
Over the past few weeks we have been discussing facial landmarks and the role they play in computer vision and image processing.
We’ve started off by learning how to detect facial landmarks in an image.
We then discovered how to label and annotate each of the facial regions, such as eyes, eyebrows, nose, mouth, and jawline.
Today we are going to expand our implementation of facial landmarks to work in real-time video streams, paving the way for more real-world applications, including next week’s tutorial on blink detection.
To learn how to detect facial landmarks in video streams in real-time, just keep reading.
Real-time facial landmark detection with OpenCV, Python, and dlib
The first part of this blog post will provide an implementation of real-time facial landmark detection for usage in video streams utilizing Python, OpenCV, and dlib.
We’ll then test our implementation and use it to detect facial landmarks in videos.
Facial landmarks in video streams
Let’s go ahead and get this facial landmark example started.
Open up a new file, name it video_facial_landmarks.py , and insert the following code:
# import the necessary packages from imutils.video import VideoStream from imutils import face_utils import datetime import argparse import imutils import time import dlib import cv2
Lines 2-9 import our required Python packages.
We’ll be using the face_utils sub-module of imutils, so if you haven’t installed/upgraded to the latest version, take a second and do so now:
$ pip install --upgrade imutils
Note: If you are using Python virtual environments, take care to ensure you are installing/upgrading imutils in your proper environment.
We’ll also be using the VideoStream implementation inside of imutils , allowing you to access your webcam/USB camera/Raspberry Pi camera module in a more efficient, faster, treaded manner. You can read more about the VideoStream class and how it accomplishes a higher frame throughout in this blog post.
If you would like to instead work with video files rather than video streams, be sure to reference this blog post on efficient frame polling from a pre-recorded video file, replacing VideoStream with FileVideoStream .
For our facial landmark implementation we’ll be using the dlib library. You can learn how to install dlib on your system in this tutorial (if you haven’t done so already).
Next, let’s parse our command line arguments:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--shape-predictor", required=True,
help="path to facial landmark predictor")
ap.add_argument("-r", "--picamera", type=int, default=-1,
help="whether or not the Raspberry Pi camera should be used")
args = vars(ap.parse_args())
Our script requires one command line argument, followed by a second optional one, each detailed below:
--shape-predictor: The path to dlib’s pre-trained facial landmark detector. Use the “Downloads” section of this blog post to download an archive of the code + facial landmark predictor file.--picamera: An optional command line argument, this switch indicates whether the Raspberry Pi camera module should be used instead of the default webcam/USB camera. Supply a value > 0 to use your Raspberry Pi camera.
Now that our command line arguments have been parsed, we need to initialize dlib’s HOG + Linear SVM-based face detector and then load the facial landmark predictor from disk:
# initialize dlib's face detector (HOG-based) and then create
# the facial landmark predictor
print("[INFO] loading facial landmark predictor...")
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(args["shape_predictor"])
The next code block simply handles initializing our VideoStream and allowing the camera sensor to warm up:
# initialize the video stream and allow the cammera sensor to warmup
print("[INFO] camera sensor warming up...")
vs = VideoStream(usePiCamera=args["picamera"] > 0).start()
time.sleep(2.0)
The heart of our video processing pipeline can be found inside the while loop below:
# loop over the frames from the video stream while True: # grab the frame from the threaded video stream, resize it to # have a maximum width of 400 pixels, and convert it to # grayscale frame = vs.read() frame = imutils.resize(frame, width=400) gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # detect faces in the grayscale frame rects = detector(gray, 0)
On Line 31 we start an infinite loop that we can only break out of if we decide to exit the script by pressing the q key on our keyboard.
Line 35 grabs the next frame from our video stream.
We then preprocess this frame by resizing it to have a width of 400 pixels and convert it to grayscale (Lines 36 an 37).
Before we can detect facial landmarks in our frame, we first need to localize the face — this is accomplished on Line 40 via the detector which returns the bounding box (x, y)-coordinates for each face in the image.
Now that we have detected the faces in the video stream, the next step is to apply the facial landmark predictor to each face ROI:
# loop over the face detections
for rect in rects:
# determine the facial landmarks for the face region, then
# convert the facial landmark (x, y)-coordinates to a NumPy
# array
shape = predictor(gray, rect)
shape = face_utils.shape_to_np(shape)
# loop over the (x, y)-coordinates for the facial landmarks
# and draw them on the image
for (x, y) in shape:
cv2.circle(frame, (x, y), 1, (0, 0, 255), -1)
# show the frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
On Line 43 we loop over each of the detected faces.
Line 47 applies the facial landmark detector to the face region, returning a shape object which we convert to a NumPy array (Line 48).
Lines 52 and 53 then draw a series of circles on the output frame , visualizing each of the facial landmarks. To understand what facial region (i.e., nose, eyes, mouth, etc.) each (x, y)-coordinate maps to, please refer to this blog post.
Lines 56 and 57 display the output frame to our screen. If the q key is pressed, we break from the loop and stop the script (Lines 60 and 61).
Finally, Lines 64 and 65 do a bit of cleanup:
# do a bit of cleanup cv2.destroyAllWindows() vs.stop()
As you can see, there are very little differences between detecting facial landmarks in images versus detecting facial landmarks in video streams — the main differences in the code simply involve setting up our video stream pointers and then polling the stream for frames.
The actual process of detecting facial landmarks is the same, only instead of detecting facial landmarks in a single image we are now detecting facial landmarks in a series of frames.
Real-time facial landmark results
To test our real-time facial landmark detector using OpenCV, Python, and dlib, make sure you use the “Downloads” section of this blog post to download an archive of the code, project structure, and facial landmark predictor model.
If you are using a standard webcam/USB camera, you can execute the following command to start the video facial landmark predictor:
$ python video_facial_landmarks.py \ --shape-predictor shape_predictor_68_face_landmarks.dat
Otherwise, if you are on your Raspberry Pi, make sure you append the --picamera 1 switch to the command:
$ python video_facial_landmarks.py \ --shape-predictor shape_predictor_68_face_landmarks.dat \ --picamera 1
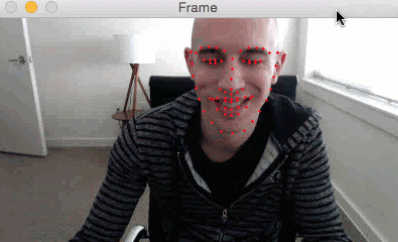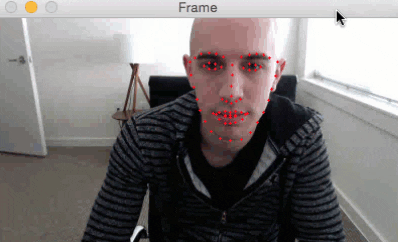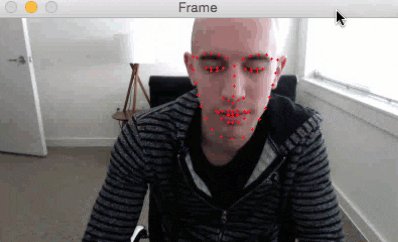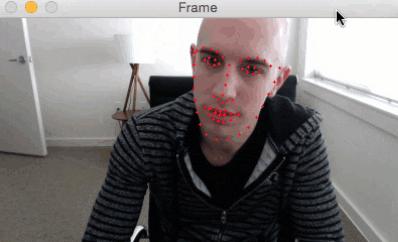
Here is a short GIF of the output where you can see that facial landmarks have been successfully detected on my face in real-time:
I have included a full video output below as well:
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: April 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In today’s blog post we extended our previous tutorials on facial landmarks and applied them to the task of real-time detection.
As our results demonstrated, we are fully capable of detecting facial landmarks in a video stream in real-time using a system with a modest CPU.
Now that we understand how to access a video stream and apply facial landmark detection, we can move on to next week’s real-world computer vision application — blink detection.
To be notified when the blink detection tutorial goes live, be sure to enter your email address in the form below — this is a tutorial you won’t want to miss!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Thanks for this tutorial . how the face landmarks can be more stable , I tried the tutorial and the points are shaky
Great work Adrian, my only question is will it work with multiple faces? And will it affect the performance or accuracy?
I would suggest going back and reading my previous posts facial landmarks. This method will work with multiple faces provided that each face in the image/video stream can be detected.
Awaiting for this, thank you so much.
Thank you Shravan! 🙂
This one is freaking awesome! Will definitively try it out and install dlib. Thanks Adrian for this row of posts! 🙂
Thanks Linus — it only gets better from here 🙂
Beautiful! Thanks a lot!
Hey this is really great stuff. I can’t wait to try it out. I want to use it for my magic mirror to tell who is standing in front of it. I’m sure I could Google a algorithm up but could you do a blog post on how to some what reliably detect the same person over and over again.
I wouldn’t recommend using facial landmarks for facial recognition. Algorithms such as LBPs for face recognition, Eigenfaces, and Fisherfaces would work well for a magic mirror application. I cover LBPs for face recognition and Eigenfaces inside the PyImageSearch Gurus course.
Hello Adrian…
what if i use dlib only for face identification because haarcascades do not identify flipped faces and from there i use LBP for face recognition?
As I mentioned, facial landmarks are not used for face identification. You can use either Haar cascades or the dlib built-in factor detector to detect horizontally flipped faces. To detect vertically flipped faces, simply flip your image prior to passing them into the detector.
This is awesome! Thanks for another great blog Adrian….keep it up!
Thanks Joe! 🙂
Really impressed by the way you have done with this coding of real-time facial landmark detection for usage in video streams utilizing Python. Splendid!
And I can’t understand why you import datetime? Is this just from development?
And the whole thing worked out just fine BTW 😀
The
import datetimecam be safely removed. I had it imported for a different application I was working on.Woah, super cool Adrian! Another awesome article
Thank you David!
I really want to make a game controlled by facial expressions. I think it would be hilarious to get people to play it in public.
That certainly sounds like a neat game, Matt! I’m actually covering how to recognize facial expressions and emotions inside Deep Learning for Computer Vision with Python. Be sure to take a look!
Just another awesome Tutorial, thanks for sharing! 🙂
was waiting for this, the whole time.
can you upload a tutorial based on OpenFace, please ?
Sure, I will certainly consider this for a future tutorial.
Thanks for this tutorial , I have asked you this question and I haven’t got reply.
how the face landmarks can be more stable , I tried the tutorial and the points are shaky
Hi Tony — I’m not sure what you mean by “shaky”. The facial landmark predictor included by dlib is pre-trained. You could try to train your own predictor on your own data to see if that improves your result.
Thanks , I mean the landmark points are not stable ( shaking) . How can I train new predictor for more than 68 landmarks ?
You would need to use the dlib library. This example demonstrates how to train a custom shape predictor.
Hi …how can i set up Dlib on visualstudio 2012 or other version?
Hi Carlos — I only cover how to install dlib on Linux, macOS, and Raspbian on this blog. Setting up dlib on Windows or other Microsoft products is not covered. For that, I would suggest looking at the official dlib website.
Hi Adrian,
Thanks for another awesome tutorial.
I noticed that you convert the image frame to grayscale before passing to the Dlib face detector. I’m assuming it was for speeding up the face detection process. Am I correct?
If we pass a color image to the Dlib face detector, would it detect faces better while being slower (i.e. detection accuracy will be high because more feature data will be available), or have the Dlib face detector designed to work better with grayscale images?
Thanks,
It really depends on the underlying HOG + Linear SVM implementation. Dalal and Triggs (the authors of the original HOG paper) found that computing the gradient over multiple channels and taking the maximum response can increase detection accuracy. The problem is that you end up computing the gradient representation for each channel which makes the detection pipeline slower. In this case I like to explicitly convert to grayscale for speed.
Great stuff! How hard would it be to extract pose data (head pitch, yaw, & roll) from the features here? Thanks!
I m getting error mentioned below when executing above program of real-time facial landmark detection:
File “video_facial_landmarks.py”, line 22, in
predictor = dlib.shape_predictor(args[“shape_predictor”])
RuntimeError: Unable to open shape_predictor_68_face_landmarks.dat in ubuntu 16.04
Please help.
Thanks in advance
Make sure you use the “Downloads” section of this guide to download the source code + facial landmark predictor file. The issue is that you do not have this .dat file.
Hi Adrian!
I downloaded the .dat file (the zip’s unzipped and everything) and yet I am still receiving the same error 🙁 How should I go about this?
Your path to the inputmake sure you read this tutorial first.
Hi Adrian,
Thanks a lot for your amazing work !
I wondered if you have any idea regarding what would be the best way to go in order to create a legs detection algorithm ?
Thanks for your help,
Alex
Hi Alex — I would suggest training your own custom HOG + Linear SVM object detector. I demonstrate how to code and train the detector inside the PyImageSearch Gurus course.
Hi Adrian – thanks for your great work – kudos 🙂
I’m stuck and I thought I’ll ask for your help.
Installed opencv and dlib successfully.
site-packages are symliked to my virtualenv as well.
when I run (i’m working within my virtualenv at this point and the files are located within /Documents/cv)
python video_facial_landmarks.py \
–shape-predictor shape_predictor_68_face_landmarks.dat \
–picamera 1
throws the following error
File “/home/pi/.virtualenvs/facecam/lib/python3.4/site-packages/imutils/video/pivideostream.py”, line 2, in from picamera.array import PiRGBArray
ImportError: No module named ‘picamera’
Update – figured out the problem here –
forgot this~
pip install “picamera[array]”
but have another problem at hand~
(Frame:1158): Gtk-warning **:cannot open display:
update – was running the script from CLI
Once I rebooted the system with pixel GUI enabled – it worked 🙂
Congrats on resolving the issue Vinod 🙂
Hi Adrian,
I referred your above article, it works perfectly fine on my face image as well.
I wanted to use this facial landmark detected image and match with it my other image which I have placed in train folder (Face Recognition)
How can I effectively match these landmark features between two images?. I tried your existing LBP recognition code (Local Binary Patterns with Python & OpenCV) but the results are poor.
https://pyimagesearch.com/2015/12/07/local-binary-patterns-with-python-opencv/
Do you have any opencv code which can effectively recognize images based on facial landmarks?
I would be very grateful if you could help me in this regard and if I could successfully complete this assignment, I will surely enroll myself for pyimagesearch gurus.
Regards
Wenliangh Wang
Facial landmarks are not used for face recognition. Instead, you would use algorithms such as Eigenfaces and LBPs for face recognition. These face recognition algorithms are covered inside the PyImageSearch Gurus course.
Can we use this for detection of hand landmarks ?
You would need to train a custom landmark predictor for hand landmarks, but yes, it is possible.
Hi, I’m trying to run the program on mac, but it is giving me an illegal instruction: 4 error. I’m not accustomed to mac and I don’t know if there’s a way to fix this. Thanks!
Hello Adrian
I would like to ask on where to place the “shape_predictor_68_face_landmarks.DAT” file because upon running the “video_facial_landmarks.py” file im getting the error of
usage: video_facial_landmarks.py [-h] -p SHAPE_PREDICTOR [-r PICAMERA]
video_facial_landmarks.py: error: argument -p/–shape-predictor is required
You can place the .dat file anywhere you like on your machine. You need to specify the path to it via command line arguments. I would suggest you read up on command line arguments and how they work before proceeding.
Hi Adrian, can you explain little bit more, what I should to change to use recorded video file instead of live cam?
If you’re using a recorded video you can simply specify the file path to
cv2.VideoCaptureor use the FileVideoStream class.I just simply changed vs = VideoStream(usePiCamera=args[“picamera”] > 0).start() to vs = FileVideoStream(“rt.wmv”).start() but it doesnt help ( Can you explait what to do little bit more? Thank you.
I’m not sure what you mean by “it doesn’t help”. Are you getting an error message? Does the script automatically exit? The more insight you can provide the better chance that myself or other PyImageSearch readers will be able to help you.
I just see this message:
[INFO] camera sensor warming up…
And no autoexit.
I would suggest double-checking that OpenCV has access to your webcam. It sounds like OpenCV cannot access your webcam and gets stuck in a loop.
I solve the problem, just reinstalled ubuntu opencv dlib and also add 8gb ram to the project. And it works great! Thank you Adrian for great job!
Congrats on resolving the issue, Igor. Nice job.
Hi Adrian, I keep getting “corrupt JPEG data: extraneous bytes” error message when I run the program.
The program seems to be working fine but I keep getting this error
Thanks!
If you’re getting that error message when trying to read frames from your webcam, either (1) there is a problem with your webcam or (2) you’re missing some video codecs. Without access to your machine, I don’t know what the true problem is. Unfortunately, you might want to consider re-installing your OS and compiling OpenCV from scratch.
Hi Adrian. First of all, thank you so much for this invaluable resource and very detailed and well explained tutorials.
I’m currently running this configuration on a raspberry pi 3. Everything works as expected with the exception of a very low frame-rate. I get about 1 frame every 2 seconds.
Is this a limitation of the pi 3 hardware or is there a chance that if I put a bit of effort into optimising what I’m doing I could get 12fps or above?
It’s a limitation of the Raspberry Pi hardware. Swap out Haar cascades for the the default HOG + Linear SVM face detector. Skip frames are also useful. I’ll be covering how to do both of these in a future blog post.
Great thank you!
I was under the impression that we were already using HOG + Linear SVM in this one.
# initialize dlib's face detector (HOG-based) and then create # the facial landmark predictor print("[INFO] loading facial landmark predictor...") detector = dlib.get_frontal_face_detector() predictor = dlib.shape_predictor(args["shape_predictor"])or am I misunderstanding what you mean to swap out?
My apologies, I meant to swap the order in my previous comment. You are correct, this post already uses HOG + Linear SVM provided by dlib. Swap out the HOG + Linear SVM for the face detection Haar cascades provided by OpenCV. They will be less accurate, but faster.
Hello
Thank you for the tutorials
I did it but the speed of the camera frames is very slow and there is a lot of delay
What should I do?
In addition,
I used the raspberry camera
Make sure you are using threading to increase the throughput of your Raspberry Pi camera.
hi again
i read https://pyimagesearch.com/2015/12/28/increasing-raspberry-pi-fps-with-python-and-opencv/ and https://pyimagesearch.com/2016/01/04/unifying-picamera-and-cv2-videocapture-into-a-single-class-with-opencv/
but i dont know use them in my Real-time facial landmark detection with OpenCV, Python, and dlib code to increse my pi camer frame
please help and save me from slowly an delay frame
thank u
🙂
Excellent tutorials, really appreciate it. Do you know if it would be possible to implement this on android ?
Yes, you can certainly apply this method to Android or iOS; however, I am not an Android developer. If you are looking for an Android + OpenCV developer I would suggest posting your project on PyImageJobs.
Please help me to install SciPy and Scikit image installation in windows 10 64-bit
Windows installation instructions are provided in the scikit-image documentation.
Hello Adrian, I execute
/home/pi/Desktop/video_facial_landmarks.py –shape predictor shape_predictor_68_face_landmarks.dat –picamera 1
and
/home/pi/Desktop/video_facial_landmarks.py –shape predictor /home/pi/Desktop/shape_predictor_68_face_landmarks.dat –picamera 1
But I’m getting this error (In both cases):
.
usage: video_facial_landmarks.py [-h] -p SHAPE_PREDICTOR [-r PICAMERA]
video_facial_landmarks.py:error: unrecognized arguments: shape_predictor_68_face_landmarks.dat
.
.
I have the files (.dat and .py) saved in /home/pi/Desktop/ . The same files we can get from the download section
.
I love your tutorials
Thanks!!!!
Sorry, I was wrong, I corrected it: I was writing –shape predictor, it should be –shape-predictor, but now, when I execute:
python /home/pi/Desktop/video_facial_landmarks.py –shape-predictor /home/pi/Desktop/shape_predictor_68_face_landmarks.dat
It shows me
[INFO] loading facial landmark predictor…
[INFO] camera sensor warming up…
Traceback (most recent call last):
…
ImportError: No module named ‘picamera’
I dont know why
I give up 🙁
You haven’t installed the
picameramodule you:$ pip install picameraIf you are using the “cv” Python virtual environment access it first and then install:
Ok, thank you, I thought it wasnt necessary because I made some examples that uses a script to access the raspberry camera
No, you need the
picameramodule to use theVideoStreamclass and the Raspberry Pi camera module. As long as you havepicamerainstalled you’ll be good to go.Hello Adrian ! thank you for this great tutorial 🙂
I’m having an issue every time i run the sketch i get this error even though i have upgraded imutils to the latest version . Thank you in advance if you figure out whats the issue 🙂
File “/home/pi/Desktop/video_facial_landmarks.py”, line 6, in
from imutils.video import VideoStream
ImportError: No module named ‘imutils’
You need to install the
imutilslibrary:$ pip install imutilsIf you are using Python virtual environments:
Hi Adrian, the dlib and the new deep learning series are great!
I’d like to report for a strange behavior regarding the threaded part, using Python 3.6.1 – the console window hangs after quitting. Last lines are executed, the camera turns off, but control is not returned to the console.
– It hangs also when there is an exception after VideoStream.start()
– Putting an explicit “exit()” after the last line doesn’t help.
– Strangely *sometimes*/rarely it did end smoothly…
Reverting to conventional sampling fixed it for me:
vs = cv2.VideoCapture(0)
…
ret, frame = vs.read()
Best Regards
This does indeed sound like a threading problem. Thanks for sharing, Todor!
I’ve just checked the drowsiness detector and the same thing happened, so I tried to debug it.
The bug was gone after changing WebcamVideoStream’s thread daemon property to False:
def start(self):
# start the thread to read frames from the video stream
t = Thread(target=self.update, args=())
t.daemon = False
…
For the record I’m using Windows 10… :-]
Good staff, Adrian!
Is it possible to detect facial landmarks from a part of image?
For example, how to get a landmarks for lip of the bottom part of the face?
Provided you can detect the entire face you can use array slices to extract arbitrary points. See this post for more details.
anyone else having problem with detecting wide open mouths? the mouth points are way off
Hi Adrian
When you read from VideoStream, what is the exact format of the “frame” ? (@ line 35)
Can we temporarily store this as png or jpeg format ?
Hi Shaun —
frameis a NumPy array. You can write it to disk withcv2.imwrite("filename.png", frame). This is covered in Practical Python and OpenCV + Case Studies Chapter 3.Thank you so much Adrian–
Everything goes smoothly but then it opens a frame that is blank and in the terminal prints: select timeout numerous times
—–
—Please HELP!!
It sounds like Python/OpenCV is having trouble accessing your video stream. What type of camera are you using? Are you using a normal computer? Or a Raspberry Pi?
Im using a normal computer not rasberry pi. Anyone who can help please…
If you are using a normal computer it sounds like OpenCV cannot access your webcam. Can other software on your computer properly access your webcam?
Hello, very good post, but I have a problem with imutils, when I put it in the example it tells me that there is no module called imutils, and probe with pip freeze and I have version 0.4.3, what can I do?
That is indeed very strange. It sounds like your “python” version and “pip” version do not match up. Make sure the “pip” you used to install imutils matches your Python version.
Hello Adrian! First of all, thank you so much for your tutorials, they are great!
Second, I want to ask you for some help: I’m having issues running the code since the follow error appears when I run it.
File “/home/ad/.virtualenvs/cv/local/lib/python2.7/site-packages/imutils/convenience.py”, line 69, in resize
(h, w) = image.shape[:2]
AttributeError: ‘NoneType’ object has no attribute ‘shape’
What can I do?
Thank you so much in advance!
It looks like OpenCV cannot access your webcam and is returning “None” for the frame. I discuss these errors and how resolve them in this post.
Hi Adrian,
is there a way (model) we can use to perform a face detection with movidius?
I’m trying both haar and hog (dlib) but on the pi we can’t reach a good fps.
You would need a Caffe/TensorFlow model that performs face detection. Provided you have one, yes, you can run it on the Movidius. A good starting point would be this post. Additionally, I discuss face detection speed/accuracy tradeoff on this post.
Hello Adrian!
First of all, thank you for all the content in the blog, you helped me a lot! I need to track the pupils of the both eyes, do you have any tips for this implemention? I’m really stuck on this part of the algorithm.
Thank you again for sharing all your knowledge!
I do not have any tutorials on pupil detection but I know some PyImageSearch readers have had good luck with this tutorial.
Thank you Adrian, have a great week
Thank you Matheus 🙂
Hi Adrian
I got this mistake. Can you help me ?
usage: detect_face_parts.py [-h] -p SHAPE_PREDICTOR -i IMAGE
detect_face_parts.py: error: the following arguments are required: -p/–shape-predictor, -i/–image
Please see this post on command line arguments. It’s an easy fix but make sure you read the post to understand how to use command line arguments.
Hey man,
I’m getting an error like,
AttributeError: module ‘cv2’ has no attribute ‘INTER_AREA’
Please help me…
I desperately need this…
Please reply soon
Hey Rohith — it’s odd that your “cv2” module does not have the “INTER_AREA” attribute. How did you install OpenCV? And which OpenCV version are you using?
Hi Adrian,
I don’t know what it is, but i got this error and in internet i didn’t find any solution yet.
[INFO] loading facial landmark predictor…
[INFO] camera sensor warming up…
ASSERT: “false” in file qasciikey.cpp, line 495
Abortado (imagem do núcleo gravada) – this last part is because i’m Brazilian.
The code works fine, but after 2 seconds…
Could you help me please?
Thanks
ap.add_argument(“-p”, “–shape-predictor”, required=True,
help=”path to facial landmark predictor”)
ap.add_argument(“-r”, “–picamera”, type=int, default=-1,
help=”whether or not the Raspberry Pi camera should be used”)
args = vars(ap.parse_args())
what changes i should make in this code?
The code itself does not have to change. Please read this post on command line arguments.
Thank you Adrian
Hi Adrian,
Thanks for such a great work!
I tried to put different face coordinates with another face detection method to the “rect”. But the face landmarks are not working properly when I rotate my face a bit. They slip a lot and get very shaky. How can I solve it?
I’m not sure what you mean by “put different face coordinates with another face detection method”. Could you elaborate?
I mean I used OpenCV library to detect faces, not the dlib library. Than I converted the coordinates of detected faces to the dlib rectangle class. But I couldn’t get satisfying result. I don’t have any problem with detecting faces however, as mentioned above, landmarks are not overlapping with the correct face landmarks when I rotate my face a bit.
I guess the ‘predictor’ method is suffering from detected face rectangle coordinates.
Got it. Are you sure you are converting the coordinates correctly? Take a look at this blog post where I use an OpenCV Haar cascade to detect faces and then convert them to a dlib rectangle object.
Hello Sir,
You have done excellent work here. Thank You so much. Your code is very easy to understand.
I have just had a question .. What exactly is landmark predictor file here. Did you code it (and is there a blog for that) or is it dlib’s standard library file??.
It was trained using the dlib library and provided by the dlib creator, Davis King.
Hi Adrian,
Thanks a lot for your amazing work !
I have just had a question ..How to enlarge the output frame?
You can use the
cv2.resizeorimutils.resizefunction to resize images/frames. If you’re new to the world of computer vision and image processing I would suggest working through Practical Python and OpenCV so you can learn the fundamentals very quickly. Be sure to check it out, I think it will really help you!Hi Adrian, I have a question can we track all the 68 points of the facial landmark after detection to increase the fps count.
I’m not sure what you mean by tracking them in between frames. Running the actual facial landmark detector after the face has been detected is super fast. You may want to skip face detection and instead apply a Kalman filter, that could help.
Hi Adrian. Great job. I am working on a robot project. i need to turn the robot left and right directions if we turn our head like that. how can i add head pose into this tutorial ?
Thanks
Hey Vaisakh — I don’t have any tutorials related to moving an arm/servo based on real-world coordinates but I will try to do one in the future.
Hello! Adrian. My name is Kyungwon Lee. I always appreciate your post. This post, as well as other posts, really helped me a lot. I am studying to prevent drowsiness by looking at your post now. In your post you are only judging your drowsiness with your eyes, but if I can not find your face first, I will let you know with a buzzer. So I came to refer to this post. But I do not know if I can refer to some posts. So I was asked this question. First, I think you should use conditional statements to make the buzzer sound when you can not find your face. But I do not know which conditional statement to use. Please teach me. Using a translator can make strange words. Say thank you again.
Hi Kyungwon, thanks for the comment. I wouldn’t sound the buzzer if a face cannot be found immediately. You may want to consider only sounding the buzzer after N frames (where N is a pre-defined value). Otherwise, the buzzer will sound every time the face detector fails to find a face which can happen intermittently depending on viewing angle, lighting conditions, etc.
Thank you Dr Adrian for making such contributions towards free education…
Thanks Faraz 🙂
Hi Adrian,
super grateful for the posts, they have helped me a lot ! I am using the landmark detection in live video where the common situation is not a frontal face one. Do you know of any pre-trained face landmark detectors that can adapt to those kinds of situations, i.e. both frontal, profile and tilted?
Hi Adrian,
I’m working on a project where a robot has to detect a face and trace the face, I used part of your code and it works fine but what can I do if I just want to detect only 1 face although there are more than 2 faces in front of the camera, I want to detect only the first face that appears.
Could you help me?
Thanks in advance and really nice job with all the tutorials!
How are you defining the “first” face? Is it the first face that appears in front of the camera? The largest face in view of the camera? The face with the largest corresponding predicted probability?
Hi Adrian,
your tutorial is really great. I’m working on a project to detect lies through facial landmarks. what i want to know is the camera you are using , is it a thermal camera? can i try this with a normal DSLR camera? i want do detect only facial landmarks when a person is lying.
Thanks in advance
I was using both:
1. The built-in webcam on my MacBook Pro
2. A Logitech C920
As far as lie detection goes, have you created your initial dataset first? That would be the first step.
Hello Adrian,
Amazing work and thanks for helping people throughout the world.
I’m working on a project which records the amount of time a person smiles, raises his eyebrows etc in a given video.
Is there a way in which I can save the movements and calculate the total time a person smiles from a video?
P.S I’m very new to the world of CV.
If you’re new to the world of computer vision and image processing I would recommend reading through Practical Python and OpenCV. Your project is absolutely doable but you need to know the fundamentals first.
hi adrian, after running the program, it only shows “camera sensor warmining up” and showing the camera or allowing me to exit . 🙁
Are you using a Raspberry Pi camera or a USB webcam?
Hello, can we apply the very same code for any other object detection ?
Object detection and facial landmark detection are two different types of algorithms so I’m not sure I understand your question. Could you elaborate?
Adrian,
Thank you for an excellent set of articles.
Not sure if you are still around monitoring feedback given it is 2 years down the track.
I have a question in regards to this and in particular to an Android environment.
a) the loading of the face_landmarks_68.dat is “very” slow. Do you happen to know of a more efficient/faster way of loading this up ? A different more optimized file or method etc etc ?
b) the actual detection is quite slow also. Do you happen to know of any tricks that can be used in Android (Studio environment) that would speed things up ?
Cheers
1. Yes, there is a smaller, 5-point facial landmark model.
2. Sorry, I don’t have any experience with Android.
Adrian,
I have a question about how to use OpenCV to calculate the number of objects.And which technique should be used.
What types of objects are you trying to detect?
Hello,
Thank u! awesome post!
I implemented this and it works. But i have a camera with a high resolution (2048*1536) so I did some downsampling to have a smaller image because (of course) it was too slow.
The landmarks now are OK in terms of speed, but i think I could do better if I track them and only detect them when necessary,
Do you know any way to check if the landmarks “make sense” (it has the shape of a human face) so that I update the tracking with a new detection?
The facial landmark computation is actually very fast, it’s likely the face detection that’s slowing you down. Instead, only perform face detection every N frames.
Hi Adrian,
Maybe it is a stupid question, but why haven’t we used a pre-trained Caffe deep neural network model for face detection? Is it only because it is more computationally intensive than dlib HOG stuff you applied?
Take a look at the publish dates of the tutorials you’re referring to. This blog post was published well before OpenCV’s DNN face detector was created. Had that face detector been available I would have likely used it. That said, a DNN face detector is more computationally intensive than HOG.
Hello
I’m using a logitech webcam in windows 10 to detect face.
Can you tell me how can i set the same using the above code.
Provided you have OpenCV and dlib installed on your system the code will work on Windows.
Hi Adrian,
Firstly, thank you so much for this kickass crash course. It is absolutely fantastic.
I am using this code for face detection from a network camera, the code works and displays the image from the camera, however, at a specific point it returns a None type for the frame and subsequently stops the program.
I saw your post on how to prevent NoneType errors, but could not find a solution to this specific problem – please help.
Do you think it’s because the program is losing connection with the camera briefly therefore not being able to access the image?
It’s likely that a frame is being dropped. Check if the frame is “None” and then “continue” in the loop rather than doing a “break” from it.
Hi Adrian,
Thank you for this great tutorial. I’d like to know if is there a way to get the face landmark coordinates of the file video without have to reproduce it.
Hi Adrian,
can it be used ip camera for this example?
Absolutely, but I would recommend you use imagezmq.
Hi Adrian,
Thank you for the great tutorials. I learned a lot.
Last days I am trying to find some solutions when facial landmark points are not stable (jittering on realtime vide/camera) and still not figured out.
Please, can you give us some suggestions?
I would recommend stabilizing them using optical flow.