
Table of Contents
- Synthetic Data Generation Using the VLM-as-Judge Method
- Configuring Your Development Environment
- Set Up and Imports
- Downloading Images Locally
- Using Qwen as VLM-as-Judge
- Converting the JSON File to the Hugging Face Dataset Format
- Inspecting the Dataset
- Pushing the Dataset to the Hugging Face Hub
- Summary
Synthetic Data Generation Using the VLM-as-Judge Method
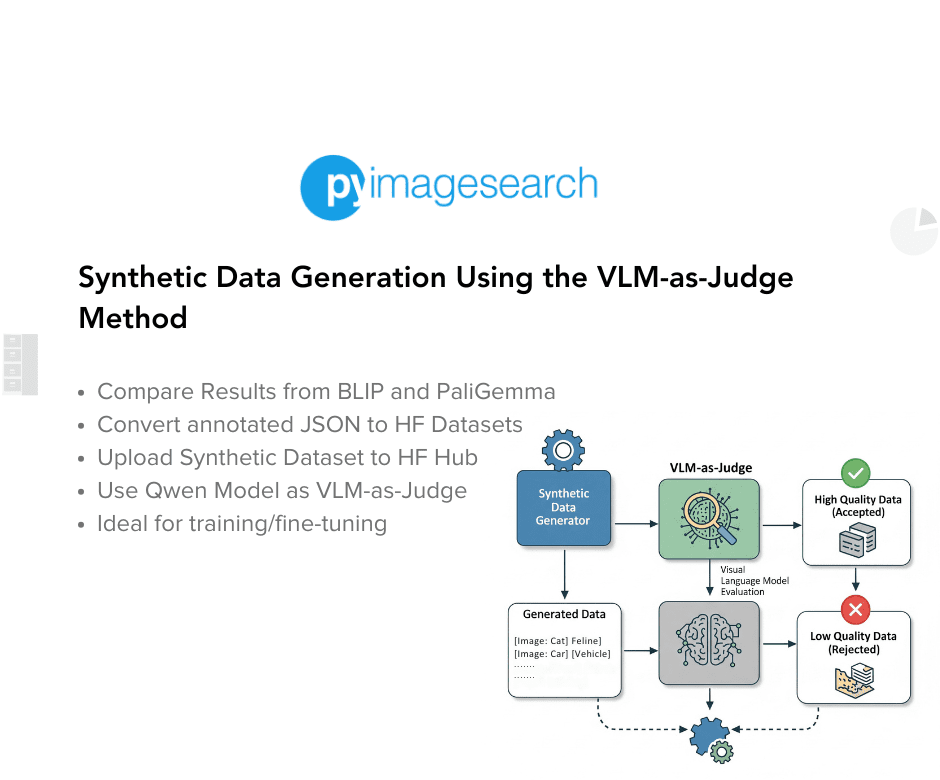
In Part 1, we generated two synthetic VQA datasets using the BLIP (Bootstrapping Language-Image Pre-training) and PaliGemma models, laying the groundwork for our VLM-as-Judge pipeline. In this Part 2 tutorial, we’ll show how to use the Qwen model as our judge: it will compare BLIP’s and PaliGemma’s answers for each image-question pair and select the best one. By the end, we’ll have a curated synthetic VQA dataset with the highest-quality annotations.
This lesson is the last in a 2-part series on Building a Synthetic Dataset Using the VLM-as-Judge Method:
- Synthetic Data Generation Using the BLIP and PaliGemma Models
- Synthetic Data Generation Using the VLM-as-Judge Method (this tutorial)
To learn how to use the Qwen model as a VLM-as-Judge model to create a final synthetic VQA dataset, just keep reading.
How would you like immediate access to 3,457 images curated and labeled with hand gestures to train, explore, and experiment with … for free? Head over to Roboflow and get a free account to grab these hand gesture images.
Configuring Your Development Environment
To follow this guide, you need to have the following libraries installed on your system.
!pip install -q -U transformers datasets
We install transformers to load the Qwen model and its associated processors and datasets for loading and handling the dataset.
Need Help Configuring Your Development Environment?

All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code immediately on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Set Up and Imports
Once installed, we import the required dependencies.
import os import json import torch from PIL import Image from tqdm import tqdm from transformers import AutoProcessor, AutoModelForVision2Seq from datasets import load_dataset, Dataset, Features, Value, Image
We import the following:
os: to create directories, list files, and build file pathsjson: to serialize model outputs into JSON files and deserialize them for dataset constructiontorch: to leverage tensor operations under the hoodtqdm: to display progress bars during long-running loopsImagefromPIL: to open and manipulate images
From the transformers library, we import the following:
AutoProcessor: to preprocess paired image-and-text inputs for the Qwen modelAutoModelForVision2Seq: to load and generate answers with the Qwen model
From the datasets library, we import load_dataset to pull existing Hugging Face datasets, Dataset to build custom datasets from Python lists, Features, Value, and Image to define the schema, ensuring images and text fields are handled correctly.
Downloading Images Locally
The Qwen model needs two things as input:
- images
- text response from the two models created in Part 1
so that the Qwen model can compare the results between the two models and serve as the final judge.
vqav2_small_ds = load_dataset("merve/vqav2-small")
val_ds = vqav2_dataset["validation"]
# Output folder to save images
image_folder = "images"
os.makedirs(image_folder, exist_ok=True)
# Iterate through the dataset and download each image
for i, example in enumerate(tqdm(val_ds, desc="Downloading images")):
image = example["image"]
# Use i or another unique ID if "question_id" isn't available
filename = f"{i}.jpg"
path = os.path.join(image_folder, filename)
image.save(path)
Here, we will first extract the images.
We reuse the same VQAv2 validation split that Part 1 used. By iterating over val_ds, we save each PIL image into our local images/ directory, ensuring all image files are available for Qwen to load.
Using Qwen as VLM-as-Judge
Now, we have all our images. We also need our two JSON files (annotated data from the BLIP and PaliGemma models) that we created in Part 1, which we uploaded to our Colab environment.
Then, we can write a logic to run an inference with the Qwen model to compare the result between the two models and create a final synthetic VQA dataset.
We begin by setting up our environment to run Qwen on GPU when available. We detect CUDA with:
# Use GPU if available (A100)
device = "cuda" if torch.cuda.is_available() else "cpu"
model_id = "Qwen/Qwen2.5-VL-3B-Instruct"
print(f"Loading model {model_id} on {device} ...")
This ensures that if an A100 (or any CUDA-capable GPU) is present, we’ll leverage its speed; otherwise, we fall back to CPU. Immediately after, we load Qwen’s processor and model weights:
processor = AutoProcessor.from_pretrained(model_id) model = AutoModelForVision2Seq.from_pretrained( model_id, torch_dtype=torch.float16 if device == "cuda" else torch.float32 ).to(device)
Here, AutoProcessor handles both text tokenization and image preprocessing, and AutoModelForVision2Seq pulls in Qwen’s vision-language architecture. We choose float16 precision on GPU for memory efficiency or float32 on CPU.
Next, we retrieve the two JSON files produced in Part 1 (i.e., one from BLIP and one from PaliGemma) to compare their outputs. We define a helper function:
# Load BLIP and PaliGemma annotations
def load_json(path):
try:
with open(path) as f:
return json.load(f)
except FileNotFoundError:
print(f"Warning: {path} not found. Continuing with empty data.")
return {}
This safely loads each file or returns an empty dict with a warning if the file is missing. We then call:
blip_data = load_json("synthetic_annotations.json")
pali_data = load_json("vqa_synthetic_annotations.json")
to populate our two data sources.
# Function to compare two answers (0 for BLIP better/equal, 1 for PaliGemma better)
def compare_answers(image, question, blip_ans, pali_ans):
prompt = (
"<|im_start|>user\n"
"<|vision_start|><|image_pad|><|vision_end|>\n"
f"Question: {question}\n"
f"BLIP Answer: {blip_ans}\n"
f"PaliGemma Answer: {pali_ans}\n"
"Compare the two answers in terms of correctness, completeness, and relevance to the image. "
"Respond with a single digit: '0' if BLIP's answer is better or equal, '1' if PaliGemma's answer is better.\n"
"<|im_end|>\n"
"<|im_start|>assistant\n"
)
To let Qwen decide which answer is superior, we implement compare_answers(). Given a PIL image, the question text, and both model answers, it constructs a single prompt containing the image (wrapped in Qwen’s <|vision_start|>…<|vision_end|> tags), the question line, and both answers. We ask Qwen explicitly to output a single digit (i.e., '0' if BLIP’s answer is better or equal and '1' if PaliGemma’s is better):
inputs = processor(text=prompt, images=image, return_tensors="pt")
inputs = {k: v.to(device) for k, v in inputs.items()}
outputs = model.generate(**inputs, max_new_tokens=5)
decoded = processor.batch_decode(outputs, skip_special_tokens=True)[0].strip()
# Extract first digit
for char in decoded:
if char in "01":
return int(char)
print(f"Warning: Unexpected output '{decoded}', defaulting to 0")
return 0
We tokenize this prompt with processor(...), move all tensors to the correct device, and call model.generate(max_new_tokens=5) — enough to get that single digit. We decode the output, strip whitespace, and scan for the first “0” or “1” character. If parsing fails, we default to 0 with a warning.
# Ensure images directory exists
os.makedirs("images", exist_ok=True)
Before processing, we ensure our images/ directory exists (in case someone cleaned it):
# All images
all_images = list(blip_data.keys())
print(f"Testing on {len(all_images)} images: {all_images}")
We then gather all image filenames from the BLIP annotations dict, printing the count and list for sanity.
results = {}
for img in tqdm(all_images, desc="Comparing answers"):
path = os.path.join("images", img)
try:
image = Image.open(path).convert("RGB")
except Exception as e:
print(f"Skipping {img}: {e}")
results[img] = {"error": str(e)}
continue
results[img] = {}
for q, bdata in blip_data.get(img, {}).items():
blip_ans = bdata.get("answer", "").strip()
pali_ans = pali_data.get(img, {}).get(q, "").replace("Answer:\n", "").strip()
if not blip_ans and not pali_ans:
choice = None
elif not pali_ans:
choice = 0
elif not blip_ans:
choice = 1
else:
choice = compare_answers(image, q, blip_ans, pali_ans)
chosen_ans = blip_ans if choice == 0 else pali_ans
source = "blip" if choice == 0 else "paligemma"
results[img][q] = {"choice": choice, "best_answer": chosen_ans, "source": source}
The core comparison loop walks through each image with a tqdm progress bar. For every img name, we open the corresponding file via PIL, convert it to RGB, and initialize results[img] = {}. Then, for each question in blip_data[img], we retrieve blip_ans (stripped) and pali_ans (after removing any “Answer:” markers and trimming whitespace).
- If both answers are empty, we set
choice = None. - If one model’s answer is missing, we automatically pick the other (
choice = 0for BLIP,1for PaliGemma). - Otherwise, we call
compare_answers(image, q, blip_ans, pali_ans)to have Qwen judge them.
We then record under results[img][q] in a dictionary.
This captures both the binary decision and the selected answer text, along with its origin.
# Save results
time= "best_vqa_annotation.json"
with open(time, "w") as f:
json.dump(results, f, indent=2)
print(f"✅ Saved binary comparison results to: {time}")
Finally, we serialize our comparison results to best_vqa_annotation.json.
This file now contains, for every image and question, Qwen’s verdict on which model produced the superior annotation — completing the “judge” step of our pipeline.
NOTE:
- This inference took around 6 hours to run on an A100 GPU.
Converting the JSON File to the Hugging Face Dataset Format
Since we obtained our JSON file, it’s time to convert it to the Hugging Face Dataset Format.
# 1) Load your JSON (change filename as needed)
with open("best_vqa_annotation.json") as f:
nested = json.load(f)
# 2) Flatten into a list of examples
examples = []
for img_name, qa_dict in nested.items():
img_path = os.path.abspath(os.path.join("images", img_name))
for question, info in qa_dict.items():
examples.append({
"image": img_path,
"question": question,
"answer": info["best_answer"],
"source": info["source"],
"choice": info["choice"], # 0 or 1
})
# 3) Define your HF features
features = Features({
"image": Image(), # will load/validate images by path
"question": Value("string"),
"answer": Value("string"),
"source": Value("string"),
"choice": Value("int8"), # small integer 0/1
})
# 4) Build the Dataset
dataset = Dataset.from_list(examples, features=features)
We begin by loading the JSON file that holds Qwen’s binary comparison results. By opening "best_vqa_annotation.json" and calling json.load, we retrieve a nested dictionary where each key is an image filename, and its value is another dict mapping questions to the chosen answer, its source, and the binary choice flag.
Next, we flatten this nested structure into a list of examples that the Hugging Face Dataset API can consume. We initialize an empty list named examples and iterate over each img_name, qa_dict pair in the loaded JSON.
For each image, we compute the absolute path with os.path.abspath(...) so that downstream consumers can load the image by file path. Then, for each question, info entry, we append a dictionary containing "image", "question", "answer" set to info["best_answer"], "source" set to info["source"], and "choice" set to info["choice"] (0 or 1). This ensures every example carries both the text and metadata about which model won.
With our examples list ready, we explicitly define the dataset schema via a Features object. We declare "image" as Image() so the library will validate and load each image file, "question" and "answer" as Value("string") for text fields, "source" as Value("string") to record which VLM produced the best annotation, and "choice" as Value("int8") for the small integer flag. This schema ensures our dataset is strongly typed and self-describing.
Finally, we call Dataset.from_list(...) to instantiate a Hugging Face Dataset. This step binds our flattened examples to the defined schema, yielding a ready-to-use, version-controlled dataset that mixes image data with question, answer, source, and choice fields — all curated by our VLM-as-Judge pipeline.
Inspecting the Dataset
print(dataset)
We verify our final judged dataset by first printing its summary.
Dataset({
features: ['image', 'question', 'answer', 'source', 'choice'],
num_rows: 85740
})
Here, we confirm that the dataset contains five fields (i.e., image, question, answer, source, and choice) and that it holds 85,740 rows in total, reflecting every image-question pair judged by Qwen.
Next, we inspect a single example:
print(dataset[0])
{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=640x424 at 0x7AC322D2D410>, 'question': 'What is happening in this image?', 'answer': 'carnival', 'source': 'blip', 'choice': 0}
This shows that the image field correctly loads a PIL image object, the question and answer strings match our expectations, and the metadata fields indicate that BLIP’s answer (“carnival”) was judged equal to or better than (choice = 0) PaliGemma’s output. These inspections confirm that our VLM-as-Judge pipeline produced a well-structured, ready-to-use synthetic VQA dataset.
Pushing the Dataset to the Hugging Face Hub
dataset.push_to_hub("cosmo3769/synthetic_vqa_dataset_21.4k_images_vlm_as_judge_qwen_2.5_vl_3b_instruct")
Finally, we call the push_to_hub method to share the newly created synthetic VQA dataset using the VLM-as-Judge methodology with the community.
The dataset can be found here.
What's next? We recommend PyImageSearch University.
86+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: April 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 86+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this 2nd lesson of our 2-part series, we completed the VLM-as-Judge pipeline by leveraging Qwen to compare and select the best answers generated by BLIP and PaliGemma. We walked through:
- Loading both sets of synthetic annotations from Part 1.
- Formatting a prompt that presents the image, question, and each model’s answer to Qwen.
- Running inference with Qwen to produce a binary decision — “0” if BLIP’s answer was better or equal, “1” if PaliGemma’s was superior.
- Aggregating Qwen’s judgments into a single JSON file and flattening it into a Hugging Face
Datasetwith fields for image, question, answer, source, and choice.
By the end of this tutorial, you will have a curated synthetic VQA dataset where each sample carries the highest-quality annotation and its provenance. Together, Parts 1 and 2 showcase a fully automated approach for scaling VQA dataset creation without manual labeling — using models not only to generate annotations but also to judge them.
Citation Information
Thakur, P. “Synthetic Data Generation Using the VLM-as-Judge Method,” PyImageSearch, P. Chugh, S. Huot, G. Kudriavtsev, and A. Sharma, eds., 2025, https://pyimg.co/inotz
@incollection{Thakur_2025_synthetic-data-generation-using-vlm-as-judge-method,
author = {Piyush Thakur},
title = {{Synthetic Data Generation Using the VLM-as-Judge Method}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Georgii Kudriavtsev and Aditya Sharma},
year = {2025},
url = {https://pyimg.co/inotz},
}
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.