Table of Contents
- Deploying a Vision Transformer Deep Learning Model with FastAPI in Python
- What Is FastAPI?
- Brief Overview of Vision Transformers
- Patch + Position Embedding
- Linear Projection of Flattened Patches
- Transformer Encoder
- Class Token and Final Classification
- Configuring Your Development Environment
- Project Directory Structure for Following Lessons
- Building and Running Your Vision Transformer API
- Testing the FastAPI Application with PyTest
- Summary
Deploying a Vision Transformer Deep Learning Model with FastAPI in Python
In this tutorial, we delve into the deployment of a Vision Transformer — a cutting-edge deep learning model — using FastAPI, a modern and fast web framework for building APIs. You’ll learn how to structure your project for efficient model serving, implement robust testing strategies with PyTest, and manage dependencies to ensure a smooth deployment process.

We’ll walk you through the entire setup, from initializing the FastAPI application to integrating your Vision Transformer model, providing detailed explanations along the way. By the end of this tutorial, you’ll be equipped with the knowledge to deploy advanced deep learning models, setting the stage for future enhancements in model serving and API development.
To learn how to effectively deploy a Vision Transformer model with FastAPI and perform inference via exposed APIs, just keep reading.
What Is FastAPI?
FastAPI is a modern web framework for building APIs with Python, designed to be both simple and highly performant. It’s built on top of Starlette for the web parts and Pydantic for the data parts, and it is designed to be easy to use, fast to develop with, and efficient at runtime.
One of the key strengths of FastAPI is its ability to generate automatic, interactive API documentation using OpenAPI and JSON Schema. This means that as you define your endpoints and data models, FastAPI automatically creates detailed, interactive documentation for your API, making it easier for developers and clients to understand and use your service.
Advantages of FastAPI
- High Performance: FastAPI is one of the fastest frameworks available, nearly as fast as Node.js and Go. This is crucial when deploying models that require quick response times (e.g., Vision Transformers for real-time image inference).
- Ease of Use: FastAPI is designed with the developer in mind, providing simple, intuitive syntax and reducing the boilerplate code required to build APIs.
- Automatic Validation: FastAPI leverages Python’s type hints to validate request data automatically, ensuring that your API endpoints only receive valid data, reducing errors and improving reliability.
- Scalability: With its asynchronous support, FastAPI can handle large volumes of requests efficiently, making it suitable for production-level applications that need to scale.
- Interactivity: FastAPI automatically generates interactive API documentation, allowing users to test endpoints directly from the browser, which is particularly useful for testing and debugging.
Positioning FastAPI Among Web Frameworks
To better understand where FastAPI fits in the landscape of web frameworks, consider this: it strikes a balance between the simplicity and speed of Flask and the robustness and scalability of Django. While Flask is lightweight and easy to get started with, it can become cumbersome as your project grows. Django, on the other hand, is highly scalable but comes with more complexity. FastAPI offers the best of both worlds — easy to develop with and scalable enough for large applications.
As its name implies, FastAPI offers a notable performance edge over Flask. Being an asynchronous framework, FastAPI can manage a higher number of requests per second compared to Flask. This makes it an ideal choice for applications that demand real-time updates and support a large number of concurrent connections.

This image illustrates how FastAPI combines the best attributes of both Flask and Django, making it an ideal choice for deploying machine learning models in production environments.
Brief Overview of Vision Transformers
Vision Transformers (ViTs) have emerged as a transformative architecture in the domain of computer vision, introduced by Dosovitskiy et al. in 2021 in their paper titled “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale.” Originally designed for natural language processing, Transformers excel at capturing long-range dependencies within data. When adapted for image analysis, Vision Transformers process an image by dividing it into patches, treating each patch as a sequence element, much like words in a sentence. This approach allows Vision Transformers to capture global contextual information across an image, making them particularly powerful for tasks (e.g., image classification, object detection, and segmentation).
The strength of Vision Transformers lies in their ability to model relationships between distant parts of an image, which traditional convolutional neural networks (CNNs) might struggle to capture. By deploying a Vision Transformer using FastAPI, we can leverage this cutting-edge model within a web-based application, enabling efficient and scalable image processing solutions.
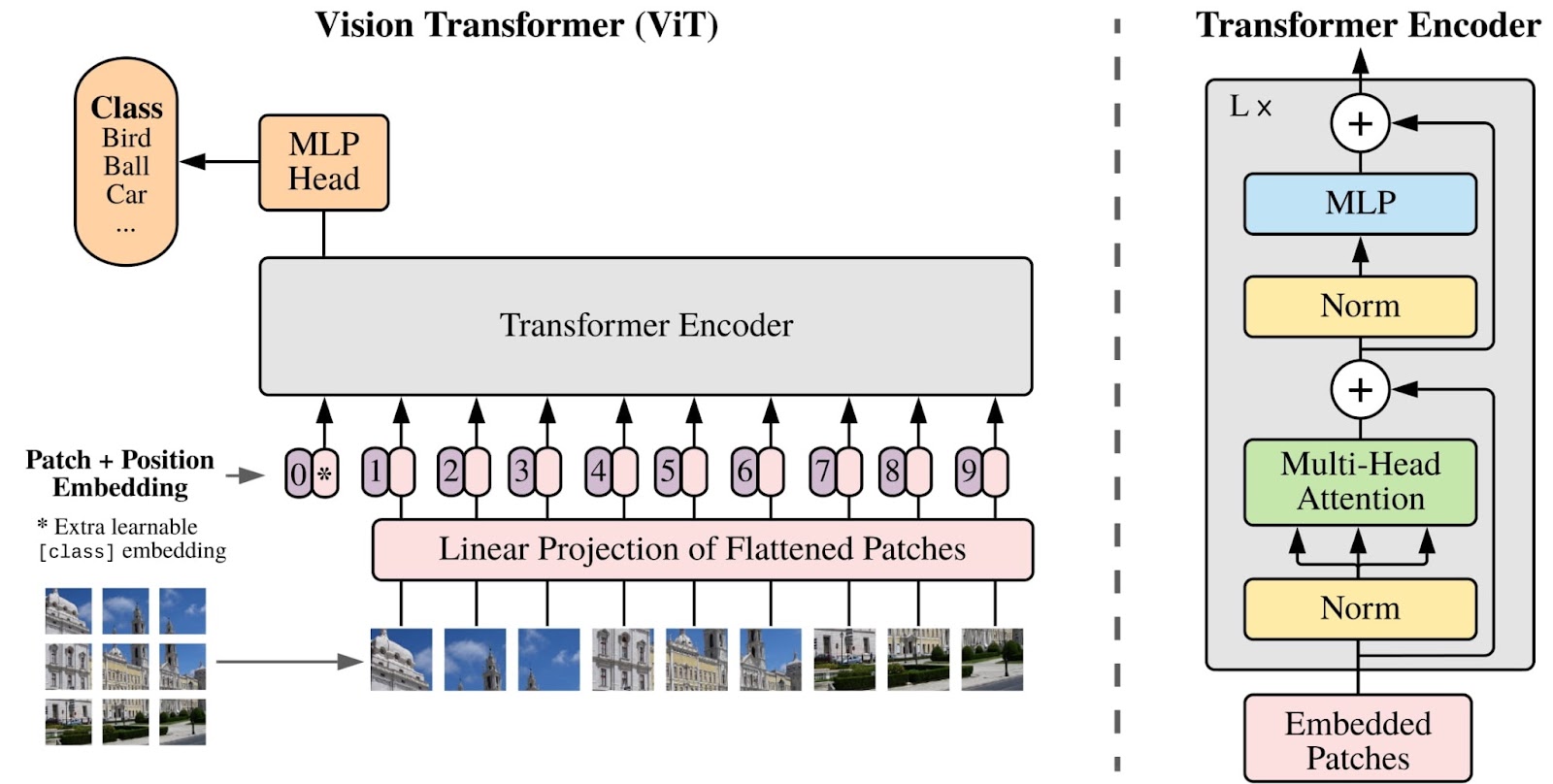
The image above illustrates the architecture of a Vision Transformer (ViT), as proposed by Dosovitskiy et al. The following is a breakdown of its components.
Patch + Position Embedding
The input image is divided into fixed-size patches. Each patch is then flattened and combined with a positional embedding, which encodes the position of the patch in the original image. This positional information is crucial because Transformers are inherently permutation-invariant, meaning they don’t inherently understand the spatial relationships between patches unless this information is explicitly provided.
Linear Projection of Flattened Patches
Each flattened patch is linearly projected into a lower-dimensional space, effectively converting each patch into a vector. This step ensures that the patches are represented in a format suitable for input into the Transformer encoder.
Transformer Encoder
- The core of the Vision Transformer, the Transformer Encoder, processes the sequence of patch embeddings. It consists of multiple layers of multi-head self-attention and feedforward neural networks. The encoder learns to capture complex relationships between patches, allowing the model to understand global patterns across the entire image.
- Multi-Head Attention: This mechanism enables the model to focus on different parts of the image simultaneously, capturing various aspects of the visual information. The attention mechanism helps in learning the relationships between different patches.
- Norm Layers and MLP Head: After the self-attention mechanism, normalization layers and a multi-layer perceptron (MLP) head are applied to refine the representations. The MLP head processes the final embedding to make predictions.
Class Token and Final Classification
A special [class] token is prepended to the sequence of patches, which aggregates the information from all patches. After passing through the Transformer encoder, this class token is used by the MLP head to make the final prediction (e.g., classifying the image as a bird, car, ball, etc.).
This architecture, proposed by Dosovitskiy et al., allows the Vision Transformer to excel in tasks that require an understanding of the entire image context, making it a powerful tool for various computer vision applications.
Note: While an in-depth understanding of Vision Transformers and the intricacies of training and fine-tuning the model are beyond the scope of this lesson, we are more than happy to dive deeper into these topics. If you’re interested, let us know, and we can create a dedicated series on Vision Transformers.
Without any further delay, let’s dive straight into deploying ViT with FastAPI.
Configuring Your Development Environment
To follow this guide, you’ll need to have several key libraries installed on your system, including FastAPI, Pillow, Gunicorn, PyTest, and Torch.
Fortunately, all these packages are easily installable via pip. You can use the following commands to set up your environment.
$ pip install -q fastapi[all]==0.98.0 $ pip install -q Pillow==9.5.0 $ pip install -q gunicorn==20.1.0 $ pip install -q pytest==8.2.2 $ pip install -q torch==2.4.0
Need Help Configuring Your Development Environment?

All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code immediately on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Project Directory Structure for Following Lessons
We first need to review our project directory structure.
Start by accessing the “Downloads” section of this tutorial to retrieve the source code and example images.
From there, take a look at the directory structure:
.
├── main.py
├── model.script.pt
├── pyimagesearch
│ ├── __init__.py
│ ├── config.py
│ └── utils.py
└── tests
├── test_image.png
├── test_main.py
└── test_utils.py
3 directories, 8 files
In the pyimagesearch directory, we have:
config.py: Contains configuration settings (e.g., file paths and model names). Centralizing configurations here allows easy adjustments without modifying the core application code.utils.py: Includes utility functions for tasks (e.g., loading the model, processing images, and performing inference). These functions keep the code modular, reusable, and organized.
In the root directory, we have:
main.py: This is the primary script for your FastAPI application. It sets up the FastAPI app, defines API endpoints, and handles incoming requests for inference and health check tasks.model.script.pt: This file contains the serialized (scripted) PyTorch model that is loaded for inference within the application.
In the tests directory, we have the following:
test_image.png: A sample image used for testing the inference capabilities of the model. It helps ensure that the model and API endpoints process image data as expected.test_main.py: Contains unit tests for the main application components, particularly the API endpoints defined inmain.py. This ensures that the endpoints work correctly and return the expected results.test_utils.py: Holds unit tests for the utility functions inutils.py. These tests validate that the helper functions are functioning as intended and that any changes to them do not introduce bugs into the application.
Building and Running Your Vision Transformer API
In this section, we’ll walk you through the process of setting up and deploying a Vision Transformer model using FastAPI. You’ll see how to structure your utilities, set up the FastAPI framework, and create a robust API for your model. This overview will provide the essential steps to get your application up and running, while keeping some implementation details exclusive to our PyImageSearch University subscribers.
Overview
In the utilities section, we focus on essential functions (e.g., loading the Vision Transformer model and defining the inference function). These utilities are critical for preparing and processing input data and generating predictions using the model. The following is a partial implementation of these functions.
import torch
from PIL import Image
# Load model
def load_model(model_path: str):
model = torch.jit.load(model_path)
return model.eval()
# Inference function (partial)
def predict(model, image_bytes: bytes):
img = Image.open(io.BytesIO(image_bytes))
img = img.convert("L")
img = img.resize((28, 28))
# Apply transformations (not shown)
img_t = get_transforms()(img).unsqueeze(0)
# Further steps to predict using the model...
# Full implementation available for subscribers.
We start by importing torch, which is the core library for PyTorch, and PIL.Image from the Pillow library, which helps in handling image files. torch is crucial for loading the Vision Transformer model that has been scripted and saved using the PyTorch just-in-time (JIT) compilation.
The load_model function is responsible for loading the pre-trained Vision Transformer model from a file. The model is loaded using torch.jit.load, which loads a JIT-compiled PyTorch model. The model is then set to evaluation mode using model.eval(), which ensures that layers like dropout are disabled during inference.
predict Function
- The
predictfunction handles the image preprocessing and prediction process. An image is read into memory usingImage.openand then converted to grayscale with.convert("L"). The image is resized to the required dimensions, and the function prepares the image for model input by applying a series of transformations (not shown in this snippet). Finally, the model processes the transformed image to produce predictions. - The full implementation of this function, including the application of transformations and the generation of predictions, is reserved for PyImageSearch University subscribers.
FastAPI Setup
This section demonstrates how to set up the FastAPI framework to serve your Vision Transformer model. You’ll see how to define API endpoints that will allow users to interact with your model via HTTP requests. The following is a partial implementation of the FastAPI setup.
from fastapi import FastAPI, File, UploadFile
from pyimagesearch.utils import load_model, predict
app = FastAPI()
# Load the model
model = load_model("path/to/model.script.pt")
# Define API endpoints
@app.post("/infer")
async def infer(image: UploadFile):
image_data = await image.read()
# Prediction logic (partial)
predictions = predict(model, image_data)
return predictions
@app.get("/health")
async def health():
return {"message": "ok"}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
We start by importing FastAPI and relevant utilities (e.g., File and UploadFile) to handle file uploads via the API. The load_model and predict functions from the utils.py module are also imported, which are used to load the model and perform inference.
We initialize a FastAPI application with app = FastAPI(). This object will serve as the core of our API, handling incoming requests and routing them to the appropriate endpoints.
The model is loaded at the start of the application using the load_model function. This ensures that the model is ready to handle requests as soon as the application starts.
API Endpoints
Two endpoints are defined:
infer: This POST endpoint receives an image file, processes it, and returns the model’s predictions. The full logic for handling predictions (e.g., data preprocessing and post-processing) is partially shown here. The complete implementation is available in our GitHub repository.health: A simple GET endpoint that returns a basic health check message to verify that the API is running.
The application is run using Uvicorn, a lightning-fast ASGI (Asynchronous Server Gateway Interface), making it ready to serve requests on the specified host and port.
Running the ViT Application
After setting up your FastAPI application and deploying the Vision Transformer model, the next step is to test the API to ensure it functions correctly. In this section, we’ll demonstrate how to test the API using Swagger UI and curl requests.
Testing the ViT Application via Swagger
Swagger UI is a built-in feature of FastAPI that automatically generates interactive API documentation based on your FastAPI app. This documentation allows you to interact with your API directly from the browser without needing any external tools. It provides a user-friendly interface where you can easily test your endpoints.
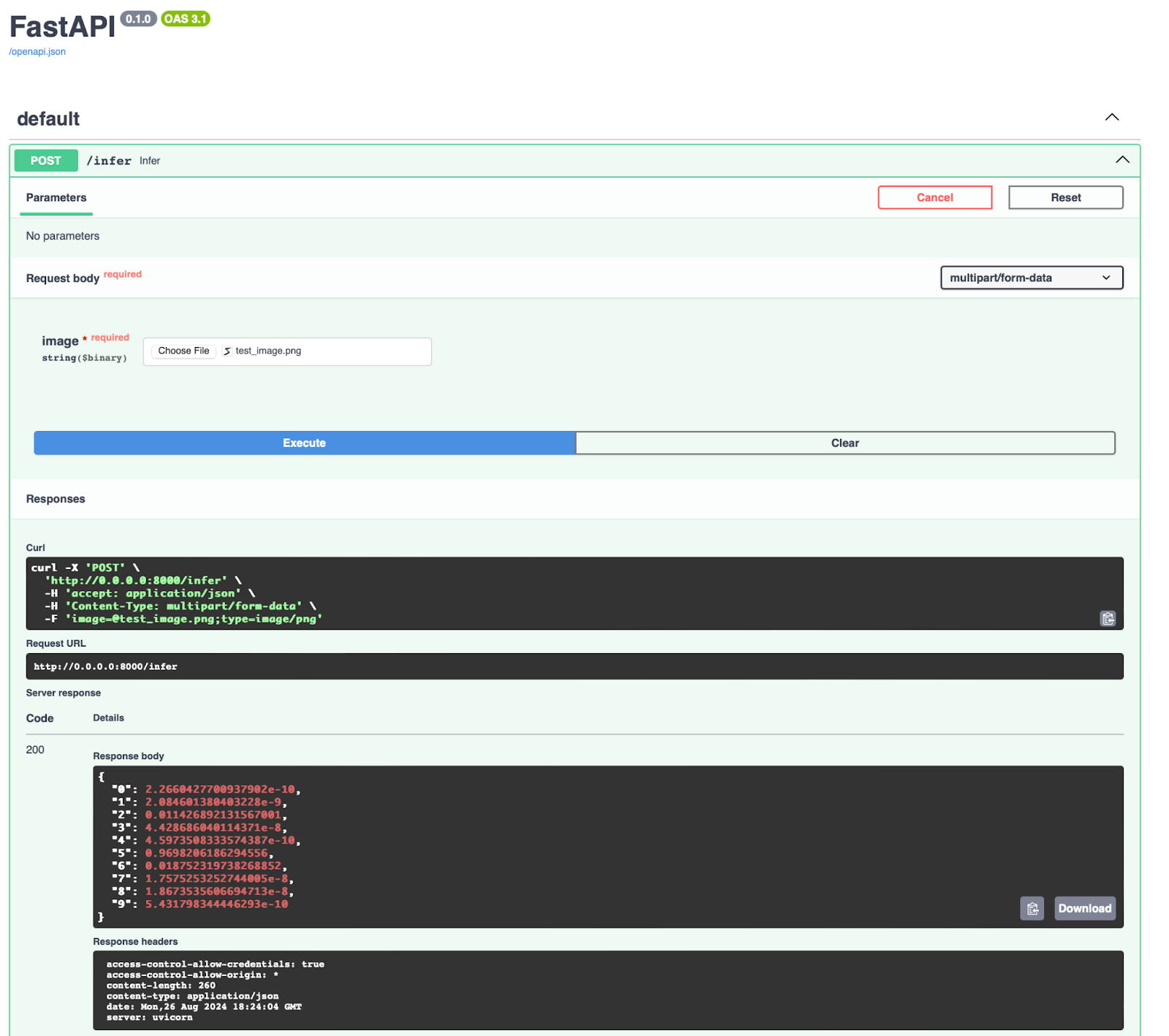
In the Swagger UI, you will see two available endpoints: /infer and /health. For testing, we’ve focused on the /infer endpoint.
Infer Endpoint
- The
/inferendpoint is designed to accept an image file as input and return a prediction based on the Vision Transformer model. - In the Swagger UI, you can easily upload an image using the provided interface. For this example, we’ve uploaded an image of the digit
5. - Upon executing the request, the API returns a JSON object with probabilities for each possible label (0-9). The highest probability corresponds to the label
5, with a confidence level of approximately97%, indicating that the model has correctly identified the digit.
Response
- The response includes a detailed breakdown of the probabilities for each class. This helps in understanding how confident the model is in its prediction.
- The returned probabilities are displayed in the response section, showing that the label
5has the highest probability, matching our expectations.
This method of testing is especially useful during development, as it allows you to quickly verify that your API is working as expected without needing to write additional client-side code.
Testing the ViT Application via curl
For those who prefer testing APIs from the command line, curl is an excellent tool. It allows you to send HTTP requests directly from your terminal. Here’s how you can test the /infer endpoint using curl.
Command Code
When the server is running on 0.0.0.0:8000, you can use the following curl command to send a POST request to the /infer endpoint:

The curl command shown here is used to test the /infer endpoint of your FastAPI application directly from the command line. It sends an image file to the server, and the server responds with a JSON object containing the model’s predictions. In this case, the highest probability is correctly assigned to the digit 5, demonstrating that the model is working as expected. This method is useful for quickly validating your API’s functionality in a straightforward, scriptable manner.
By testing your Vision Transformer application using Swagger and curl, you can ensure that your FastAPI is functioning correctly. These methods provide a comprehensive way to validate both the API endpoints and the underlying model predictions, ensuring that everything is working as intended before deploying the application to a production environment.
Testing the FastAPI Application with PyTest
PyTest is a powerful testing framework that allows developers to write simple yet scalable test cases for Python code. It’s highly regarded in the software development community for its ease of use and flexibility, making it a preferred choice for testing everything from individual functions to complex applications. By writing tests, you ensure that your application works as expected and can handle a variety of edge cases without failure.
Benefits of PyTest
- Simplicity: PyTest makes it easy to write small, readable test cases with a minimal boilerplate.
- Scalability: As your project grows, PyTest can scale with it, handling more complex test scenarios with ease.
- Comprehensive Reporting: PyTest provides detailed reports and logs, making it easier to identify and fix issues.
- Automatic Discovery: PyTest automatically discovers test files and test functions, simplifying the test execution process.
Testing utils.py
Here, we’ll write tests for the utility functions responsible for loading the model, applying transformations, and making predictions. This ensures that each component of your model pipeline works correctly.
import pytest
from pyimagesearch.utils import load_model
# Test model loading
def test_load_model():
model = load_model(MODEL_PATH)
assert model is not None
assert isinstance(model, torch.jit.ScriptModule)
# Test image transformations
def test_get_transforms():
transforms = get_transforms()
assert transforms is not None
# Test prediction function (partial)
def test_predict():
model = load_model(MODEL_PATH)
with open(TEST_IMAGE_PATH, "rb") as f:
image_bytes = f.read()
predictions = predict(model, image_bytes)
# Further validation steps and assertions (not shown)
The test_load_model test verifies that the model is successfully loaded from the specified path. It checks that the returned object is not None and is an instance of torch.jit.ScriptModule, ensuring the model is properly loaded for inference.
The test_get_transforms test ensures that the image transformation pipeline is correctly initialized. Although the actual transformation steps are hidden, this test validates the existence and readiness of the pipeline.
Finally, the test_predict test runs the prediction function on a test image, checking that predictions are generated correctly. The full validation logic and assertions are not shown here but are included in the full test suite available to our PyImageSearch University subscribers.
Testing main.py
Testing your FastAPI application’s endpoints is crucial to ensure that the API handles requests correctly and provides the expected responses. In this section, we’ll write comprehensive tests for both the health check and inference endpoints using PyTest.
import logging
import numpy as np
from fastapi.testclient import TestClient
from main import app
from pyimagesearch import config
client = TestClient(app)
TEST_IMAGE_PATH = config.test_image_path
def test_health():
logging.info("Testing /health endpoint")
response = client.get("/health")
logging.debug(f"Response status: {response.status_code}")
logging.debug(f"Response JSON: {response.json()}")
assert response.status_code == 200
assert response.json() == {"message": "ok"}
We import logging to help with logging important information during the test run. numpy is imported to handle numerical operations, particularly for processing the model’s output. TestClient from fastapi.testclient is used to create a test client that simulates requests to your FastAPI application.
The app object is imported from main.py to be used by TestClient, and config is imported to access configuration details (e.g., the path to the test image).
After importing the libraries and modules, we initialize the test client with client = TestClient(app), which will be used to send HTTP requests to the FastAPI application during the tests.
test_health Function
This test sends a GET request to the /health endpoint and logs the status code and response JSON. It asserts that the response status is 200 (OK) and that the response content matches the expected message {"message": "ok"}. This ensures that the health check endpoint is functioning correctly.
def test_infer():
logging.info("Testing /infer endpoint")
with open(TEST_IMAGE_PATH, "rb") as f:
response = client.post(
"/infer", files={"image": ("test_image.png", f, "image/png")}
)
logging.debug(f"Response status: {response.status_code}")
logging.debug(f"Response JSON: {response.json()}")
assert response.status_code == 200
assert isinstance(response.json(), dict)
# Extract probabilities from the JSON response
probabilities = response.json()
# Convert probabilities to a NumPy array and find the index with the highest probability
probabilities_array = np.array(list(probabilities.values()))
predicted_label = int(np.argmax(probabilities_array))
logging.info(f"Predicted label: {predicted_label}")
# Assuming you expect a specific label, you can check it like this
expected_label = 5 # Replace with the correct label you expect
assert (
predicted_label == expected_label
), f"Expected {expected_label}, but got {predicted_label}"
Next, we have the test_infer function:
- This test simulates a POST request to the
/inferendpoint, uploading a test image for prediction. - The test logs the status code and JSON response and checks that the response status is
200and that the response is a dictionary. - The probabilities returned by the model are extracted from the JSON response and converted into a NumPy array. The index with the highest probability is identified as the predicted label.
- The predicted label is logged, and an assertion checks if it matches the expected label. If the prediction is incorrect, the test will fail, indicating a potential issue with the model or its deployment.
PyTest Output Logs
This PyTest output provides a snapshot of the testing process for your FastAPI application. The tests were run in a Python 3.9 environment on macOS using PyTest 8.2.2. Five test cases were executed, including checks for the health endpoint and the inference functionality in the test_main.py file, as well as tests for model loading, image transformations, and predictions in test_utils.py.
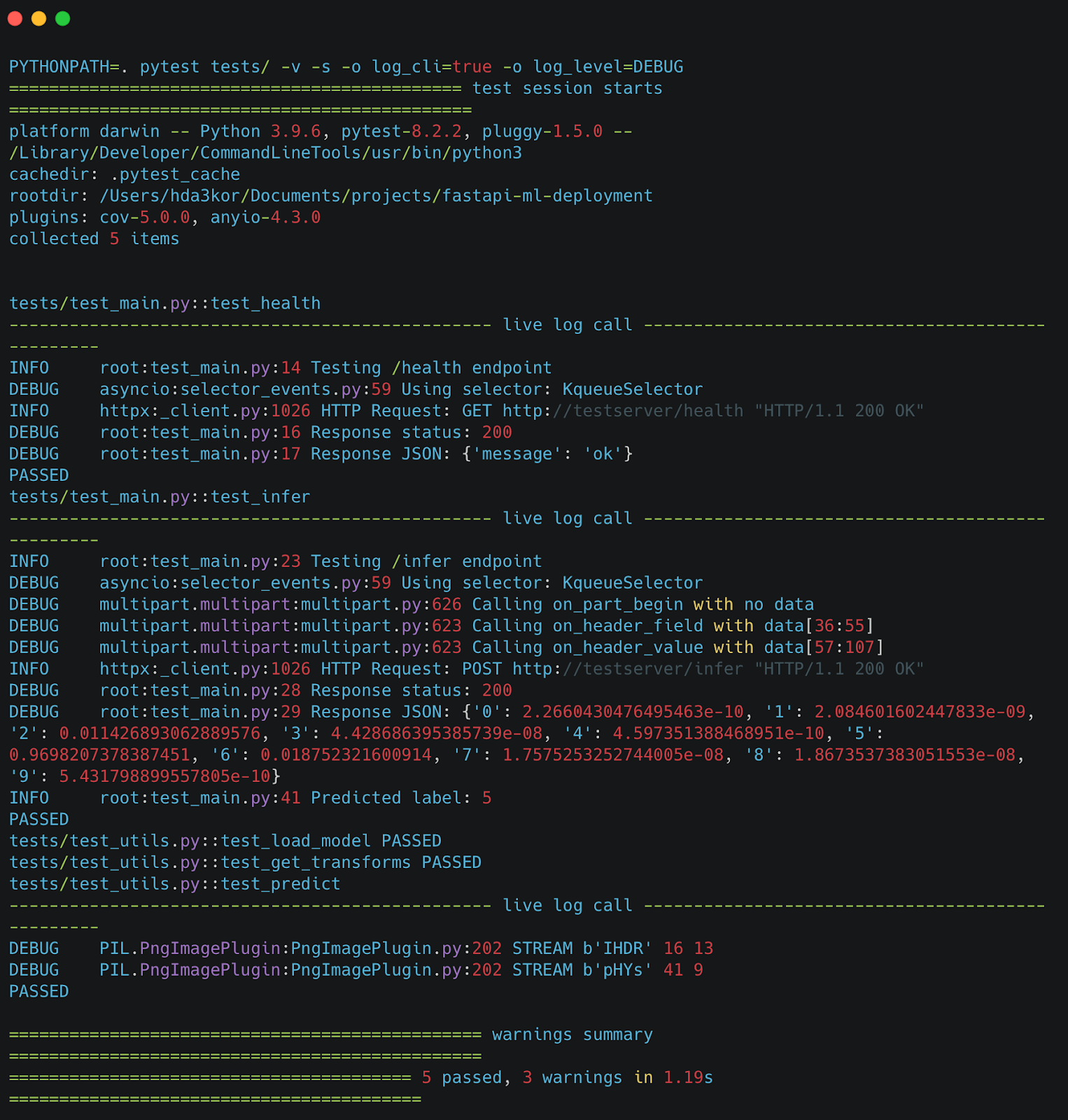
The output shows that all tests passed successfully, indicating that the API and utilities are functioning as expected. For each test, detailed logs are displayed, including HTTP requests and responses, which provide valuable insights during debugging. The logging level was set to DEBUG, allowing for a more granular view of the test execution (e.g., response statuses and predicted labels). The final summary confirms that all five tests passed, with a few warnings that were likely related to non-critical issues.
This output assures you that your API endpoints and utility functions are robust and ready for deployment, with the detailed logs helping to ensure that everything behaves as expected.
What's next? We recommend PyImageSearch University.

120+ total classes • 115+ hours hours of on-demand code walkthrough videos • Last updated: July 2026
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 120+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 94+ Certificates of Completion
- ✓ 115+ hours hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this tutorial, we explored the process of deploying a Vision Transformer (ViT) model using FastAPI, a modern and high-performance web framework. We began with an overview of FastAPI, highlighting its advantages (e.g., asynchronous support, automatic documentation, and robust performance). We also provided a brief introduction to Vision Transformers, explaining their architecture and why they are powerful for image-processing tasks.
Next, we delved into a code walkthrough where we set up the necessary utilities, including model loading and inference functions, followed by building the FastAPI application to serve the model. We demonstrated how to test the API endpoints using Swagger UI and curl commands, ensuring that the application responds correctly to requests and makes accurate predictions.
Finally, we covered how to validate the application’s functionality using PyTest, emphasizing the importance of testing in software development. By the end of this tutorial, you should have a solid understanding of how to deploy a Vision Transformer model with FastAPI, create API endpoints for model inference, and effectively test your application. This sets the stage for further enhancements (e.g., integrating Docker and CI/CD pipelines), which will be covered in future posts.
Citation Information
Sharma, A. “Deploying a Vision Transformer Deep Learning Model with FastAPI in Python,” PyImageSearch, P. Chugh, A. R. Gosthipaty, S. Huot, K. Kidriavsteva, and R. Raha, eds., 2024, https://pyimg.co/z9pkc
@incollection{Sharma_2024_Deploying-ViT-FastAPI,
author = {Aditya Sharma},
title = {Deploying a Vision Transformer Deep Learning Model with FastAPI in Python},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Aritra Roy Gosthipaty and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha},
year = {2024},
url = {https://pyimg.co/z9pkc},
}
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.