trainDS) // config.BATCH_SIZE
testSteps = len(testDS) // config.BATCH_SIZE
# initialize a dictionary to store training history
H = {"train_loss": [], "test_loss": []}
We start by defining our UNet() model on Line 63. Note that the to() function takes as input our config.DEVICE and registers our model and its parameters on the device mentioned.
On Lines 66 and 67, we define our loss function and optimizer, which we will use to train our segmentation model. The Adam optimizer class takes as input the parameters of our model (i.e., unet.parameters()) and the learning rate (i.e., config.INIT_LR) we will be using to train our model.
We then define the number of steps required to iterate over our entire train and test set, that is, trainSteps and testSteps, on Lines 70 and 71. Given that the dataloader provides our model config.BATCH_SIZE number of samples to process at a time, the number of steps required to iterate over the entire dataset (i.e., train or test set) can be calculated by dividing the total samples in the dataset by the batch size.
We also create an empty dictionary, H, on Line 74, that we will use to keep track of our training and test loss history.
Finally, we are in good shape to start understanding our training loop.
# loop over epochs
print("[INFO] training the network...")
startTime = time.time()
for e in tqdm(range(config.NUM_EPOCHS)):
# set the model in training mode
unet.train()
# initialize the total training and validation loss
totalTrainLoss = 0
totalTestLoss = 0
# loop over the training set
for (i, (x, y)) in enumerate(trainLoader):
# send the input to the device
(x, y) = (x.to(config.DEVICE), y.to(config.DEVICE))
# perform a forward pass and calculate the training loss
pred = unet(x)
loss = lossFunc(pred, y)
# first, zero out any previously accumulated gradients, then
# perform backpropagation, and then update model parameters
opt.zero_grad()
loss.backward()
opt.step()
# add the loss to the total training loss so far
totalTrainLoss += loss
# switch off autograd
with torch.no_grad():
# set the model in evaluation mode
unet.eval()
# loop over the validation set
for (x, y) in testLoader:
# send the input to the device
(x, y) = (x.to(config.DEVICE), y.to(config.DEVICE))
# make the predictions and calculate the validation loss
pred = unet(x)
totalTestLoss += lossFunc(pred, y)
# calculate the average training and validation loss
avgTrainLoss = totalTrainLoss / trainSteps
avgTestLoss = totalTestLoss / testSteps
# update our training history
H["train_loss"].append(avgTrainLoss.cpu().detach().numpy())
H["test_loss"].append(avgTestLoss.cpu().detach().numpy())
# print the model training and validation information
print("[INFO] EPOCH: {}/{}".format(e + 1, config.NUM_EPOCHS))
print("Train loss: {:.6f}, Test loss: {:.4f}".format(
avgTrainLoss, avgTestLoss))
# display the total time needed to perform the training
endTime = time.time()
print("[INFO] total time taken to train the model: {:.2f}s".format(
endTime - startTime))
To time our training process, we use the time() function on Line 78. This function outputs the time when it is called. Thus, we can call it once at the start and once at the end of our training process and subtract the two outputs to get the time elapsed.
We iterate for config.NUM_EPOCHS in the training loop, as shown on Line 79. Before we start training, it is important to set our model to train mode, as we see on Line 81. This directs the PyTorch engine to track our computations and gradients and build a computational graph to backpropagate later.
We initialize variables totalTrainLoss and totalTestLoss on Lines 84 and 85 to track our losses in the given epoch. Next, on Line 88, we iterate over our trainLoader dataloader, which provides a batch of samples at a time. The training loop, as shown on Lines 88-103, comprises of the following steps:
- First, on Line 90, we move our data samples (i.e.,
xandy) to the device we are training our model on, defined byconfig.DEVICE - We then pass our input image sample
xthrough ourunetmodel on Line 93 and get the output prediction (i.e.,pred) - On Line 94, we compute the loss between the model prediction,
predand our ground-truth labely - On Lines 98-100, we backpropagate our loss through the model and update the parameters
- This is executed with the help of three simple steps; we start by clearing all accumulated gradients from previous steps on Line 98. Next, we call the
backwardmethod on our computed loss function as shown on Line 99. This directs PyTorch to compute gradients of our loss w.r.t. all variables involved in the computation graph. Finally, we callopt.step()to update our model parameters as shown on Line 100.
- This is executed with the help of three simple steps; we start by clearing all accumulated gradients from previous steps on Line 98. Next, we call the
- In the end, Line 103 enables us to keep track of our training loss by adding the loss for the step to the
totalTrainLossvariable, which accumulates the training loss for all samples.
This process is repeated until iterated through all dataset samples once (i.e., completed one epoch).
Once we have processed our entire training set, we would want to evaluate our model on the test set. This is helpful since it allows us to monitor the test loss and ensure that our model is not overfitting to the training set.
While evaluating our model on the test set, we do not track gradients since we will not be learning or backpropagating. Thus we can switch off the gradient computation with the help of torch.no_grad() and freeze the model weights, as shown on Line 106. This directs the PyTorch engine not to calculate and save gradients, saving memory and compute during evaluation.
We set our model to evaluation mode by calling the eval() function on Line 108. Then, we iterate through the test set samples and compute the predictions of our model on test data (Line 116). The test loss is then added to the totalTestLoss, which accumulates the test loss for the entire test set.
We then obtain the average training loss and test loss over all steps, that is, avgTrainLoss and avgTestLoss on Lines 120 and 121, and store them on Lines 124 and 125, to our dictionary, H, which we had created in the beginning to keep track of our losses.
Finally, we print the current epoch statistics, including train and test losses on Lines 128-130. This brings us to the end of one epoch, consisting of one full cycle of training on our train set and evaluation on our test set. This entire process is repeated config.NUM_EPOCHS times until our model converges.
On Lines 133 and 134, we note the end time of our training loop and subtract endTime from startTime (which we had initialized at the beginning of training) to get the total time elapsed during our network training.
# plot the training loss
plt.style.use("ggplot")
plt.figure()
plt.plot(H["train_loss"], label="train_loss")
plt.plot(H["test_loss"], label="test_loss")
plt.title("Training Loss on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss")
plt.legend(loc="lower left")
plt.savefig(config.PLOT_PATH)
# serialize the model to disk
torch.save(unet, config.MODEL_PATH)
Next, we use the pyplot package of matplotlib to visualize and save our training and test loss curves on Lines 138-146. We can do this by simply passing the train_loss and test_loss keys of our loss history dictionary, H, to the plot function as shown on Lines 140 and 141. Finally, we set the title and legends of our plots (Lines 142-145) and save our visualizations on Line 146.
Finally, on Lines 149, we save the weights of our trained U-Net model with the help of the torch.save() function, which takes our trained unet model and the config.MODEL_PATH as input where we want our model to be saved.
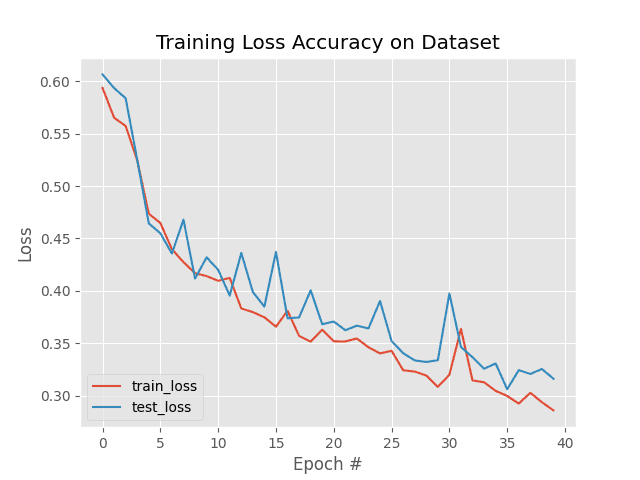
Once our model is trained, we will see a loss trajectory plot similar to the one shown in Figure 4. Notice that train_loss gradually reduces over epochs and slowly converges. Furthermore, we see that test_loss also consistently reduces with train_loss following similar trends and values, implying our model generalizes well and is not overfitting to the training set.
Using Our Trained U-Net Model for Prediction
Once we have trained and saved our segmentation model, we are ready to see it in action and use it for segmentation tasks.
Open the predict.py file from our project directory.
# USAGE
# python predict.py
# import the necessary packages
from pyimagesearch import config
import matplotlib.pyplot as plt
import numpy as np
import torch
import cv2
import os
def prepare_plot(origImage, origMask, predMask):
# initialize our figure
figure, ax = plt.subplots(nrows=1, ncols=3, figsize=(10, 10))
# plot the original image, its mask, and the predicted mask
ax[0].imshow(origImage)
ax[1].imshow(origMask)
ax[2].imshow(predMask)
# set the titles of the subplots
ax[0].set_title("Image")
ax[1].set_title("Original Mask")
ax[2].set_title("Predicted Mask")
# set the layout of the figure and display it
figure.tight_layout()
figure.show()
We import the necessary packages and modules as always on Lines 5-10.
To use our segmentation model for prediction, we will need a function that can take our trained model and test images, predict the output segmentation mask and finally, visualize the output predictions.
To this end, we start by defining the prepare_plot function to help us to visualize our model predictions.
This function takes as input an image, its ground-truth mask, and the segmentation output predicted by our model, that is, origImage, origMask, and predMask (Line 12) and creates a grid with a single row and three columns (Line 14) to display them (Lines 17-19).
Finally, Lines 22-24 set titles for our plots, displaying them on Lines 27 and 28.
def make_predictions(model, imagePath):
# set model to evaluation mode
model.eval()
# turn off gradient tracking
with torch.no_grad():
# load the image from disk, swap its color channels, cast it
# to float data type, and scale its pixel values
image = cv2.imread(imagePath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = image.astype("float32") / 255.0
# resize the image and make a copy of it for visualization
image = cv2.resize(image, (128, 128))
orig = image.copy()
# find the filename and generate the path to ground truth
# mask
filename = imagePath.split(os.path.sep)[-1]
groundTruthPath = os.path.join(config.MASK_DATASET_PATH,
filename)
# load the ground-truth segmentation mask in grayscale mode
# and resize it
gtMask = cv2.imread(groundTruthPath, 0)
gtMask = cv2.resize(gtMask, (config.INPUT_IMAGE_HEIGHT,
config.INPUT_IMAGE_HEIGHT))
Next, we define our make_prediction function (Lines 31-77), which will take as input the path to a test image and our trained segmentation model and plot the predicted output.
Since we are only using our trained model for prediction, we start by setting our model to eval mode and switching off PyTorch gradient computation on Line 33 and Line 36, respectively.
On Lines 39-41, we load the test image (i.e., image) from imagePath using OpenCV (Line 39), convert it to RGB format (Line 40), and normalize its pixel values from the standard [0-255] to the range [0, 1], which our model is trained to process (Line 41).
The image is then resized to the standard image dimension that our model can accept on Line 44. Since we will have to modify and process the image variable before passing it through the model, we make an additional copy of it on Line 45 and store it in the orig variable, which we will use later.
On Lines 49-51, we get the path to the ground-truth mask for our test image and load the mask on Line 55. Note that we resize the mask to the same dimensions as the input image (Lines 56 and 57).
Now we process our image to a format that our model can process. Note that currently, our image has the shape [128, 128, 3]. However, our segmentation model accepts four-dimensional inputs of the format [batch_dimension, channel_dimension, height, width].
# make the channel axis to be the leading one, add a batch # dimension, create a PyTorch tensor, and flash it to the # current device image = np.transpose(image, (2, 0, 1)) image = np.expand_dims(image, 0) image = torch.from_numpy(image).to(config.DEVICE) # make the prediction, pass the results through the sigmoid # function, and convert the result to a NumPy array predMask = model(image).squeeze() predMask = torch.sigmoid(predMask) predMask = predMask.cpu().numpy() # filter out the weak predictions and convert them to integers predMask = (predMask > config.THRESHOLD) * 255 predMask = predMask.astype(np.uint8) # prepare a plot for visualization prepare_plot(orig, gtMask, predMask)
On Line 62, we transpose the image to convert it to channel-first format, that is, [3, 128, 128], and on Line 63, we add an extra dimension using the expand_dims function of numpy to convert our image into a four-dimensional array (i.e., [1, 3, 128, 128]). Note that the first dimension here represents the batch dimension equal to one since we are processing one test image at a time. We then convert our image to a PyTorch tensor with the help of the torch.from_numpy() function and move it to the device our model is on with the help of Line 64.
Finally, on Lines 68-70, we process our test image by passing it through our model and saving the output prediction as predMask. We then apply the sigmoid activation to get our predictions in the range [0, 1]. As discussed earlier, the segmentation task is a classification problem where we have to classify the pixels in one of the two discrete classes. Since sigmoid outputs continuous values in the range [0, 1], we use our config.THRESHOLD on Line 73 to binarize our output and assign the pixels, values equal to 0 or 1. This implies that anything greater than the threshold will be assigned the value 1, and others will be assigned 0.
Since the thresholded output (i.e., (predMask > config.THRESHOLD)), now comprises of values 0 or 1, multiplying it with 255 makes the final pixel values in our predMask either 0 (i.e., pixel value for black color) or 255 (i.e., pixel value for white color). As discussed earlier, the white pixels will correspond to the region where our model has detected salt deposits, and the black pixels correspond to regions where salt is not present.
We plot our original image (i.e., orig), ground-truth mask (i.e., gtMask), and our predicted output (i.e., predMask) with the help of our prepare_plot function on Line 77. This completes the definition of our make_prediction function.
We are ready to see our model in action now.
# load the image paths in our testing file and randomly select 10
# image paths
print("[INFO] loading up test image paths...")
imagePaths = open(config.TEST_PATHS).read().strip().split("\n")
imagePaths = np.random.choice(imagePaths, size=10)
# load our model from disk and flash it to the current device
print("[INFO] load up model...")
unet = torch.load(config.MODEL_PATH).to(config.DEVICE)
# iterate over the randomly selected test image paths
for path in imagePaths:
# make predictions and visualize the results
make_predictions(unet, path)
On Lines 82 and 83, we open the folder where our test image paths are stored and randomly grab 10 image paths. Line 87 loads the trained weights of our U-Net from the saved checkpoint at config.MODEL_PATH.
We finally iterate over our randomly chosen test imagePaths and predict the outputs with the help of our make_prediction function on Lines 90-92.
Figure 5 shows sample visualization outputs from our make_prediction function. The yellow region represents Class 1: Salt and the dark blue region represents Class 2: Not Salt (sediment).
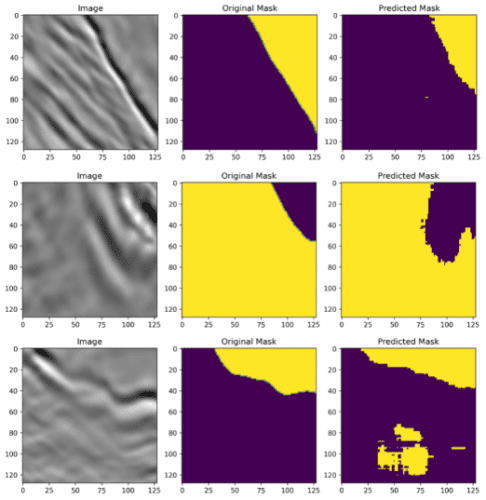
We see that in case 1 and case 2 (i.e., row 1 and row 2, respectively), our model correctly identified most of the locations containing salt deposits. However, some regions where the salt deposit exists are not identified.
However, in case 3 (i.e., row 3), our model has identified some regions as salt deposits where there is no salt (the yellow blob in the middle). This is a false positive, where our model has incorrectly predicted the positive class, that is, the presence of salt, in a region where it does not exist in the ground truth.
It is worth noting that, practically, from an application point of view, the prediction in case 3 is misleading and riskier than that in the other two cases. This is likely because for the first two cases if experts set up drillers for mining salt deposits at the predicted yellow marked locations, they will successfully find salt deposits. However, if they do the same at the location of false-positive predictions (as seen in case 3), it will waste time and resources since salt deposits do not exist at that location.
Credits
Aman Arora’s amazing article inspires our implementation of the U-Net model in the model.py file.
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: April 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this tutorial, we learned about image segmentation and built a U-Net-based image segmentation pipeline from scratch in PyTorch.
Specifically, we discussed the architectural details and salient features of the U-Net model that make it the de-facto choice for image segmentation.
In addition, we learned how we can define our own custom dataset in PyTorch for the segmentation task at hand.
Finally, we saw how we can train our U-Net based-segmentation pipeline in PyTorch and use the trained model to make predictions on test images in real-time.
After following the tutorial, you will be able to understand the internal working of any image segmentation pipeline and build your own segmentation models from scratch in PyTorch.
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.