In this tutorial, you will learn how to train your first neural network using the PyTorch deep learning library.

This tutorial is part two in our five part series on PyTorch deep learning fundamentals:
- What is PyTorch?
- Intro to PyTorch: Training your first neural network using PyTorch (today’s tutorial)
- PyTorch: Training your first Convolutional Neural Network (next week’s tutorial)
- PyTorch image classification with pre-trained networks
- PyTorch object detection with pre-trained networks
By the end of this guide, you will have learned:
- How to define a basic neural network architecture with PyTorch
- How to define your loss function and optimizer
- How to properly zero your gradient, perform backpropagation, and update your model parameters — most deep learning practitioners new to PyTorch make a mistake in this step
To learn how to train your first neural network with PyTorch, just keep reading.
Intro to PyTorch: Training your first neural network using PyTorch
Inside this guide, you will become familiar with common procedures in PyTorch, including:
- Defining your neural network architecture
- Initializing your optimizer and loss function
- Looping over your number of training epochs
- Looping over data batches inside each epoch
- Making predictions and computing the loss on the current batch of data
- Zeroing out your gradient
- Performing backpropagation
- Telling your optimizer to update the gradients of your network
- Telling PyTorch to train your network with a GPU (if a GPU is available on your machine, of course)
We’ll start by reviewing our project directory structure and then configuring our development environment.
From there, we’ll implement two Python scripts:
- The first script will be our simple feedforward neural network architecture, implemented with Python and the PyTorch library
- The second script will then load our example dataset and demonstrate how to train the network architecture we just implemented using PyTorch
With our two Python scripts implemented, we’ll move on to training our network. We’ll wrap up the tutorial with a discussion of our results.
Let’s get started!
Configuring your development environment
To follow this guide, you need to have the PyTorch deep learning library and the scikit-machine learning package installed on your system.
Luckily, both PyTorch and scikit-learn are extremely easy to install using pip:
$ pip install torch torchvision $ pip install scikit-image
If you need help configuring your development environment for PyTorch, I highly recommend that you read the PyTorch documentation — PyTorch’s documentation is comprehensive and will have you up and running quickly.
Having problems configuring your development environment?
All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code right now on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides that are pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Project structure
To follow along with this tutorial, be sure to access the “Downloads” section of this guide to retrieve the source code.
You’ll then be presented with the following directory structure.
$ tree . --dirsfirst . ├── pyimagesearch │ └── mlp.py └── train.py 1 directory, 2 files
The mlp.py file will store our implementation of a basic multi-layer perceptron (MLP).
We’ll then implement train.py which will be used to train our MLP on an example dataset.
Implementing our neural network with PyTorch
You are now about ready to implement your first neural network with PyTorch!
This network is a very simple feedforward neural network called a multi-layer perceptron (MLP) (meaning that it has one or more hidden layers). You’ll learn how to build more advanced neural network architectures next week’s tutorial.
To get started building our PyTorch neural network, open the mlp.py file in the pyimagesearch module of your project directory structure, and let’s get to work:
# import the necessary packages
from collections import OrderedDict
import torch.nn as nn
def get_training_model(inFeatures=4, hiddenDim=8, nbClasses=3):
# construct a shallow, sequential neural network
mlpModel = nn.Sequential(OrderedDict([
("hidden_layer_1", nn.Linear(inFeatures, hiddenDim)),
("activation_1", nn.ReLU()),
("output_layer", nn.Linear(hiddenDim, nbClasses))
]))
# return the sequential model
return mlpModel
Lines 2 and 3 import our required Python packages:
OrderedDict: A dictionary object that remembers the order in which objects were added — we use this ordered dictionary to provide human-readable names to each layer in the networknn: PyTorch’s neural network implementations
We then define the get_training_model function (Line 5) which accepts three parameters:
- The number of input nodes to the neural network
- The number of nodes in the hidden layer of the network
- The number of output nodes (i.e., dimensionality of the output prediction)
Based on the default values provided, you can see that we are building a 4-8-3 neural network, meaning that the input layer has 4 nodes, the hidden layer 8 nodes, and the output of the neural network will consist of 3 values.
The actual neural network architecture is then constructed on Lines 7-11 by first initializing a nn.Sequential object (very similar to Keras/TensorFlow’s Sequential class).
Inside the Sequential class we build an OrderedDict where each entry in the dictionary consists of two values:
- A string containing the human-readable name for the layer (which is very useful when debugging neural network architectures using PyTorch)
- The PyTorch layer definition itself
The Linear class is our fully connected layer definition, meaning that each of the inputs connects to each of the outputs in the layer. The Linear class accepts two required arguments:
- The number of inputs to the layer
- The number of outputs
On Line 8, we define hidden_layer_1 which consists of a fully connected layer accepting inFeatures (4) inputs and then producing an output of hiddenDim (8).
From there, we apply a ReLU activation function (Line 9) followed by another Linear layer which serves as our output (Line 10).
Notice that the second Linear definition contains the same number of inputs as the previous Linear layer did outputs — this is not by accident! The output dimensions of the previous layer must match the input dimensions of the next layer, otherwise PyTorch will error out (and then you’ll have the quite tedious task of debugging the layer dimensions yourself).
PyTorch is not as forgiving in this regard (as opposed to Keras/TensorFlow), so be extra cautious when specifying your layer dimensions.
The resulting PyTorch neural network is then returned to the calling function.
Creating our PyTorch training script
With our neural network architecture implemented, we can move on to training the model using PyTorch.
To accomplish this task, we’ll need to implement a training script which:
- Creates an instance of our neural network architecture
- Builds our dataset
- Determines whether or not we are training our model on a GPU
- Defines a training loop (the hardest part of our script)
Open train.py, and lets get started:
# import the necessary packages from pyimagesearch import mlp from torch.optim import SGD from sklearn.model_selection import train_test_split from sklearn.datasets import make_blobs import torch.nn as nn import torch
Lines 2-7 import our required Python packages, including:
mlp: Our definition of the multi-layer perceptron architecture, implemented in PyTorchSGD: The Stochastic Gradient Descent optimizer that we’ll be using to train our modelmake_blobs: Builds a synthetic dataset of example datatrain_test_split: Splits our dataset into a training and testing splitnn: PyTorch’s neural network functionalitytorch: The base PyTorch library
When training a neural network, we do so in batches of data (as you’ve previously learned). The following function, next_batch, yields such batches to our training loop:
def next_batch(inputs, targets, batchSize): # loop over the dataset for i in range(0, inputs.shape[0], batchSize): # yield a tuple of the current batched data and labels yield (inputs[i:i + batchSize], targets[i:i + batchSize])
The next_batch function accepts three arguments:
inputs: Our input data to the neural networktargets: Our target output values (i.e., what we want our neural network to accurately predict)batchSize: Size of data batch
We then loop over our input data in batchSize chunks (Line 11) and yield them to the calling function (Line 13).
Next, we have some important initializations to take care of:
# specify our batch size, number of epochs, and learning rate
BATCH_SIZE = 64
EPOCHS = 10
LR = 1e-2
# determine the device we will be using for training
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
print("[INFO] training using {}...".format(DEVICE))
When training our neural network with PyTorch we’ll use a batch size of 64, train for 10 epochs, and use a learning rate of 1e-2 (Lines 16-18).
We set our training device (either CPU or GPU) on Line 21. A GPU will certainly speed up training but is not required for this example.
Next, we need an example dataset to train our neural network on. We’ll learn how to load images from disk and train a neural network on image data in the next tutorial in this series, but for now, let’s use scikit-learn’s make_blobs function to create a synthetic dataset for us:
# generate a 3-class classification problem with 1000 data points,
# where each data point is a 4D feature vector
print("[INFO] preparing data...")
(X, y) = make_blobs(n_samples=1000, n_features=4, centers=3,
cluster_std=2.5, random_state=95)
# create training and testing splits, and convert them to PyTorch
# tensors
(trainX, testX, trainY, testY) = train_test_split(X, y,
test_size=0.15, random_state=95)
trainX = torch.from_numpy(trainX).float()
testX = torch.from_numpy(testX).float()
trainY = torch.from_numpy(trainY).float()
testY = torch.from_numpy(testY).float()
Lines 27 and 28 build our dataset, consisting of:
- Three class labels (
centers=3) - Four total features/inputs to the neural network (
n_features=4) - A total of 1000 data points (
n_samples=1000)
Essentially, the make_blobs function is generating Gaussian blobs of clustered data points. For 2D data, the make_blobs function would create data similar to the following:
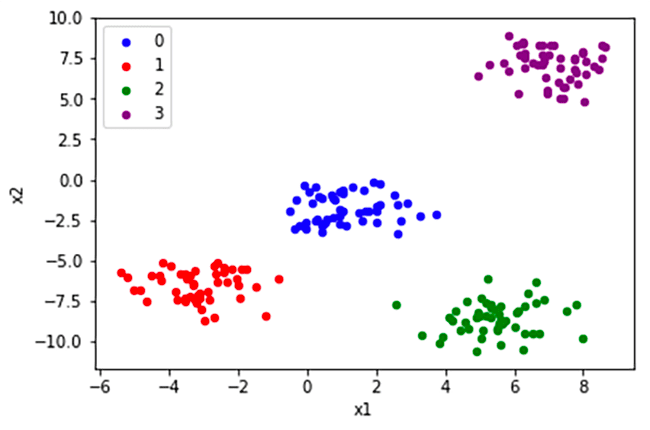
Notice there are three clusters of data here. We are doing the same thing, but instead of two dimensions we have four dimensions (meaning we cannot easily visualize it).
Once our data is generated, we apply the train_test_split function (Lines 32 and 33) to create our training split, 85% for training and 15% for evaluation.
From there, the training and testing data is converted to PyTorch tensors from NumPy arrays, and then converted to the floating point data type (Lines 34-37).
Let’s now instantiate our PyTorch neural network architecture:
# initialize our model and display its architecture mlp = mlp.get_training_model().to(DEVICE) print(mlp) # initialize optimizer and loss function opt = SGD(mlp.parameters(), lr=LR) lossFunc = nn.CrossEntropyLoss()
Line 40 initializes our MLP and pushes it to whatever DEVICE we are using for training (either CPU or GPU).
Line 44 defines our SGD optimizer, which accepts two arguments:
- The MLP model parameters, obtained by simply calling
mlp.parameters() - The learning rate
Finally, we initialize our categorical cross-entropy loss function, which is the standard loss method you’ll use when performing classification with > 2 classes.
We now arrive at our most important code block, the training loop. Unlike Keras/TensorFlow, which allow you to simply call model.fit to train your model, PyTorch requires that you implement your training loop by hand.
There are pros and cons of having to implement the training loop by hand.
On one side of the spectrum, you have complete and total control over the training procedure, which makes it easier to implement custom training loops.
But on the other side of the spectrum, implementing a training loop by hand requires more code, and worst of all, makes it far easier to shoot yourself in the foot (which can be especially true for budding deep learning practitioners).
My suggestion: You’ll want to read the explanations to the following code blocks multiple times so that you understand the intricacies of the training loop. You’ll especially want to pay close attention to how we zero the gradient, perform backpropagation, and then update the model parameters — failing to do so in that exact order will lead to erroneous results!
Let’s review our training loop:
# create a template to summarize current training progress
trainTemplate = "epoch: {} test loss: {:.3f} test accuracy: {:.3f}"
# loop through the epochs
for epoch in range(0, EPOCHS):
# initialize tracker variables and set our model to trainable
print("[INFO] epoch: {}...".format(epoch + 1))
trainLoss = 0
trainAcc = 0
samples = 0
mlp.train()
# loop over the current batch of data
for (batchX, batchY) in next_batch(trainX, trainY, BATCH_SIZE):
# flash data to the current device, run it through our
# model, and calculate loss
(batchX, batchY) = (batchX.to(DEVICE), batchY.to(DEVICE))
predictions = mlp(batchX)
loss = lossFunc(predictions, batchY.long())
# zero the gradients accumulated from the previous steps,
# perform backpropagation, and update model parameters
opt.zero_grad()
loss.backward()
opt.step()
# update training loss, accuracy, and the number of samples
# visited
trainLoss += loss.item() * batchY.size(0)
trainAcc += (predictions.max(1)[1] == batchY).sum().item()
samples += batchY.size(0)
# display model progress on the current training batch
trainTemplate = "epoch: {} train loss: {:.3f} train accuracy: {:.3f}"
print(trainTemplate.format(epoch + 1, (trainLoss / samples),
(trainAcc / samples)))
Line 48 initializes trainTemplate, a string that will allow us to conveniently display the epoch number, along with the loss and accuracy at each step.
We then loop over our number of desired training epochs on Line 51. Immediately inside this for loop we:
- Show the epoch number, which is useful for debugging purposes (Line 53)
- Initialize our training loss and accuracy (Lines 54 and 55)
- Initialize the total number of data points used inside the current iteration of the training loop (Line 56)
- Put the PyTorch model in training mode (Line 57)
Calling the train() method of the PyTorch model is required for the model parameters to be updated during backpropagation.
In our next code block, you’ll see that we put the model into eval() mode so that we can evaluate the loss and accuracy on our testing set. If we forgot to then call train() at the top of the next training loop, then our model parameters will not be updated.
The outer for loop (Line 51) loops over our number of epochs. Line 60 then starts an inner for loop that loops over each of our batches in the training set. Nearly every training procedure you write using PyTorch will consist of an outer loop (over the number of epochs) and an inner loop (over the data batches).
Within the inner loop (i.e., the batch loop), we proceed to:
- Move the
batchXandbatchYdata to our CPU or GPU (depending on ourDEVICE) - Pass the
batchXdata through the neural and make predictions on it - Use our loss function to compute our loss by comparing the output
predictionsto our ground-truth class labels
Now that we have our loss, we can update our model parameters — this is the most important step in the PyTorch training procedure and often the one most beginners mess up.
To update the parameters of our model, we must call Lines 69-71 in the exact order specified:
opt.zero_grad(): Zeros the gradients accumulated from the previous batch/step of the modelloss.backward(): Performs backpropagationopt.step(): Updates the weights in our neural network based on the results of backpropagation
Again, I want to stress that you must apply zeroing the gradients, performing a backward pass, and then updating the model parameters in the exact order that I’ve indicated.
As I’ve mentioned, PyTorch gives you a lot of control over your training loop … but it also makes it very easy to shoot yourself in the foot. Every single deep learning practitioner, whether brand new to the world of deep learning or a seasoned expert, has at one time or another messed up these steps.
The most common mistake is forgetting to zero the gradient. If you don’t zero the gradient then you’ll accumulate gradients across multiple batches and over multiple epochs. That will mess up your backpropagation and lead to erroneous weight updates.
Seriously, don’t mess up these steps. Write them on a sticky note and put them on your monitor if you need to.
After we’ve updated the weights to our model, we compute our train loss, train accuracy, and number of samples examined (i.e., number of data points in the batch) on Lines 75-77.
We then apply our trainTemplate to display our epoch number, training loss, and training accuracy. Note how we divide our loss and accuracy by the total number of samples in the batch to obtain an average.
At this point, we’ve trained our PyTorch model on all data points in an epoch — now we need to evaluate it on our testing set:
# initialize tracker variables for testing, then set our model to
# evaluation mode
testLoss = 0
testAcc = 0
samples = 0
mlp.eval()
# initialize a no-gradient context
with torch.no_grad():
# loop over the current batch of test data
for (batchX, batchY) in next_batch(testX, testY, BATCH_SIZE):
# flash the data to the current device
(batchX, batchY) = (batchX.to(DEVICE), batchY.to(DEVICE))
# run data through our model and calculate loss
predictions = mlp(batchX)
loss = lossFunc(predictions, batchY.long())
# update test loss, accuracy, and the number of
# samples visited
testLoss += loss.item() * batchY.size(0)
testAcc += (predictions.max(1)[1] == batchY).sum().item()
samples += batchY.size(0)
# display model progress on the current test batch
testTemplate = "epoch: {} test loss: {:.3f} test accuracy: {:.3f}"
print(testTemplate.format(epoch + 1, (testLoss / samples),
(testAcc / samples)))
print("")
Similar to how we initialized our training loss, training accuracy, and number of samples in a batch, we do the same thing for our testing set on Lines 86-88. Here, we initialize variables to store our testing loss, testing accuracy, and number of samples in the testing set.
We also put our model into eval() model on Line 89. We are required to put our model in evaluation mode when we need to compute losses/accuracies on the testing or validation set.
But what does the eval() mode actually do? You think of evaluation mode as a switch for turning off specific layer functionality, such as stopping dropout from being applied, or allowing the accumulated states of batch normalization to be applied.
Secondly, you typically use eval() in conjunction with a torch.no_grad() context, meaning that gradient computation is turned off in evaluation mode (Line 92).
From there, we loop over all batches in our testing set (Line 94), similar to how we looped over our training batches in the previous code block.
For each batch (Line 96), we make predictions using our model and then compute the loss (Lines 99 and 100).
We then update our testLoss, testAcc, and number of samples (Lines 104-106).
Finally, we display our epoch number, testing loss, and testing accuracy on our terminal (Lines 109-112).
In general, the evaluation portion of our training loop is very similar to the training portion, with no minor but very significant changes:
- We put our model into evaluation mode using
eval() - We use a
torch.no_grad()context to ensure no graduation computation is performed
From there, we can make predictions using our model and compute the accuracy/loss on the testing set.
PyTorch training results
We are now ready to train our neural network with PyTorch!
Be sure to access the “Downloads” section of this tutorial to retrieve the source code.
To launch the PyTorch training process, simply execute the train.py script:
$ python train.py [INFO] training on cuda... [INFO] preparing data... Sequential( (hidden_layer_1): Linear(in_features=4, out_features=8, bias=True) (activation_1): ReLU() (output_layer): Linear(in_features=8, out_features=3, bias=True) ) [INFO] training in epoch: 1... epoch: 1 train loss: 0.971 train accuracy: 0.580 epoch: 1 test loss: 0.737 test accuracy: 0.827 [INFO] training in epoch: 2... epoch: 2 train loss: 0.644 train accuracy: 0.861 epoch: 2 test loss: 0.590 test accuracy: 0.893 [INFO] training in epoch: 3... epoch: 3 train loss: 0.511 train accuracy: 0.916 epoch: 3 test loss: 0.495 test accuracy: 0.900 [INFO] training in epoch: 4... epoch: 4 train loss: 0.425 train accuracy: 0.941 epoch: 4 test loss: 0.423 test accuracy: 0.933 [INFO] training in epoch: 5... epoch: 5 train loss: 0.359 train accuracy: 0.961 epoch: 5 test loss: 0.364 test accuracy: 0.953 [INFO] training in epoch: 6... epoch: 6 train loss: 0.302 train accuracy: 0.975 epoch: 6 test loss: 0.310 test accuracy: 0.960 [INFO] training in epoch: 7... epoch: 7 train loss: 0.252 train accuracy: 0.984 epoch: 7 test loss: 0.259 test accuracy: 0.967 [INFO] training in epoch: 8... epoch: 8 train loss: 0.209 train accuracy: 0.987 epoch: 8 test loss: 0.215 test accuracy: 0.980 [INFO] training in epoch: 9... epoch: 9 train loss: 0.174 train accuracy: 0.988 epoch: 9 test loss: 0.180 test accuracy: 0.980 [INFO] training in epoch: 10... epoch: 10 train loss: 0.147 train accuracy: 0.991 epoch: 10 test loss: 0.153 test accuracy: 0.980
Our first few lines of output show the simple 4-8-3 MLP architecture, meaning that there are four inputs to the neural network, a single hidden layer with eight nodes, and a final output layer with three nodes.
We then train our network for a total of ten epochs. By the end of the training process, we are obtaining 99.1% accuracy on our training set and 98% accuracy on our testing set.
We can therefore conclude that our neural network is doing a good job making accurate predictions.
Congrats on training your first neural network with PyTorch!
How do I train a PyTorch model on my own custom dataset?
This tutorial showed you how to train a PyTorch neural network on an example dataset generated by scikit-learn’s make_blobs function.
While this was a great example to learn the basics of PyTorch, it’s admittedly not very interesting from a real-world scenario perspective.
Next week, you’ll learn how to train a PyTorch model on a dataset of handwritten characters, which has many practical applications, including handwriting recognition, OCR, and more!
Stay tuned for next week’s tutorial to learn more about PyTorch and image classification.
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: June 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this tutorial, you learned how to train your first neural network using the PyTorch deep learning library. This example was admittedly simple, but demonstrated the fundamentals of the PyTorch framework.
The biggest mistake I see with deep learning practitioners new to the PyTorch library is forgetting and/or mixing up the following steps:
- Zeroing out gradients from the previous steps (
opt.zero_grad()) - Performing backpropagation (
loss.backward()) - Updating model parameters (
opt.step())
Failure to perform these steps in this exact order is a surefire way to shoot yourself in the foot when using PyTorch, and worse, PyTorch doesn’t report an error if you mix up these steps, so you may not even know you shot yourself!
The PyTorch library is super powerful, but you’ll need to get used to the fact that training a neural network with PyTorch is like taking off your bicycle’s training wheels — there’s no safety net to catch you if you mix up important steps (unlike with Keras/TensorFlow which allow you to encapsulate entire training procedures into a single model.fit call).
That’s not to say that Keras/TensorFlow are “better” than PyTorch — it’s just a difference between the two deep learning libraries of which you need to be aware.
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.