In the next couple of blog posts we are going to train a computer vision + deep learning model to perform facial recognition…
…but before we can train our model to recognize faces in images and video streams we first need to gather the dataset of faces itself.
If you are already using a pre-curated dataset, such as Labeled Faces in the Wild (LFW), then the hard work is done for you. You’ll be able to use next week’s blog post to create your facial recognition application.
But for most of us, we’ll instead want to recognize faces that are not part of any current dataset and recognize faces of ourselves, friends, family members, coworkers and colleagues, etc.
To accomplish this, we need to gather examples of faces we want to recognize and then quantify them in some manner.
This process is typically referred to as facial recognition enrollment. We call it “enrollment” because we are “enrolling” and “registering” the user as an example person in our dataset and application.
Today’s blog post will focus on the first step of the enrollment process: creating a custom dataset of example faces.
In next week’s blog post you’ll learn how to take this dataset of example images, quantify the faces, and create your own facial recognition + OpenCV application.
To learn how to create your own face recognition dataset, just keep reading!
How to create a custom face recognition dataset
In this tutorial, we are going to review three methods to create your own custom dataset for facial recognition.
The first method will use OpenCV and a webcam to (1) detect faces in a video stream and (2) save the example face images/frames to disk.
The second method will discuss how to download face images programmatically.
Finally, we’ll discuss the manual collection of images and when this method is appropriate.
Let’s get started building a face recognition dataset!
Method #1: Face enrollment via OpenCV and webcam
This first method to create your own custom face recognition dataset is appropriate when:
- You are building an “on-site” face recognition system
- And you need to have physical access to a particular person to gather example images of their face
Such a system would be typical for companies, schools, or other organizations where people need to physically show up and attend every day.
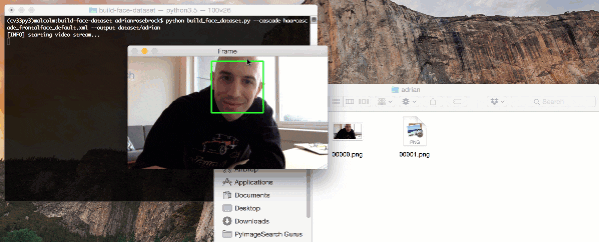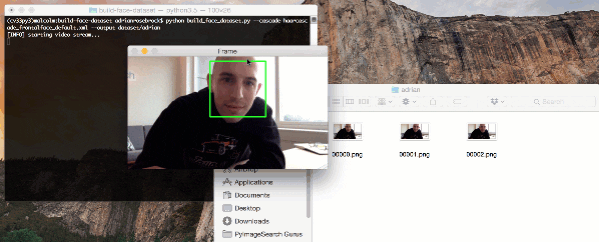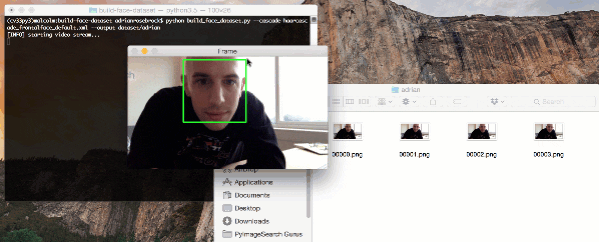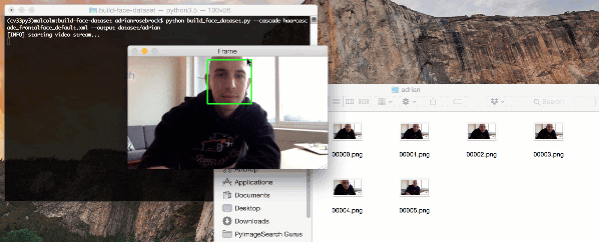
To gather example face images of these people, we may escort them to a special room where a video camera is setup to (1) detect the (x, y)-coordinates of their face in a video stream and (2) write the frames containing their face to disk.
We may even perform this process over multiple days or weeks to gather examples of their face in:
- Different lighting conditions
- Times of day
- Moods and emotional states
…to create a more diverse set of images representative of that particular person’s face.
Let’s go ahead and build a simple Python script to facilitate building our custom face recognition dataset. This Python script will:
- Access our webcam
- Detect faces
- Write the frame containing the face to disk
To grab the code to today’s blog post, be sure to scroll to the “Downloads” section.
When you’re ready, open up build_face_dataset.py and let’s step through it:
# import the necessary packages from imutils.video import VideoStream import argparse import imutils import time import cv2 import os
On Lines 2-7 we import our required packages. Notably, we need OpenCV and imutils .
To install OpenCV, be sure to follow one of my installation guides on this page.
You can install or upgrade imutils very easily via pip:
$ pip install --upgrade imutils
If you are using Python virtual environments don’t forget to use the workon command!
Now that your environment is set up, let’s discuss the two required command line arguments:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--cascade", required=True,
help = "path to where the face cascade resides")
ap.add_argument("-o", "--output", required=True,
help="path to output directory")
args = vars(ap.parse_args())
Command line arguments are parsed at runtime by a handy package called argparse (it is included with all Python installations). If you are unfamiliar with argparse and command line arguments, I highly recommend you give this blog post a quick read.
We have two required command line arguments:
--cascade: The path to the Haar cascade file on disk.--output: The path to the output directory. Images of faces will be stored in this directory and I recommend that you name the directory after the name of the person. If your name is “John Smith”, you might place all images indataset/john_smith.
Let’s load our face Haar cascade and initialize our video stream:
# load OpenCV's Haar cascade for face detection from disk
detector = cv2.CascadeClassifier(args["cascade"])
# initialize the video stream, allow the camera sensor to warm up,
# and initialize the total number of example faces written to disk
# thus far
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
# vs = VideoStream(usePiCamera=True).start()
time.sleep(2.0)
total = 0
On Line 18 we load OpenCV’s Haar face detector . This detector will do the heavy lifting in our upcoming frame-by-frame loop.
We instantiate and start our VideoStream on Line 24.
Note: If you’re using a Raspberry Pi, comment out Line 24 and uncomment the subsequent line.
To allow our camera to warm up, we simply pause for two seconds (Line 26).
We also initialize a total counter representing the number of face images stored on disk (Line 27).
Now let’s loop over the video stream frame-by-frame:
# loop over the frames from the video stream while True: # grab the frame from the threaded video stream, clone it, (just # in case we want to write it to disk), and then resize the frame # so we can apply face detection faster frame = vs.read() orig = frame.copy() frame = imutils.resize(frame, width=400) # detect faces in the grayscale frame rects = detector.detectMultiScale( cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY), scaleFactor=1.1, minNeighbors=5, minSize=(30, 30)) # loop over the face detections and draw them on the frame for (x, y, w, h) in rects: cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
On Line 30 we begin looping (this loop exits when the “q” key is pressed).
From there, we grab a frame , create a copy, and resize it (Lines 34-36).
Now it’s time to perform face detection!
Using the detectMultiScale method we can detect faces in the frame . This function requires a number of parameters:
image: A grayscale imagescaleFactor: Specifies how much the image size is reduced at each scaleminNeighbor: Parameter specifying how many neighbors each candidate bounding box rectangle should have in order to retain a valid detectionminSize: Minimum possible face image size
Unfortunately, sometimes this method requires tuning to eliminate false positives or to detect a face at all, but for “close up” face detections these parameters should be a good starting point.
That said, are you looking for a more advanced and more reliable method? In a previous blog post, I covered Face detection with OpenCV and deep learning. You could easily update today’s script with the deep learning method which uses a pre-trained model. The benefit of this method is that there are no parameters to tune and it is still very fast.
The result of our face detection method is a list of rects (bounding box rectangles). On Lines 44 and 45, we loop over rects and draw the rectangle on the frame for display purposes.
The last steps we’ll take in the loop are to (1) display the frame on the screen, and (2) to handle keypresses:
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `k` key was pressed, write the *original* frame to disk
# so we can later process it and use it for face recognition
if key == ord("k"):
p = os.path.sep.join([args["output"], "{}.png".format(
str(total).zfill(5))])
cv2.imwrite(p, orig)
total += 1
# if the `q` key was pressed, break from the loop
elif key == ord("q"):
break
On Line 48, we display the frame to the screen followed by capturing key presses on Line 49.
Depending on whether the “k” or “q” key is pressed we will:
- Keep the
frameand save it to disk (Lines 53-56). We also increment ourtotalframes captured (Line 57). The “k” key must be pressed for eachframewe’d like to “keep”. I recommend keeping frames of your face at different angles, areas of the frame, with/without glasses, etc. - Exit the loop and prepare to exit the script (quit).
If no key is pressed, we start back at the top of the loop and grab a frame from the stream.
Finally, we’ll print the number of images stored in the terminal and perform cleanup:
# print the total faces saved and do a bit of cleanup
print("[INFO] {} face images stored".format(total))
print("[INFO] cleaning up...")
cv2.destroyAllWindows()
vs.stop()
Now let’s run the script and collect faces!
Be sure that you’ve downloaded the code and Haar cascade from the “Downloads” section of this blog post.
From there, execute the following command in your terminal:
$ python build_face_dataset.py --cascade haarcascade_frontalface_default.xml \ --output dataset/adrian [INFO] starting video stream... [INFO] 6 face images stored [INFO] cleaning up...
After we exit the script we’ll notice that 6 images have been saved to the adrian subdirectory in dataset :
$ ls dataset/adrian 00000.png 00002.png 00004.png 00001.png 00003.png 00005.png
I recommend storing your example face images in a subdirectory where the name of the subdirectory maps to the name of the person.
Following this process enforces organization on your custom face recognition dataset.
Method #2: Downloading face images programmatically
In the case that you do not have access to the physical person and/or they are a public figure (in some manner) with a strong online presence, you can programmatically download example images of their faces via APIs on varying platforms.
Exactly which API you choose here depends dramatically on the person you are attempting to gather example face images of.
For example, if the person consistently posts on Twitter or Instagram, you may want to leverage one of their (or other) social media APIs to scrape face images.
Another option would be to leverage a search engine, such as Google or Bing:
- Using this post you can use Google Images to somewhat manually + and somewhat programmatically download example images for a given query.
- A better option, in my opinion, would be to use Bing’s Image Search API which is fully automatic and does not require manual intervention. I cover the fully automatic method in this post.
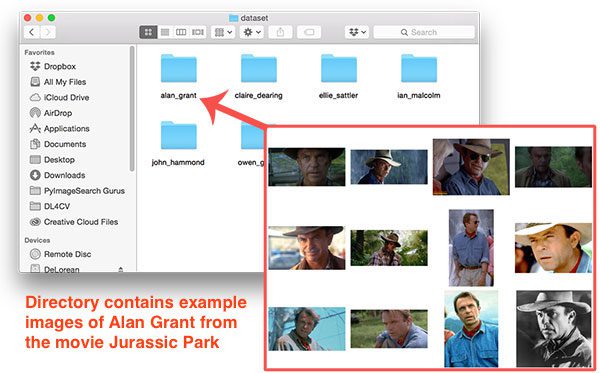
Using the latter method I was able to download 218 example face images from the cast of Jurassic Park and Jurassic World.
An example command for downloading face images via the Bing Image Search API for the character, Owen Grady, can be seen below:
$ mkdir dataset/owen_grady $ python search_bing_api.py --query "owen grady" --output dataset/owen_grady
And now let’s take a look at the whole dataset (after pruning images that do not contain the characters’ faces):
$ tree jp_dataset --filelimit 10 jp_dataset ├── alan_grant [22 entries] ├── claire_dearing [53 entries] ├── ellie_sattler [31 entries] ├── ian_malcolm [41 entries] ├── john_hammond [36 entries] └── owen_grady [35 entries] 6 directories, 0 files
In just over 20 minutes (including the amount of time to prune false positives) I was able to put together my Jurassic Park/Jurassic World face dataset:

Again, be sure to refer to this blog post to learn more about using the Bing Image Search API to quickly build an image dataset.
Method #3: Manual collection of face images
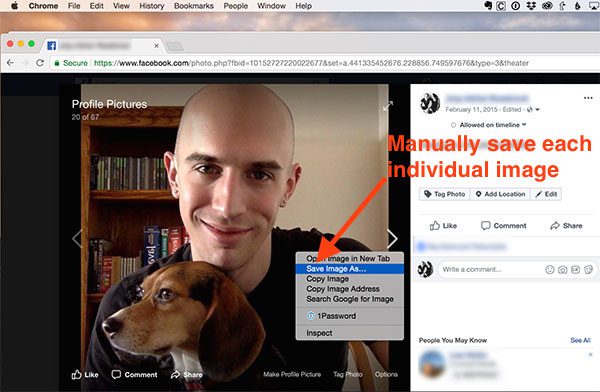
The final method to create your own custom face recognition dataset, and also the least desirable one, is to manually find and save example face images yourself.
This method is obviously the most tedious and requires the most man-hours — typically we would prefer a more “automatic” solution, but in some cases, you’ll need to resort to it.
Using this method you will need to manually inspect:
- Search engine results (ex., Google, Bing)
- Social media profiles (Facebook, Twitter, Instagram, SnapChat, etc.)
- Photo sharing services (Google Photos, Flickr, etc.)
…and then manually save these images to disk.
In these types of scenarios, the user often has a public profile of some sort but significantly fewer images to crawl programmatically.
What's next? We recommend PyImageSearch University.

86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: June 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In today’s blog post we reviewed three methods to create our own custom dataset of faces for the purpose of facial recognition.
Exactly which method you choose is highly dependent on your own facial recognition application.
If you are building an “on-site” face recognition system, such as one for a classroom, business, or other organization, you’ll likely have the user visit a room you have dedicated to gathering example face images and from there proceed to capture face images from a video stream (method #1).
On the other hand, if you are building a facial recognition system that contains public figures, celebrities, athletes, etc., then there are likely more than enough example images of their respective faces online. In this case, you may be able to leverage existing APIs to programmatically download the example faces (method #2).
Finally, if the faces you trying to recognize do not have a public profile online (or the profiles are very limited) you may need to resort to manual collection and curation of the faces dataset (method #3). This is obviously the most manual, tedious method but in some cases may be required if you want to recognize certain faces.
I hope you enjoyed this post!
Go ahead and start building your own face datasets now — I’ll be back next week to teach you how to build your own facial recognition application with OpenCV and computer vision.
To be notified when next week’s face recognition tutorial goes live, just enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

